These days, if you're following the ML and specifically LLM communities, you're hearing a lot of people speak about RAG, or Retrieval-Augmented Generation. It's quite a big development indeed, with libraries such as langchain and llamaindex designed around its concepts. And what's more, it could be really useful to your company - allowing you to start using AI with your datasets, often without many of the privacy concerns or need for expensive fine-tuning!
But what is RAG? Why is it relevant in the first place? And how does it work at the three individual levels - Retrieval, Augmentation and Generation? That's what this article is about. It:
- Explains how RAG approaches can offset the downsides of plain LLMs, which are limits of prompt engineering and expensive fine-tuning.
- Discusses the high-level components of RAG followed by a slightly more detailed look at the individual components.
- Shows how a RAG approach can be beneficial to your LLM usage.
LLMs are pretrained on large corpora, but not on yours
Let's begin by looking at how LLMs are trained by using the GPT series (at least, the open source ones, being GPT-1 to GPT-3) as an example.
Those models took the original Transformer architecture by Vaswani et al. (2017), cut out the decoder and used an unsupervised pretraining objective (in GPT-1 followed by task-specific fine-tuning, but this was dropped in later models after people had realized that scaling up models could lead to such behavior with pretraining only).
GPT-1 was pretrained, then fine-tuned: "Our training procedure consists of two stages. The first stage is learning a high-capacity language model on a large corpus of text. This is followed by a fine-tuning stage, where we adapt the model to a discriminative task with labeled data" (Radford et al., 2018).
That is, the models were pretrained by:
- Taking a very large text corpus.
- Generating embeddings of textual tokens (either at character or word level).
- Using a context window of
Ntokens to model likelihood of finding tokenN+1givenNwith a neural network. In code terms, this means computing a Softmax activated output over all possible tokens, then computing cross-entropy loss followed by optimization (and then once more, another time, and so on).
Doing this has resulted in models that have quite a good understanding about the semantics of text. These days, there even are models which are multimodal and thus able to process more than text! All of these pretrained models have a downside: they were trained on large corpora of generic, non-task specific text. Even though they have quite good understanding, they were not trained on your data.
In-Context Learning is limited
One way to deal with this problem is via in-context learning or ICL. In fact, the prompt engineering technique is what was studied extensively by the authors of the GPT-3 paper (Brown et al., 2020). In a few-shot setting (giving a few examples), a one-shot setting (just one example) and a zero-shot setting (none) followed by the task, it was shown that ICL is really promising to let models behave in ways not present within the training data.
Here's a simple example:
Select the country from this text. Only return the name of the country.
Example text: I live in Austria.
Example output: Austria
Text to extract the country from: This bed was made in Germany.
Output:
Unfortunately, there are limits to simple, naïve ICL. Often, prompts cannot capture tasks sufficiently, either by means of poor prompting or insufficient model capability. In those settings, fine-tuning could be an interesting approach.
Fine-tuning can be prohibitively expensive
Recall from the GPT-1 paper (with the relatively small model) that fine-tuning was necessary to show task-specific behavior. Even though GPT-2, GPT-3 and (most likely) later versions have not been fine-tuned, it can still be a worthwhile approach to fine-tune your LLM!
For example, suppose that you have a large dataset of JSONs with sales data, such as this sales record:
{
"sales_record": [
{
"product_name": "Organic Avocado",
"category": "Food",
"price": 2.99,
"quantity": 10
},
{
"product_name": "Toothpaste",
"category": "Household",
"price": 3.99,
"quantity": 5
},
{
"product_name": "Canned Soup",
"category": "Food",
"price": 1.99,
"quantity": 15
}
]
}
You work with a health agency in a specific country, which has set standards of how healthy a food is. From a report, you've extracted healthiness scores and have converted them into texts. For example,
Canned Soup: 5/10
Organic Avocado: 9/10
Cheetos: 3/10
Now, in order to let the LLM generate a summary about whether new purchases are healthy, you cannot rely on its parameterized knowledge - which may not adhere to your country's standards. Hence, you create pairs of JSON inputs/Summarized outputs:
{ "product_name": "Organic Avocado" }
With output:
Organic avocados are healthy due to their high content of heart-healthy monounsaturated fats, essential vitamins, minerals, and fiber.
Subsequently, you take the LLM of choice, and start the fine-tuning process, which essentially learns that given a JSON the precise text must be modeled. That way, given any new combination of purchased items in a JSON, the model should become able to generate a health summary about the purchase.
