Deep neural networks are widely used to solve computer vision problems. Frequently, their performance is much better compared to Multilayer Perceptrons, which - as we shall see - is not too surprising. In this article, we will focus on building a ConvNet with the PyTorch library for deep learning.
After reading it, you will understand...
- How Convolutional Neural Networks work
- Why ConvNets are better than MLPs for image problems
- How to code a CNN with PyTorch
Let's take a look! :)
How ConvNets are used for Computer Vision
If you are new to the world of neural networks, you will likely see such networks being displayed as a set of connected neurons:
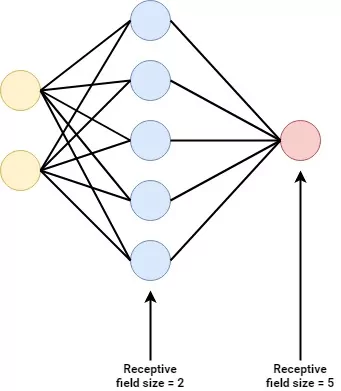
These networks are called Multilayer Perceptrons, or MLPs for short. They take some input data, pass them through (a set of) layers in a forward fashion, and then generate a prediction in some output layer.
With MLPs, a variety of problems can be solved - including computer vision problems. But this does not mean that they are the best tool for the job. Rather, it is more likely that you will be using a Convolutional Neural Network - which looks as follows:
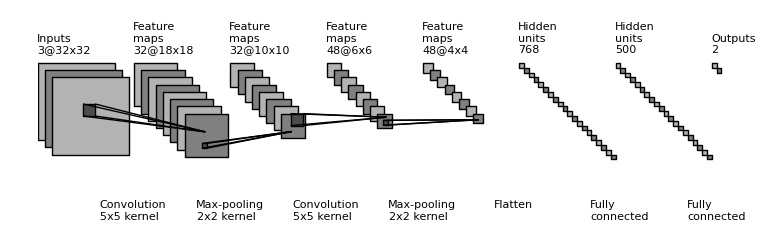
Source: gwding/draw_convnet
We'll now briefly cover the inner workings of such a network, and why it can be a better tool for image problems. We don't cover this topic extensively, because this article focuses on building a ConvNet with PyTorch. If you wish to understand ConvNets in more detail, we'd love to point you to these articles:
- Convolutional Neural Networks and their components for computer vision
- How to build a ConvNet for CIFAR-10 and CIFAR-100 classification with Keras?
A ConvNet, structured
Let's now take a look at the image above. We begin on the right, where you'll see an Outputs layer with two outputs. Apparently, that network generates two types of predictions (for example, it can be a multiclass network with two classes, or it can give two regression outputs).
Left of this layer, we can see two layers with Hidden units. These are called Fully connected. Indeed, they are the type of layer that we know from a Multilayer Perceptron! In other words, a Convolutional Neural Network often includes a MLP for generating the predictions. But then what makes such a network Convolutional?
The presence of Convolutional layers (hello, captain obvious).
On the left, we can see so-called Convolution layers followed by (Max) pooling layers. A convolution can be defined as follows:
In mathematics (in particular, functional analysis), convolution is a mathematical operation on two functions (f and g) that produces a third function ({\displaystyle f*g}
) that expresses how the shape of one is modified by the other.
Wikipedia (2001)
In other words, a Convolutional layer combines two parts and generates a function that expresses how one alters the other. Recall, if you are familiar with neural networks, that they have inputs which are fed through a layer that has weights. If you take a look at this from a Convolution perspective, such a layer will have weights - and it evaluates how much inputs "alter", or "trigger" these weights.
Then, by adapting the weights during optimization, we can teach the network to be "triggered" by certain patterns present in the input data. Indeed, such layers can be taught to be triggered by certain parts that are present in some input data, such as a nose, and relate it to e.g. output class "human" (when seen from the whoel network).
Since Convnets work with a kernel that is slided over the input data, they are said to be translation invariant - meaning that a nose can be detected regardless of size and position within the image. It is why ConvNets are way more powerful for computer vision problems than classic MLPs.
Code example: simple Convolutional Neural Network with PyTorch
Now that we have recalled how ConvNets work, it's time to actually build one with PyTorch. Next, you will see a full example of a simple Convolutional Neural Network. From beginning to end, you will see that the following happens:
- The imports. First of all, we're importing all the dependencies that are necessary for this example. For loading the dataset, which is
MNIST, we'll need the operating system functionalities provided by Python - i.e.,os. We'll also need PyTorch (torch) and its neural networks library (nn). Using theDataLoaderwe can load the dataset, which we can transform into Tensor format withtransforms- as we will see later. - The neural network Module definition. In Pytorch, neural networks are constructed as
nn.Moduleinstances - or neural network modules. In this case, we specify aclasscalledConvNet, which extends thenn.Moduleclass. In its constructor, we pass some data to the super class, and define aSequentialset of layers. This set of layers means that a variety of neural network layers is stacked on top of each other. - The layers. Recall from the image above that the first layers are Convolutional in nature, followed by MLP layers. For two-dimensional inputs, such as images, Convolutional layers are represented in PyTorch as
nn.Conv2d. Recall that all layers require an activation function, and in this case we use Rectified Linear Unit (ReLU). The multidimensional output of the final Conv layer is flattened into one-dimensional inputs for the MLP layers, which are represented byLinearlayers. - Layer inputs and outputs. All Python layers represent the number of in_channels and the number of out_channels in their first two arguments, if applicable. For our example, this means that:
- The first
Conv2dlayer has one input channel (which makes sence, since MNIST data is grayscale and hence has one input channel) and provides ten output channels. - The second
Conv2dlayer takes these ten output channels and outputs five. - As the MNIST dataset has 28 x 28 pixel images, two
Conv2dlayers with a kernel size of 3 produce feature maps of 24 x 24 pixels each. This is why after flattening, our number of inputs will be24 * 24 * 5- 24 x 24 pixels with 5 channels from the Conv layer. 64 outputs are specified. - The next Linear layer has 64 inputs and 32 outputs.
