The class of Generative Adversarial Network models, or GANs, belongs to the toolbox of any advanced Deep Learning engineer these days. First proposed in 2014, GANs can be used for a wide variety of generative applications - but primarily and most significantly the generation of images and videos.
But as with any innovation in neural networks, the original propositions almost never scale well. The same is true for GANs: vanilla GANs suffer from instability during training. And that does not benefit the quality of the images that are generated.
In this article, we're going to take a look at the Deep Convolutional GAN or DCGAN family of GAN architectures. Proposed by Radford et al. (2015) after analyzing a wide variety of architectural choices, DCGANs apply a set of best practices that make training more stable and efficient. The primary difference compared to vanilla GANs is the usage of Convolutional layers, and the possibility to do so in a stable way.
By reading it, you will learn...
- That GANs can be used for feature extraction.
- How DCGANs make training GANs more stable, and primarily use Conv instead of Dense layers.
- A set of best practices for training your GAN compared to a vanilla GAN.
Let's take a look! 🚀
Conv-based GANs and stability problems
Generative Adversarial Networks or GANs have been around in the Generative Deep Learning field since the 2014 paper by Ian Goodfellow and others. As we know from our introduction article on GANs, they are composed of two models. The first, the generator, is responsible for generating fake images that cannot be distinguished from real ones. In other words, for counterfeiting.
The second, however, is the police - and its job is to successfully detect when images presented to it are fake.
Using GANs for feature extraction
The reason why Radford et al. (2015) were so interested in Generative Adversarial Networks in the first place was not because of their generative capabilities. Rather, GANs can also be used as feature extractors. Feature extraction, here, involves constructing a set of features that are more abstract but also informative about the features they were based on. In other words, it involves dimensionality reduction.
Interestingly, parts of the Generator and the Discriminator of a GAN can be reused "as feature extractors for supervised tasks" (Radford et al., 2015). They hence become an interesting alternative to other approaches such as classic Convolutional Neural Networks.
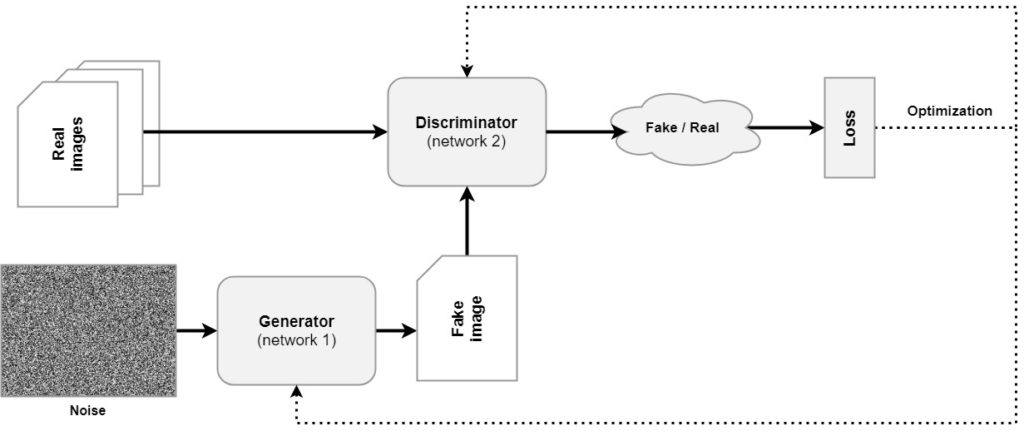
The vanilla GAN proposed by Goodfellow et al. (2014) was however composed of densely-connected layers, a.k.a. Dense layers. This was natural for the time: AlexNet was only two years old and ConvNets were only slowly but surely overtaking 'classic' MLP-like neural networks.
Today, we know that when it comes to computer vision tasks, Dense layers are suboptimal compared to convolutional (a.k.a. Conv) layers. This is because the latter serve as trainable feature extractors. Rather than "showing the entire picture to each layer" (which is what happens when you use Dense layers), a Conv layer feeds only parts of the image to a set of neurons.