Even though fine-tuning can work quite well, and even though the above usecase is quite a good reason for fine-tuning instead of ICL, it is also limited in the sense that:
- You alter the parameters of the LLM during fine-tuning. This means that by focusing on the specific task, the LLM may lose some of its more generic knowledge. In some cases, this is not what you want.
- Fine-tuning is quite expensive. Fortunately, there are approaches like LoRA which intelligently make fine-tuning a lot cheaper, but data preparation and subsequently training will still cost you money.
Enter Retrieval-Augmented Generation, or RAG
Let's now introduce RAG, which stands for Retrieval-Augmented Generation. It is essentially ICL on steroids, where people have started combining retrieval techniques with LLMs to harness your own datasets.
We endow pre-trained, parametric-memory generation models with a non-parametric memory through a general-purpose fine-tuning approach which we refer to as retrieval-augmented generation (RAG) (Lewis et al., 2020).
RAG at a high level
At a high level, RAG boils down to two processes - an offline and an online process.
In the offline process,
- Your dataset is loaded as documents, then divided into nodes by chunking (either by cutting the text into parts or more intelligently, e.g. hierarchically).
- Using embedding models, the chunks are converted into dense representations (Karpukhin et al., 2020), which put simply are vectors where each dimension plays a significant role in capturing text semantics (instead of sparse representations, such as bag-of-word vectors from older approaches).
- These dense representations are stored in an index, which is essentially a method for fast vector retrieval. Typically, this is done with a vector database, for which many offerings are available nowadays.
Also, in the offline process,
- It is possible to update your dataset by removing old documents (just removing the vectors), updating existing ones, or simply adding new ones.
- Multimodal approaches are becoming increasingly relevant. Typically by using multiple vector indices, image embedding and text embeddings are stored in a densely represented format, after which they can be used.
Then, in your online process,
- Any new prompt (sometimes thus even an image or text with image) is converted into the same dense representation with the same embedding model(s) before it is passed to the LLM.
- Using vector similarity between the prompt vector and content vectors already stored in your vector database, similar content is retrieved.
- In natural language format, this content is added to your prompt, as if it was relevant context for your prompt. Typically, libraries like
llamaindexuse battle tested prompts for adding this context, but you can also make your own. Also, it is possible to apply a variety of additional postprocessing techniques before appending the content (such as adding an extra window, or reranking the results) to make your RAG approach even more powerful. However, that is out of scope for this article. - The augmented prompt is passed to your LLM for generation.
- You retrieve a response from your LLM.
This way, your own datasets can be used (retrieved) to augment the generation of text by the LLM. In other words, RAG!
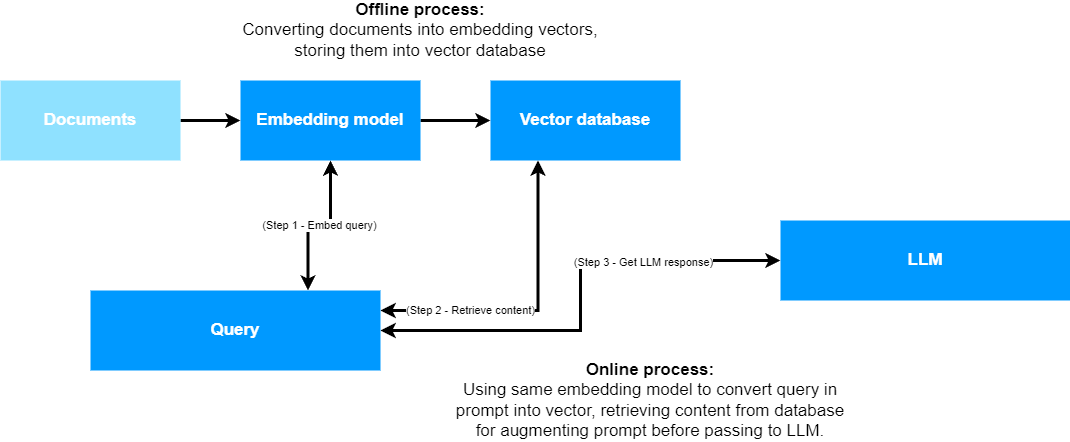
Let's now take a look at the individual components.