- Finally, the 32 inputs are converted into 10 outputs. This also makes sence, since MNIST has ten classes (the numbers 0 to 9). Our loss function will be able to handle this format.
- The first
- Forward definition. In the
forwarddef, the forward pass of the data through the network is performed. - The operational aspects. Under the
maincheck, the random seed is fixed, the data is loaded and preprocessed, the ConvNet, loss function and optimizer are initialized and the training loop is performed. In the training loop, batches of data are passed through the network, after the loss is computed and the error is backpropagated, after which the network weights are adapted during optimization.
import os
import torch
from torch import nn
from torchvision.datasets import MNIST
from torch.utils.data import DataLoader
from torchvision import transforms
class ConvNet(nn.Module):
'''
Simple Convolutional Neural Network
'''
def __init__(self):
super().__init__()
self.layers = nn.Sequential(
nn.Conv2d(1, 10, kernel_size=3),
nn.ReLU(),
nn.Conv2d(10, 5, kernel_size=3),
nn.ReLU(),
nn.Flatten(),
nn.Linear(24 * 24 * 5, 64),
nn.ReLU(),
nn.Linear(64, 32),
nn.ReLU(),
nn.Linear(32, 10)
)
def forward(self, x):
'''Forward pass'''
return self.layers(x)
if __name__ == '__main__':
# Set fixed random number seed
torch.manual_seed(42)
# Prepare CIFAR-10 dataset
dataset = MNIST(os.getcwd(), download=True, transform=transforms.ToTensor())
trainloader = torch.utils.data.DataLoader(dataset, batch_size=10, shuffle=True, num_workers=1)
# Initialize the ConvNet
convnet = ConvNet()
# Define the loss function and optimizer
loss_function = nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(convnet.parameters(), lr=1e-4)
# Run the training loop
for epoch in range(0, 5): # 5 epochs at maximum
# Print epoch
print(f'Starting epoch {epoch+1}')
# Set current loss value
current_loss = 0.0
# Iterate over the DataLoader for training data
for i, data in enumerate(trainloader, 0):
# Get inputs
inputs, targets = data
# Zero the gradients
optimizer.zero_grad()
# Perform forward pass
outputs = convnet(inputs)
# Compute loss
loss = loss_function(outputs, targets)
# Perform backward pass
loss.backward()
# Perform optimization
optimizer.step()
# Print statistics
current_loss += loss.item()
if i % 500 == 499:
print('Loss after mini-batch %5d: %.3f' %
(i + 1, current_loss / 500))
current_loss = 0.0
# Process is complete.
print('Training process has finished.')
Sources
- gwding/draw_convnet
- Wikipedia. (2001, December 20). Convolution. Wikipedia, the free encyclopedia. Retrieved July 8, 2021, from https://en.wikipedia.org/wiki/Convolution
- PyTorch. (n.d.). Conv2d — PyTorch 1.9.0 documentation. https://pytorch.org/docs/stable/generated/torch.nn.Conv2d.html

Hi, I'm Chris!
I know a thing or two about AI and machine learning. Welcome to MachineCurve.com, where machine learning is explained in gentle terms.
Getting started
Foundation models
Learn how large language models and other foundation models are working and how you can train open source ones yourself.
Keras
Keras is a high-level API for TensorFlow. It is one of the most popular deep learning frameworks.
Machine learning theory
Read about the fundamentals of machine learning, deep learning and artificial intelligence.
Most recent articles
January 2, 2024
What is Retrieval-Augmented Generation?
December 27, 2023
In-Context Learning: what it is and how it works
December 22, 2023
CLIP: how it works, how it's trained and how to use it
Article tags
Most popular articles
February 18, 2020
How to use K-fold Cross Validation with TensorFlow 2 and Keras?
December 28, 2020
Introduction to Transformers in Machine Learning
December 27, 2021
StyleGAN, a step-by-step introduction
July 17, 2019
This Person Does Not Exist - how does it work?
October 26, 2020
Your First Machine Learning Project with TensorFlow 2.0 and Keras
Connect on social media
Connect with me on LinkedIn
To get in touch with me, please connect with me on LinkedIn. Make sure to write me a message saying hi!
Side info
The content on this website is written for educational purposes. In writing the articles, I have attempted to be as correct and precise as possible. Should you find any errors, please let me know by creating an issue or pull request in this GitHub repository.
All text on this website written by me is copyrighted and may not be used without prior permission. Creating citations using content from this website is allowed if a reference is added, including an URL reference to the referenced article.
If you have any questions or remarks, feel free to get in touch.
TensorFlow, the TensorFlow logo and any related marks are trademarks of Google Inc.
PyTorch, the PyTorch logo and any related marks are trademarks of The Linux Foundation.
Montserrat and Source Sans are fonts licensed under the SIL Open Font License version 1.1.
Mathjax is licensed under the Apache License, Version 2.0.