Easy Table Parsing with TAPAS, Machine Learning and HuggingFace Transformers
March 10, 2021 by Chris
Big documents often contain quite a few tables. Tables are useful: they can provide a structured overview of data that supports or contradicts a particular statement, written in the accompanying text. However, if your goal is to analyze reports - tables can especially be useful because they provide more raw data. But analyzing tables costs a lot of energy, as one has to reason over these tables in answering their questions.
But what if that process can be partially automated?
The Table Parser Transformer, or TAPAS, is a machine learning model that is capable of precisely that. Given a table and a question related to that table, it can provide the answer in a short amount of time.
In this tuturial, we will be taking a look at using Machine Learning for Table Parsing in more detail. Previous approaches cover extracting logic forms manually, while Transformer-based approaches have simplified parsing tables. Finally, we'll take a look at the TAPAS Transformer for table parsing, and how it works. This is followed by implementing a table parsing model yourself using a pretrained and finetuned variant of TAPAS, with HuggingFace Transformers.
After reading this tutorial, you will understand...
- How Machine Learning can be used for parsing tables.
- Why Transformer-based approaches have simplified table parsing over other ML approaches.
- How you can use TAPAS and HuggingFace Transformers to implement a table parser with Python and ML.
Let's take a look! 🚀
Machine Learning for Table Parsing: TAPAS
Ever since Vaswani et al. (2017) introduced the Transformer architecture back in 2017, the field of NLP has been on fire. Transformers have removed the need for recurrent segments and thus avoiding the drawbacks of recurrent neural networks and LSTMs when creating sequence based models. By relying on a mechanism called self-attention, built-in with multiple so-called attention heads, models are capable of generating a supervision signal themselves.
By consequence, Transformers have widely used the pretraining-finetuning paradigm, where models are first pretrained using a massive but unlabeled dataset, acquiring general capabilities, after which they are finetuned with a smaller but labeled and hence task-focused dataset.
The results are incredible: through subsequent improvements like GPT and BERT and a variety of finetuned models, Transformers can now be used for a wide variety of tasks ranging from text summarization, machine translation to speech recognition. And today we can also add table parsing to that list.
Additional reading materials:
BERT for Table Parsing
The BERT family of language models is a widely varied but very powerful family of language models that relies on the encoder segment of the original Transformer. Invented by Google, it employs Masked Language Modeling during the pretraining and finetuning stages, and slightly adapts architecture and embedding in order to add more context to the processed representations.
TAPAS, which stands for Table Parser, is an extension of BERT proposed by Herzig et al. (2020) - who are affiliated with Google. It is specifically tailored to table parsing - not unsurprising given its name. TAPAS allows tables to be input after they are flattened and thus essentially converted into 1D.
By adding a variety of additional embeddings, however, table specific and additional table context can be harnessed during training. It outputs a prediction for an aggregation operator (i.e., what to do with some outcome) and cell selection coordinates (i.e., what is the outcome to do something with).
TAPAS is covered in another article on this website, and I recommend going there if you want to understand how it works in great detail. For now, a visualization of its architecture will suffice - as this is a practical tutorial :)
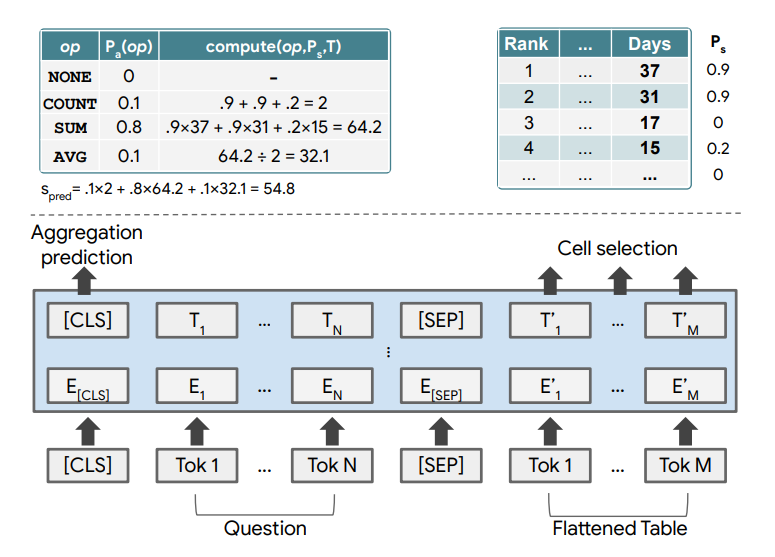
Source: Herzig et al. (2020)
Implementing a Table Parsing model with HuggingFace Transformers
Let's now take a look at how you can implement a Table Parsing model yourself with HuggingFace Transformers. We'll first focus on the software requirements that you must install into your environment. You will then learn how to code a TAPAS based table parser for question answering. Finally, we will also show you the results that we got when running the code.