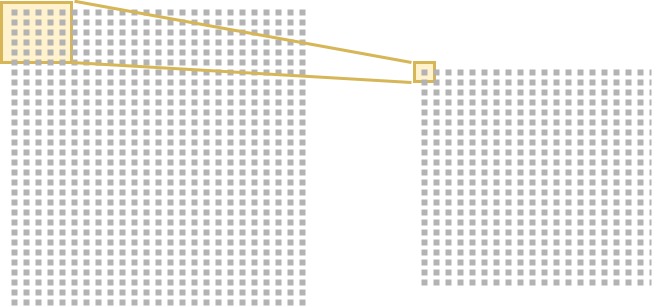
Finding significant performance improvements in regular classification tasks, Conv layers can also improve GAN performance.
Stability
GANs already showed great potential in the 2014 paper, they weren't perfect (and they still are not perfect today). While adding Conv layers is good option for improving the performance of a GAN, problems emerged related to stability (Radford et al., 2015).
And that's not good if we want to use them in practice. Let's take a look at what can be done to make Conv based GANS more stable according to the best practices found in the Radford et al. (2015) paper.
Some best practices - introducing DCGANs
Radford et al. (2015), in their paper "Unsupervised representation learning with deep convolutional generative adversarial networks", explored possibilities for using convolutional layers in GANs to make them suitable as feature extractors for other vision approaches.
After "extensive model exploration" they identified "a family of architectures [resulting] in stable training across a range of datasets [, allowing for] higher resolution and deeper (...) models" (Radford et al, 2015). This family of architectures is named DCGAN, or Deep Convolutional GANs.
When converted into best practices, this is a list that when used should improve any GAN compared to vanilla ones from the early days:
- Minimizing fully connected layers: Remove fully connected hidden layers for deeper architectures, relying on Global Average Pooling instead. If you cannot do that, make sure to add Dense layers only to the input of the Generator and the output of the Discriminator.
- The first layer of the Generator must be a Dense layer because it must be able to take samples from the latent distribution \(Z\) as its input.
- The final layer of the Discriminator must be a Dense layer because it must be able to convert inputs to a probability value.
- Allowing the network to learn its own downsampling and upsampling. This is achieved through replacing deterministic pooling functions (like max pooling) with strided convolutions in the Discriminator and fractional-strided convolutions in the Generator.
- Applying Batch Normalization. Ensuring that the data distributions within each layer remain in check means that the weights updates oscillate less during training, and by consequence training is more stable.
- Use Rectified Linear Unit in the Generator. The ReLU activation function is used in the generator, except for the last layer, which uses Tanh.
- Use Leaky ReLU in the Discriminator. This was found to work well, in contrast to the Goodfellow et al. (2014) approach, which used maxout. Radford et al. (2015) set the slope of the leak to 0.2.
For the record: for training their DCGANs, they used minibatch SGD with Adam optimization, a batch size of 128, weight init from a zero-centered Normal distribution with 0.02 stddev. Learning rate for Adam was set to 0.0002 (contrary to default 0.001) and the momentum term \(\beta_1\) was reduced to 0.5 from 0.9.
Best practices, always nice!
Summary
In this article, we studied a class of GAN architectures called DCGAN, or Deep Convolutional GAN. We saw that vanilla GANs suffer from instability during training, and that this is not too uncommon for innovations - remember that the original GAN was already proposed back in 2014!
DCGANs apply a set of best practices identified by Radford et al. (2015) in a series of experiments. Minimizing the amount of fully-connected layers, replacing elements like Max Pooling with (fractional-)strided convolutions, applying Batch Normalization, using ReLU in the Generator and Leaky ReLU in the Discriminator stabilizes training - and allows you to achieve better results with your GAN.
Summarizing everything, by reading this article, you have learned...
- That GANs can be used for feature extraction.