Retrieval: extracting relevant parts from your content
We're starting with retrieval, RAG's R. In a RAG pipeline, as discussed, retrieval has an offline and an online component.
Offline: building an index
Before you can retrieve anything, you must store it. And storing is typically done with a vector database.
A vector database is a type of database that indexes and stores vector embeddings for fast retrieval and similarity search, with capabilities like CRUD operations, metadata filtering, and horizontal scaling (Schwaber-Cohen, n.d.).
There are many vector databases out there, here is a non-exhaustive list:
-
Elasticsearch: While primarily known as a search engine, Elasticsearch can be used as a vector database thanks to its vector scoring capabilities. It's widely used for search and analytics.
-
Milvus: This is an open-source vector database designed for scalable similarity search and AI applications. It supports a variety of vector indexing and search algorithms.
-
Weaviate: Another open-source option, Weaviate is a vector search engine that supports GraphQL and RESTful APIs. It's designed for easy integration with machine learning models.
-
Pinecone: Pinecone is a vector database that's specialized for large-scale similarity search. It's designed for easy integration with machine learning and natural language processing applications.
-
Faiss by Facebook AI: Developed by Facebook AI Research, Faiss is a library for efficient similarity search and clustering of dense vectors. It's not a standalone database but is often used in conjunction with other databases for vector operations.
Vectors are a useful way of storing text, because they are capable of densely capturing the essence of a text without requiring a lot of space. That is, the essence can often be captured with 512 to 1024 dimensional vectors. What's more, because vectors can be compared, it becomes possible to comparing texts for similarity - if vectors are alike, texts must be, too.
But how do you make sure that similar texts lead to similar vectors?
That is where embedding models enter the picture.
Embedding is the process of creating vectors using deep learning. An "embedding" is the output of this process — in other words, the vector that is created by a deep learning model for the purpose of similarity searches by that model (CloudFlare, n.d.).
Such embedding models take some text and convert it into a dense representation - a lot of numbers which are a representation of your text. If an embedding model is trained well, texts with similar meaning will produce vectors that are similar, and which can be used in the online component of RAG's retrieval phase.
There are a lot of options for making embeddings by using pretrained embedding models:
- Using OpenAI's or Cohere's embedding APIs or those of a different provider.
- BAAI's BGE embedding model.
- And many others!
Everything combined together, it's possible to build an index of your documents by
- Loading the texts, splitting them in chunks of similar length.
- Passing the texts through the embedding model.
- Storing the obtained vector in a database for similarity search.
Online: retrieving from your index
Let's now move to the online part of RAG's R: retrieving content similar to your query.
Recall that you have used embedding models to convert your input data into vector format and that vectors with similar meaning are similar.
So, why not use the same embedding model to convert your prompt into vectorized format?
That way, using the vector for your prompt, it's possible to retrieve semantically similar content from your dataset by performing similarity search between the vectors in your database and that of your prompt.
Typically, the top n similar chunks is retrieved. This can be done by comparing vectors, e.g. using cosine similarity (or a more refined approach implemented within your vector database). Also, often, using a variety of postprocessing techniques (such as reranking), these chunks are refined further into a top k of most relevant chunks.
Augmented: combining the content with your prompt
Let's briefly recap what we have right now:
- We have a database filled with vectors that were generated using an embedding model using some text chunk from your dataset.
- We have an embedding vector generated for your prompt.
- Using both, we have retrieved and refined a set of documents into a top
krelevant chunks. - For the relevant chunks, we have retrieved their original natural language variants.
Now, it's time to actually augment your text!
Here is an example way of doing that (GitHub, n.d.):
- You instruct the LLM that you're providing context, which you then provide.
- You then task the LLM with answering the query with only the context, not with its parameterized knowledge.
- You then state the query.
- And signal that the LLM can now start answering it.
That's it! You now have an augmented prompt with content from your dataset.
"Context information is below.\n"
"---------------------\n"
"{context_str}\n"
"---------------------\n"
"Given the context information and not prior knowledge, "
"answer the query.\n"
"Query: {query_str}\n"
"Answer: "
Generation: letting the LLM generate new outputs
RAG's G, generation, is actually quite simple: you feed the prompt to the model and await its response.
Typically, the response contains the answer to your question extracted from your dataset. If you're at this stage, it's time to move to RAG evaluation, but that's out of scope for this article.
Benefits of RAG approaches
There are multiple benefits to using RAG approaches with LLMs:
- Letting LLMs use your datasets when generating responses.