Software requirements
HuggingFace Transformer is a Python library that was created for democratizing the application of state-of-the-art NLP models, Transformers. It can easily be installed with pip, by means of pip install transformers. If you are running it, you will also need to use PyTorch or TensorFlow as the backend - by installing it into the same environment (or vice-versa, installing HuggingFace Transformers in your PT/TF environment).
The code in this tutorial was created with PyTorch, but it may be relatively easy (possibly with a few adaptations) to run it with TensorFlow as well.
To run the code, you will need to install the following things into an environment:
- HuggingFace Transformers:
pip install transformers. - A deep learning framework: either TensorFlow or PyTorch.
- Torch Scatter, which is a TAPAS dependency. The command is dependent on whether you are using it with PyTorch GPU or CPU. Replace
1.6.0with your PyTorch version.- For GPU:
pip install torch-scatter -f https://pytorch-geometric.com/whl/torch-1.6.0+${CUDA}.html - For CPU:
pip install torch-scatter -f https://pytorch-geometric.com/whl/torch-1.6.0+cpu.html
- For GPU:
pip install torch-scatter -f https://pytorch-geometric.com/whl/torch-1.6.0+${CUDA}.html
Model code
Compared to Pipelines and other pretrained models, running TAPAS requires you to do a few more things. Below, you can find the code for the TAPAS based model as a whole. But don't worry! I'll explain everything right now.
- Imports: First of all, we're importing the
TapasTokenizerandTapasForQuestionAnsweringimports fromtransformers- that is, HuggingFace Transformers. The tokenizer can be used for tokenization of which the result can be fed to the question answering model subsequently. Tapas requires a specific way of tokenization and input presenting, and these Tapas specific tokenizer and QA model have this built in. Very easy! We also importpandas, which we'll need later. - Table and question definitions: next up is defining the table and the questions. As you can see, the table is defined as a Python dictionary. Our table has two columns -
CitiesandInhabitants- and values (in millions of inhabitants) are provided for Paris, London and Lyon. - Specifying some Python definitions:
- Loading the model and tokenizer: in
load_model_and_tokenizer, we initialize the Tokenizer and QuestionAnswering model with a finetuned variant of TAPAS - more specifically,google/tapas-base-finetuned-wtq, or TAPAS finetuned on WikiTable Questions (WTQ). - Preparing the inputs: our Python dictionary must first be converted into a
DataFramebefore it can be tokenized. We usepandasfor this purpose, and create the dataframe from a dictionary. We can then feed it to thetokenizertogether with thequeries, and return the results. - Generating the predictions: in
generate_predictions, we feed the tokenized inputs to our TAPAS model. Our tokenizer can be used subsequently to find the cell coordinates and aggregation operators that were predicted - recall that TAPAS predicts relevant cells (the coordinates) and an operator that must be executed to answer the question (the aggregation operator). - Postprocessing the predictions: in
postprocess_predictions, we convert the predictions into a format that can be displayed on screen. - Showing the answers: in
show_answers, we then actually visualize these answers. - Running TAPAS:
run_tapascombines all otherdefs together in an end-to-end flow. This wasn't directly added to__main__because it's best practice to keep as much functionality within Python definitions.
