Easy Named Entity Recognition with Machine Learning and HuggingFace Transformers
February 11, 2021 by Chris
Deep learning approaches have boosted the field of Natural Language Processing in recent years. A variety of tasks can now be performed, and relatively easy. For example, we can now use ML to perform text summarization, question answering and sentiment analysis - with only a few lines of code.
And it doesn't end there. The task of Named Entity Recognition can also be performed using Machine Learning. Among others, it can be performed with Transformers, which will be the focus of today's tutorial. In it, we will focus on performing an NLP task with a pretrained Transformer. It is therefore structured as follows. Firstly, we'll take a brief look at the concept of Named Entity Recognition itself - because you'll need to understand what it is. Then, we focus on Transformers for NER, and in particular the pretraining-finetuning approach and the model we will be using today.
This is finally followed by an example implementation of a Named Entity Recognition model that is easy and understandable by means of a HuggingFace Transformers pipeline.
After reading this tutorial, you will understand...
- What Named Entity Recognition is all about.
- How Transformers can be used for Named Entity Recognition.
- How a pipeline performing NER with Machine Learning can be built.
Let's take a look! 🚀
Code example: NER with Transformers and Python
The code below allows you to create a simple but effective Named Entity Recognition pipeline with HuggingFace Transformers. If you use it, ensure that the former is installed on your system, as well as TensorFlow or PyTorch. If you want to understand everything in a bit more detail, make sure to read the rest of the tutorial as well! 🔥
from transformers import pipeline
# Initialize the NER pipeline
ner = pipeline("ner")
# Phrase
phrase = "David helped Peter enter the building, where his house is located."
# NER task
ner_result = ner(phrase)
# Print result
print(ner_result)
What is Named Entity Recognition?
If we are to build a model for Named Entity Recognition (NER), we will need to understand what it does, don't we?
[Named Entity Recognition is used] to locate and classify named entities mentioned in unstructured text into pre-defined categories such as person names, organizations, locations, medical codes, time expressions, quantities, monetary values, percentages, etc.
Wikipedia (2005)
As with any technical definition, it is quite a difficult one for beginners, so let's take a look at it in a bit more detail :-)
Now, what is a "named entity", for example?
A named entity is a real-world object, such as persons, locations, organizations, products, etc., that can be denoted with a proper name. It can be abstract or have a physical existence.
Wikipedia (2007)
I see - so NER models can be used to detect real-world objects in text. For example, for the following text:
- The bus is heading to the garage for maintenance.
Here, 'bus' is of type vehicle, whereas the 'garage' is of type building. Those are named entities. The words 'the', 'is', 'to the', 'for' are not, and are hence of type outside of a named entity, as we shall see later.
In other words, using Named Entity Recognition, we can extract real-world objects from text, or infuse more understanding about the meaning of a particular text (especially when combined with other approaches that highlight different aspects of the text). Let's now take a look at how Transformer architectures can be used for this purpose.
Transformers for NER: pretraining and finetuning
Until 2017, most NLP related tasks that used neural networks were performed using network architectures like recurrent neural networks or LSTMs. This proved to be troublesome, despite some improvements such as the attention mechanism: the sequential nature of models ensured that they could not be trained well on larger texts.
Vaswani et al. (2017) entirely replaced the paradigm of recurrent networks with a newer paradigm by introducing an architecture called a Transformer - notably, in a paper named and indicating that attention is all you need. The attention mechanism, when combined with an encoder-decoder type of architecture, is enough to achieve state-of-the-art performance in a variety of language tasks... without the recurrent segments being there.
In other words, NLP models have moved from sequential processing to parallel processing of text... and this has tremendously improved their performance.
Among others, models like BERT and GPT have been introduced. They use (parts of, i.e. only the encoder or decoder) the original Transformer architecture and apply their own elements on top of it, then train it to achieve great performance. But how does training happen? Let's take a look at the common approach followed by Transformers, which is called pretraining-finetuning.

An overview of the Transformer architecture. Source: Vaswani et al. (2017)
What is the pretraining-finetuning approach to NLP?
Training a supervised learning model requires you to have at your disposal a labeled dataset. As with anything related to data management, creating, maintaining and eventually having such datasets available poses a big challenge to many organizations. This can be problematic if organizations want to use Transformers, because these models are often very big (GPT-3 has billions of parameters!). If datasets are too small, models cannot be trained because they overfit immediately.