- Keeping the LLM up to date with respect to events more recent than the training data cutoff.
- If set up in specific ways, enjoying multimodality added to your textual LLMs.
There's also a cautionary note - which is related to privacy. It's not a problem in many cases, but you'll have to think about it all the time when building a RAG pipeline.
Let's now take a look at these in more detail.
Letting LLMs use your datasets
First of all, we've seen that RAG augments prompts with relevant chunks from your own datasets before sending them off to the LLM. In other words, RAG is a way to harness the richness of your own datasets without the need for expensive model fine-tuning. In fact, it's even possible to use open source LLMs (but also GPT) as the generative model so you don't have to worry about it.
Keeping the LLM up-to-date
A different benefit of RAG is that it allows you to keep your LLM up-to-date. Each LLM has a cutoff date in terms of training data, meaning that more recent events are not present in its parameterized knowledge. Given how expensive training is, it's also difficult to add such knowledge into the LLM. That's where RAG comes in. It allows you to build a non-parameterized dataset of recent events, such as news articles, which you can then use to augment your prompt.
Here's an example:
You: What happened to the Rhine river in December 2023?
If you'd feed that to ChatGPT 3.5 without providing any context, you'd get this, which is expected:
ChatGPT: I'm sorry, but I do not have access to real-time information or events that occurred after my last knowledge update in January 2022. I recommend checking the latest news or reliable sources for information on what happened to the Rhine River in December 2023. If you have any other questions or need information within my knowledge range, please feel free to ask.
Now, if you had read Pascoe (2023), you would know that high water levels caused a variety of (noncritical) problems in parts of Germany and the Netherlands.
Suppose that your RAG approach would identify these chunks from that article out of your vector database:
Chunk 1: Water levels in the big Dutch rivers are set to reach their highest level on Thursday, following weeks of heavy rain plus severe weather in Germany.
Chunk 2: At just after 4 am, the level in the river Rhine at Lobith, at the border with Germany, reached 14.52 metres above NAP but has now sunk slightly, officials said.
Chunk 3: There has been some localised flooding along the Waal and the IJssel where sandbags are being used to keep the water at bay. In Deventer, where the flood risk is most acute, the river banks have been raised 10 centimetres with hundreds of sandbags.
Now, use that to augment your prompt and feed this to ChatGPT 3.5 with the same question:
Context information is below.
**
Water levels in the big Dutch rivers are set to reach their highest level on Thursday, following weeks of heavy rain plus severe weather in Germany.
At just after 4 am, the level in the river Rhine at Lobith, at the border with Germany, reached 14.52 metres above NAP but has now sunk slightly, officials said.
There has been some localised flooding along the Waal and the IJssel where sandbags are being used to keep the water at bay. In Deventer, where the flood risk is most acute, the river banks have been raised 10 centimetres with hundreds of sandbags.
**
Query: What happened to the Rhine river in December 2023?
Answer:
Here's what you would get:
ChatGPT: In December 2023, the Rhine river in the Netherlands experienced rising water levels due to weeks of heavy rain and severe weather in Germany. At one point, the water level in the river Rhine at Lobith, at the border with Germany, reached 14.52 meters above NAP (Amsterdam Ordnance Datum), but it had slightly receded afterward. This led to localized flooding along the Waal and the IJssel rivers, where sandbags were used to mitigate the flood risk. Additionally, in Deventer, where the flood risk was most acute, the river banks were raised by 10 centimeters with the help of hundreds of sandbags to protect the area from flooding.
Adding multimodality to your textual LLMs
Another interesting use case and hence benefit of RAG is that multimodality can be added to your textual LLMs.
Suppose that you are using an open source LLM, such as Mistral 7B, for pun generation. Your setup is as follows:
- An image is uploaded and the prompt 'What is visible in the image? A banana, an orange of a jackfruit? Tell me a pun about that particular fruit.' is applied.
Now, that's quite a simple scenario, but it will do for this example, as Mistral 7B would not be able to handle that out of the box - it doesn't get images.
Using CLIP, you would be able to zero-shot classify an image into one of the three classes - banana, orange or jackfruit. Then, the result can be passed into the prompt, while the LLM will be able to produce the pun.
One cautionary note: privacy is dependent on LLM choice
The benefits above give you a clear overview as to why RAG can be beneficial to your LLM use. Packages like llamaindex and langchain are designed around these principles, and using them is easy. Maybe too easy, because it's always important to keep privacy in mind.