- Loading the model and tokenizer: in
- Running the whole thing: so far, we have created a lot of definitions, but nothing is running yet. That's why we check whether our Python is running with that if statement at the bottom, and if so, invoke
run_tapas()- and therefore the whole model.
from transformers import TapasTokenizer, TapasForQuestionAnswering
import pandas as pd
# Define the table
data = {'Cities': ["Paris, France", "London, England", "Lyon, France"], 'Inhabitants': ["2.161", "8.982", "0.513"]}
# Define the questions
queries = ["Which city has most inhabitants?", "What is the average number of inhabitants?", "How many French cities are in the list?", "How many inhabitants live in French cities?"]
def load_model_and_tokenizer():
"""
Load
"""
# Load pretrained tokenizer: TAPAS finetuned on WikiTable Questions
tokenizer = TapasTokenizer.from_pretrained("google/tapas-base-finetuned-wtq")
# Load pretrained model: TAPAS finetuned on WikiTable Questions
model = TapasForQuestionAnswering.from_pretrained("google/tapas-base-finetuned-wtq")
# Return tokenizer and model
return tokenizer, model
def prepare_inputs(data, queries, tokenizer):
"""
Convert dictionary into data frame and tokenize inputs given queries.
"""
# Prepare inputs
table = pd.DataFrame.from_dict(data)
inputs = tokenizer(table=table, queries=queries, padding='max_length', return_tensors="pt")
# Return things
return table, inputs
def generate_predictions(inputs, model, tokenizer):
"""
Generate predictions for some tokenized input.
"""
# Generate model results
outputs = model(**inputs)
# Convert logit outputs into predictions for table cells and aggregation operators
predicted_table_cell_coords, predicted_aggregation_operators = tokenizer.convert_logits_to_predictions(
inputs,
outputs.logits.detach(),
outputs.logits_aggregation.detach()
)
# Return values
return predicted_table_cell_coords, predicted_aggregation_operators
def postprocess_predictions(predicted_aggregation_operators, predicted_table_cell_coords, table):
"""
Compute the predicted operation and nicely structure the answers.
"""
# Process predicted aggregation operators
aggregation_operators = {0: "NONE", 1: "SUM", 2: "AVERAGE", 3:"COUNT"}
aggregation_predictions_string = [aggregation_operators[x] for x in predicted_aggregation_operators]
# Process predicted table cell coordinates
answers = []
for coordinates in predicted_table_cell_coords:
if len(coordinates) == 1:
# 1 cell
answers.append(table.iat[coordinates[0]])
else:
# > 1 cell
cell_values = []
for coordinate in coordinates:
cell_values.append(table.iat[coordinate])
answers.append(", ".join(cell_values))
# Return values
return aggregation_predictions_string, answers
def show_answers(queries, answers, aggregation_predictions_string):
"""
Visualize the postprocessed answers.
"""
for query, answer, predicted_agg in zip(queries, answers, aggregation_predictions_string):
print(query)
if predicted_agg == "NONE":
print("Predicted answer: " + answer)
else:
print("Predicted answer: " + predicted_agg + " > " + answer)
def run_tapas():
"""
Invoke the TAPAS model.
"""
tokenizer, model = load_model_and_tokenizer()
table, inputs = prepare_inputs(data, queries, tokenizer)
predicted_table_cell_coords, predicted_aggregation_operators = generate_predictions(inputs, model, tokenizer)
aggregation_predictions_string, answers = postprocess_predictions(predicted_aggregation_operators, predicted_table_cell_coords, table)
show_answers(queries, answers, aggregation_predictions_string)
if __name__ == '__main__':
run_tapas()
Results
Running the WTQ based TAPAS model against the questions specified above gives the following results:
Which city has most inhabitants?
Predicted answer: London, England
What is the average number of inhabitants?
Predicted answer: AVERAGE > 2.161, 8.982, 0.513
How many French cities are in the list?
Predicted answer: COUNT > Paris, France, Lyon, France
How many inhabitants live in French cities?
Predicted answer: SUM > 2.161, 0.513
This is great!
- According to our table, London has most inhabitants. True. As you can see, there was no prediction for an aggregation operator. This means that TAPAS was smart enough to recognize that this is a cell selection procedure rather than some kind of aggregation!