- How DCGANs make training GANs more stable, and primarily use Conv instead of Dense layers.
- A set of best practices for training your GAN compared to a vanilla GAN.
I hope that it was useful for your learning process! Please feel free to share what you have learned in the comments section 💬 I’d love to hear from you. Please do the same if you have any questions or other remarks.
Thank you for reading MachineCurve today and happy engineering! 😎
References
Radford, A., Metz, L., & Chintala, S. (2015). Unsupervised representation learning with deep convolutional generative adversarial networks. arXiv preprint arXiv:1511.06434.
Goodfellow, I. J., Pouget-Abadie, J., Mirza, M., Xu, B., Warde-Farley, D., Ozair, S., … & Bengio, Y. (2014). Generative adversarial networks. arXiv preprint arXiv:1406.2661.
Springenberg, Jost Tobias, Dosovitskiy, Alexey, Brox, Thomas, and Riedmiller, Martin. Striving for simplicity: The all convolutional net. arXiv preprint arXiv:1412.6806, 2014.
Mordvintsev, Alexander, Olah, Christopher, and Tyka, Mike. Inceptionism : Going deeper into neural networks. http://googleresearch.blogspot.com/2015/06/ inceptionism-going-deeper-into-neural.html.
Ioffe, Sergey and Szegedy, Christian. Batch normalization: Accelerating deep network training by reducing internal covariate shift. arXiv preprint arXiv:1502.03167, 2015.
Nair, Vinod and Hinton, Geoffrey E. Rectified linear units improve restricted boltzmann machines. In Proceedings of the 27th International Conference on Machine Learning (ICML-10), pp. 807–814, 2010.
Maas, Andrew L, Hannun, Awni Y, and Ng, Andrew Y. Rectifier nonlinearities improve neural network acoustic models. In Proc. ICML, volume 30, 2013.
Xu, Bing, Wang, Naiyan, Chen, Tianqi, and Li, Mu. Empirical evaluation of rectified activations in convolutional network. arXiv preprint arXiv:1505.00853, 2015.

Hi, I'm Chris!
I know a thing or two about AI and machine learning. Welcome to MachineCurve.com, where machine learning is explained in gentle terms.
Getting started
Foundation models
Learn how large language models and other foundation models are working and how you can train open source ones yourself.
Keras
Keras is a high-level API for TensorFlow. It is one of the most popular deep learning frameworks.
Machine learning theory
Read about the fundamentals of machine learning, deep learning and artificial intelligence.
Most recent articles
January 2, 2024
What is Retrieval-Augmented Generation?
December 27, 2023
In-Context Learning: what it is and how it works
December 22, 2023
CLIP: how it works, how it's trained and how to use it
Article tags
Most popular articles
February 18, 2020
How to use K-fold Cross Validation with TensorFlow 2 and Keras?
December 28, 2020
Introduction to Transformers in Machine Learning
December 27, 2021
StyleGAN, a step-by-step introduction
July 17, 2019
This Person Does Not Exist - how does it work?
October 26, 2020
Your First Machine Learning Project with TensorFlow 2.0 and Keras
Connect on social media
Connect with me on LinkedIn
To get in touch with me, please connect with me on LinkedIn. Make sure to write me a message saying hi!
Side info
The content on this website is written for educational purposes. In writing the articles, I have attempted to be as correct and precise as possible. Should you find any errors, please let me know by creating an issue or pull request in this GitHub repository.
All text on this website written by me is copyrighted and may not be used without prior permission. Creating citations using content from this website is allowed if a reference is added, including an URL reference to the referenced article.
If you have any questions or remarks, feel free to get in touch.
TensorFlow, the TensorFlow logo and any related marks are trademarks of Google Inc.
PyTorch, the PyTorch logo and any related marks are trademarks of The Linux Foundation.
Montserrat and Source Sans are fonts licensed under the SIL Open Font License version 1.1.
Mathjax is licensed under the Apache License, Version 2.0.