Compared to labeled data, organizations (and the world in general) often have a lot of unlabeled data at their disposal. Think of the internet as one big example of massive amounts of unlabeled text -- semantics are often hidden within the content, while web pages don't provide such metadata and thus labels in some kind of parallel data space whatsoever. If only we could benefit from this vast amount of data, that would be good.
Transformers are often trained with a pretraining-finetuning approach, which benefits from this fact. The approach involves using a large, unlabeled corpus of text (with large, you can think about gigabytes of data) to which it applies a very generic language modeling task (such as "predict the next token given this input text" or "predict the hidden tokens"). This process called pretraining allows a Transformer to capture generic syntactical and semantic patterns from text. After the pretraining phase has finished, we can use the labeled but smaller dataset to perform finetuning the model to that particular task (indeed, such as "predict the named entity for this word/token", which we are taking a look at in this tutorial).
Visually, this process looks as follows:
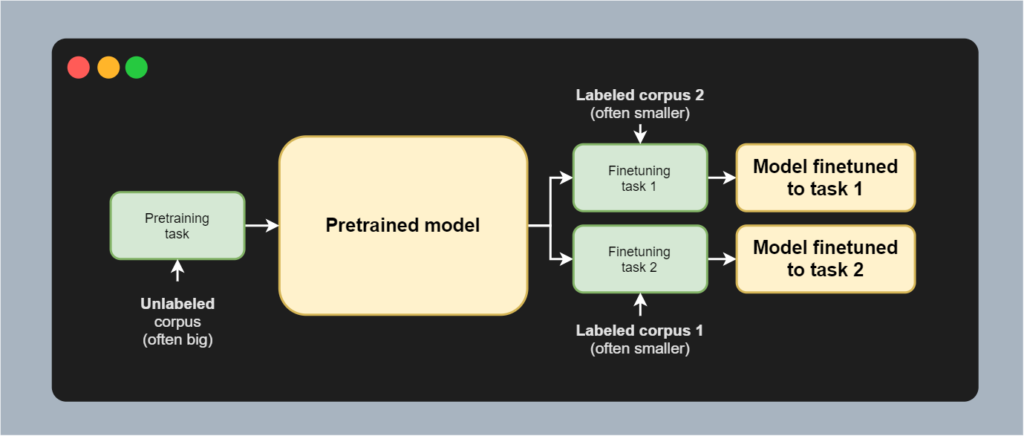
Briefly note that a pretrained model does not necessarily have to be used in a finetuning setting, because finetuning requires a lot of computational resources. You can also perform a feature-based approach (i.e. use the outputs of the pretrained models as tokens in a normal, and thus smaller, neural network). Many studies however find finetuning-based approaches to be superior to feature-based ones, despite the increased computational cost.
Today's pretrained Transformer: BERTlarge finetuned on CoNLL-2003
Today, we will be using the BERT Transformer. BERT, which stands for Bidirectional Encoder Representations for Transformer, utilizes the encoder segment (i.e. the left part) of the original Transformer architecture. For pretraining, among others, it performs a particular task where masked inputs have to be reconstructed.
We are using the BERTlarge type of BERT which is pretrained with 24 encoder segments, a 1024-dimensional hidden state, and 16 attention heads (64 dimensions per head).
Finetuning happens with the CoNLL-2003 dataset:
The shared task of CoNLL-2003 concerns language-independent named entity recognition. We will concentrate on four types of named entities: persons, locations, organizations and names of miscellaneous entities that do not belong to the previous three groups.
UAntwerpen (n.d.)
Building the Named Entity Recognition pipeline
Constructing the pipeline for our Named Entity Recognition pipeline occurs with the HuggingFace Transformers library. This library, which is developed by a company called HuggingFace and democratizes using language models (and training language models) for PyTorch and TensorFlow, provides a so-called pipeline that supports Named Entity Recognition out of the box.
Very easy indeed!
The model that will be used in this pipeline is the so-called dbmdz/bert-large-cased-finetuned-conll03-english model, which involves a BERTlarge model trained on CoNLL-2003 and more specifically, its English NER dataset.
It can recognize whether (parts of) words belong to either of these classes:
- O, Outside of a named entity
- B-MIS, Beginning of a miscellaneous entity right after another miscellaneous entity
- I-MIS, Miscellaneous entity
- B-PER, Beginning of a person’s name right after another person’s name
- I-PER, Person’s name
- B-ORG, Beginning of an organization right after another organization
- I-ORG, Organization
- B-LOC, Beginning of a location right after another location
- I-LOC, Location
Full model code
Below, you can find the entire code for the NER pipeline. As I said, it's going to be a very easy pipeline!