For example, when using llamaindex, OpenAI APIs are used as default LLMs in many cases. While they work quite well, they come at the cost of potentially losing control over data ownership. This can be problematic (and even illegal) when it comes to privacy. Hence, when building a RAG pipeline, always think twice about what you are doing - and then continue building!
References
Radford, A., Narasimhan, K., Salimans, T., & Sutskever, I. (2018). Improving language understanding by generative pre-training.
Radford, A., Wu, J., Child, R., Luan, D., Amodei, D., & Sutskever, I. (2019). Language models are unsupervised multitask learners. OpenAI blog, 1(8), 9.
Brown, T., Mann, B., Ryder, N., Subbiah, M., Kaplan, J. D., Dhariwal, P., ... & Amodei, D. (2020). Language models are few-shot learners. Advances in neural information processing systems, 33, 1877-1901.
Karpukhin, V., Oğuz, B., Min, S., Lewis, P., Wu, L., Edunov, S., ... & Yih, W. T. (2020). Dense passage retrieval for open-domain question answering. arXiv preprint arXiv:2004.04906.
GitHub. (n.d.). Llama_index/docs/examples/prompts/prompt_mixin.ipynb at main · run-llama/llama_index. https://github.com/run-llama/llama_index/blob/main/docs/examples/prompts/prompt_mixin.ipynb
Pascoe, R. (2023, December 28). Dutch river water levels reach peak as flood risk continues. DutchNews.nl. https://www.dutchnews.nl/2023/12/dutch-river-water-levels-reach-peak-as-flood-risk-continues/
Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A. N., ... & Polosukhin, I. (2017). Attention is all you need. Advances in neural information processing systems, 30.
Lewis, P., Perez, E., Piktus, A., Petroni, F., Karpukhin, V., Goyal, N., ... & Kiela, D. (2020). Retrieval-augmented generation for knowledge-intensive NLP tasks. Advances in Neural Information Processing Systems, 33, 9459-9474.
Schwaber-Cohen, R. (n.d.). What is a vector database & how does it work? Use cases + examples. Vector Database for Vector Search | Pinecone. https://www.pinecone.io/learn/vector-database/
CloudFlare. (n.d.). What are embeddings in machine learning?. Cloudflare - The Web Performance & Security Company | Cloudflare. https://www.cloudflare.com/learning/ai/what-are-embeddings/

Hi, I'm Chris!
I know a thing or two about AI and machine learning. Welcome to MachineCurve.com, where machine learning is explained in gentle terms.
Getting started
Foundation models
Learn how large language models and other foundation models are working and how you can train open source ones yourself.
Keras
Keras is a high-level API for TensorFlow. It is one of the most popular deep learning frameworks.
Machine learning theory
Read about the fundamentals of machine learning, deep learning and artificial intelligence.
Most recent articles
January 2, 2024
What is Retrieval-Augmented Generation?
December 27, 2023
In-Context Learning: what it is and how it works
December 22, 2023
CLIP: how it works, how it's trained and how to use it
Article tags
Most popular articles
February 18, 2020
How to use K-fold Cross Validation with TensorFlow 2 and Keras?
December 28, 2020
Introduction to Transformers in Machine Learning
December 27, 2021
StyleGAN, a step-by-step introduction
July 17, 2019
This Person Does Not Exist - how does it work?
October 26, 2020
Your First Machine Learning Project with TensorFlow 2.0 and Keras
Connect on social media
Connect with me on LinkedIn
To get in touch with me, please connect with me on LinkedIn. Make sure to write me a message saying hi!
Side info
The content on this website is written for educational purposes. In writing the articles, I have attempted to be as correct and precise as possible. Should you find any errors, please let me know by creating an issue or pull request in this GitHub repository.
All text on this website written by me is copyrighted and may not be used without prior permission. Creating citations using content from this website is allowed if a reference is added, including an URL reference to the referenced article.
If you have any questions or remarks, feel free to get in touch.
TensorFlow, the TensorFlow logo and any related marks are trademarks of Google Inc.
PyTorch, the PyTorch logo and any related marks are trademarks of The Linux Foundation.
Montserrat and Source Sans are fonts licensed under the SIL Open Font License version 1.1.
Mathjax is licensed under the Apache License, Version 2.0.