- For the second question, the operator predicted is
AVERAGE- and all relevant cells are selected. True again. - Very cool is that we can even ask more difficult questions that do not contain the words - for example, we get
COUNTand two relevant cells - precisely what we mean - when we ask which French cities are in the list. - Finally, a correct
SUMoperator and cells are also provided when the question is phrased differently, focusing on inhabitants instead.
Really cool! 😎
Summary
Transformers have really changed the world of language models. Harnessing the self-attention mechanism, they have removed the need for recurrent segments and hence sequential processing, allowing bigger and bigger models to be created that every now and then show human-like behavior - think GPT, BERT and DALL-E.
In this tutorial, we focused on TAPAS, which is an extension of BERT and which can be used for table parsing. It specifically focused on the practical parts: that is, implementing this model for real-world usage by means of HuggingFace Transformers.
Reading it, you have learned...
- How Machine Learning can be used for parsing tables.
- Why Transformer-based approaches have simplified table parsing over other ML approaches.
- How you can use TAPAS and HuggingFace Transformers to implement a table parser with Python and ML.
I hope that this tutorial was useful for you! 🚀 If it was, please let me know in the comments section below 💬 Please do the same if you have any questions or other comments. I'd love to hear from you.
Thank you for reading MachineCurve today and happy engineering! 😎
References
Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A. N., … & Polosukhin, I. (2017). Attention is all you need. Advances in neural information processing systems, 30, 5998-6008.
Herzig, J., Nowak, P. K., Müller, T., Piccinno, F., & Eisenschlos, J. M. (2020). Tapas: Weakly supervised table parsing via pre-training. arXiv preprint arXiv:2004.02349.
GitHub. (n.d.). Google-research/tapas. https://github.com/google-research/tapas
Google. (2020, April 30). Using neural networks to find answers in tables. Google AI Blog. https://ai.googleblog.com/2020/04/using-neural-networks-to-find-answers.html
HuggingFace. (n.d.). TAPAS — transformers 4.3.0 documentation. Hugging Face – On a mission to solve NLP, one commit at a time. https://huggingface.co/transformers/model_doc/tapas.html

Hi, I'm Chris!
I know a thing or two about AI and machine learning. Welcome to MachineCurve.com, where machine learning is explained in gentle terms.
Getting started
Foundation models
Learn how large language models and other foundation models are working and how you can train open source ones yourself.
Keras
Keras is a high-level API for TensorFlow. It is one of the most popular deep learning frameworks.
Machine learning theory
Read about the fundamentals of machine learning, deep learning and artificial intelligence.
Most recent articles
January 2, 2024
What is Retrieval-Augmented Generation?
December 27, 2023
In-Context Learning: what it is and how it works
December 22, 2023
CLIP: how it works, how it's trained and how to use it
Article tags
Most popular articles
February 18, 2020
How to use K-fold Cross Validation with TensorFlow 2 and Keras?
December 28, 2020
Introduction to Transformers in Machine Learning
December 27, 2021
StyleGAN, a step-by-step introduction
July 17, 2019
This Person Does Not Exist - how does it work?
October 26, 2020
Your First Machine Learning Project with TensorFlow 2.0 and Keras
Connect on social media
Connect with me on LinkedIn
To get in touch with me, please connect with me on LinkedIn. Make sure to write me a message saying hi!
Side info
The content on this website is written for educational purposes. In writing the articles, I have attempted to be as correct and precise as possible. Should you find any errors, please let me know by creating an issue or pull request in this GitHub repository.
All text on this website written by me is copyrighted and may not be used without prior permission. Creating citations using content from this website is allowed if a reference is added, including an URL reference to the referenced article.
If you have any questions or remarks, feel free to get in touch.
TensorFlow, the TensorFlow logo and any related marks are trademarks of Google Inc.
PyTorch, the PyTorch logo and any related marks are trademarks of The Linux Foundation.
Montserrat and Source Sans are fonts licensed under the SIL Open Font License version 1.1.
Mathjax is licensed under the Apache License, Version 2.0.