- First of all, we import the
pipelineAPI from the HuggingFacetransformerslibrary. If you don't have it installed: you can do so withpip install transformers. Please make sure that you have TensorFlow or PyTorch on your system, and in the environment where you are running the code. - You then initialize the NER pipeline by initializing the pipeline API for a
"ner"task. - The next action you take is defining a phrase and feeding it through the
nerpipeline. - That's it - you then print the outcome on screen.
from transformers import pipeline
# Initialize the NER pipeline
ner = pipeline("ner")
# Phrase
phrase = "David helped Peter enter the building, where his house is located."
# NER task
ner_result = ner(phrase)
# Print result
print(ner_result)
Here's what you will see for the phrase specified above:
[{'word': 'David', 'score': 0.9964208602905273, 'entity': 'I-PER', 'index': 1}, {'word': 'Peter', 'score': 0.9955975413322449, 'entity': 'I-PER', 'index': 3}]
The model recognizes David at index 1 and Peter at index 3 as I-PER, a person's name. Indeed they are!
Recap
In this tutorial, you have seen how you can create a simple but effective pipeline for Named Entity Recognition with Machine Learning and Python. First, we looked at what NER involves, and saw that it can be used for recognizing real-world objects in pieces of text. Subsequently, we looked at Transformers, and how they are used in NLP tasks these days. We saw that Transformers improve upon more classic approaches like recurrent neural networks and LSTMs in the sense that they do no longer process data sequentially, but rather in parallel.
Once the theoretical part was over, we implemented an easy NER pipeline with HuggingFace Transformers. This library democratizes NLP by means of providing a variety of models and model training facilities out of the box. Today, we used a BERTlarge model trained on a specific NER dataset for our NER pipeline. Creating the pipeline was really easy, as we saw in our code example!
I hope that you have learned something when reading the tutorial today! If you did, please feel free to drop a comment in the comments section below 💬 Please do the same if you have any questions, remarks, or comments otherwise.
Thank you for reading MachineCurve today and happy engineering! 😎
References
Wikipedia. (2005, May 18). Named-entity recognition. Wikipedia, the free encyclopedia. Retrieved February 11, 2021, from https://en.wikipedia.org/wiki/Named-entity_recognition
Wikipedia. (2007, October 11). Named entity. Wikipedia, the free encyclopedia. Retrieved February 11, 2021, from https://en.wikipedia.org/wiki/Named_entity
Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A. N., … & Polosukhin, I. (2017). Attention is all you need. Advances in neural information processing systems, 30, 5998-6008.
UAntwerpen. (n.d.). Language-independent named entity recognition (II). https://www.clips.uantwerpen.be/conll2003/ner/

Hi, I'm Chris!
I know a thing or two about AI and machine learning. Welcome to MachineCurve.com, where machine learning is explained in gentle terms.
Getting started
Foundation models
Learn how large language models and other foundation models are working and how you can train open source ones yourself.
Keras
Keras is a high-level API for TensorFlow. It is one of the most popular deep learning frameworks.
Machine learning theory
Read about the fundamentals of machine learning, deep learning and artificial intelligence.
Most recent articles
January 2, 2024
What is Retrieval-Augmented Generation?
December 27, 2023
In-Context Learning: what it is and how it works
December 22, 2023
CLIP: how it works, how it's trained and how to use it
Article tags
Most popular articles
February 18, 2020
How to use K-fold Cross Validation with TensorFlow 2 and Keras?
December 28, 2020
Introduction to Transformers in Machine Learning
December 27, 2021
StyleGAN, a step-by-step introduction
July 17, 2019
This Person Does Not Exist - how does it work?
October 26, 2020
Your First Machine Learning Project with TensorFlow 2.0 and Keras
Connect on social media
Connect with me on LinkedIn
To get in touch with me, please connect with me on LinkedIn. Make sure to write me a message saying hi!
Side info
The content on this website is written for educational purposes. In writing the articles, I have attempted to be as correct and precise as possible. Should you find any errors, please let me know by creating an issue or pull request in this GitHub repository.
All text on this website written by me is copyrighted and may not be used without prior permission. Creating citations using content from this website is allowed if a reference is added, including an URL reference to the referenced article.
If you have any questions or remarks, feel free to get in touch.
TensorFlow, the TensorFlow logo and any related marks are trademarks of Google Inc.
PyTorch, the PyTorch logo and any related marks are trademarks of The Linux Foundation.
Montserrat and Source Sans are fonts licensed under the SIL Open Font License version 1.1.
Mathjax is licensed under the Apache License, Version 2.0.