Model evaluation is key in validating whether your machine learning or deep learning model really works. This procedure, where you test whether your model really works against data it has never seen before - on data with and without the distribution of your training data - ensures that your model is useful in practice. Because hey, what would be the benefits of using a model if it doesn't work?
Deep learning frameworks use different approaches for evaluating your models. This tutorial zooms into the PyTorch world, and covers evaluating your model with either PyTorch or PyTorch Lightning. After reading the tutorial, you will...
- Understand why it is good practice to evaluate your model after training.
- Have built an evaluation approach for your PyTorch model.
- Have also built such an approach for your PyTorch Lightning model.
Summary and code examples: evaluating your PyTorch or Lightning model
Training a neural network involves feeding forward data, comparing the predictions with the ground truth, generating a loss value, computing gradients in the backwards pass and subsequent optimization. This cyclical process is repeated until you manually stop the training process or when it is configured to stop automatically. You train your model with a training dataset.
However, if you want to use your model in the real world, you must evaluate - or test - it with data that wasn't seen during the training process. The reason for this is that if you would evaluate your model with your training data, it would equal a student who is grading their own exams, and you don't want that. That's why today, we'll show you how to evaluate your PyTorch and PyTorch Lightning models. Below, there are two full-fledged examples for doing so. If you want to understand things in more detail, make sure to read the rest of this tutorial as well :)
Classic PyTorch
Testing your PyTorch model requires you to, well, create a PyTorch model first. This involves defining a nn.Module based model and adding a custom training loop. Once this process has finished, testing happens, which is performed using a custom testing loop. Here's a full example of model evaluation in PyTorch. If you want to understand things in more detail, or want to build this approach step-by-step, make sure to read the rest of this tutorial as well! :)
import os
import torch
from torch import nn
from torchvision.datasets import MNIST
from torch.utils.data import DataLoader
from torchvision import transforms
class MLP(nn.Module):
'''
Multilayer Perceptron.
'''
def __init__(self):
super().__init__()
self.layers = nn.Sequential(
nn.Flatten(),
nn.Linear(28 * 28 * 1, 64),
nn.ReLU(),
nn.Linear(64, 32),
nn.ReLU(),
nn.Linear(32, 10)
)
def forward(self, x):
'''Forward pass'''
return self.layers(x)
if __name__ == '__main__':
# Set fixed random number seed
torch.manual_seed(42)
# Prepare MNIST dataset
dataset = MNIST(os.getcwd(), download=True, transform=transforms.ToTensor(), train=True)
dataset_test = MNIST(os.getcwd(), download=True, transform=transforms.ToTensor(), train=False)
trainloader = torch.utils.data.DataLoader(dataset, batch_size=10, shuffle=True, num_workers=1)
trainloader_test = torch.utils.data.DataLoader(dataset_test, batch_size=10, shuffle=True, num_workers=1)
# Initialize the MLP
mlp = MLP()
# Define the loss function and optimizer
loss_function = nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(mlp.parameters(), lr=1e-4)
# Run the training loop for 15 epochs
for epoch in range(0, 15):
# Print epoch
print(f'Starting epoch {epoch+1}')
# Set current loss value
current_loss = 0.0
# Iterate over the DataLoader for training data
for i, data in enumerate(trainloader, 0):
# Get inputs
inputs, targets = data
# Zero the gradients
optimizer.zero_grad()
# Perform forward pass
outputs = mlp(inputs)
# Compute loss
loss = loss_function(outputs, targets)
# Perform backward pass
loss.backward()
# Perform optimization
optimizer.step()
# Print statistics
current_loss += loss.item()
if i % 500 == 499:
print('Loss after mini-batch %5d: %.3f' %
(i + 1, current_loss / 500))
current_loss = 0.0
# Process is complete.
print('Training process has finished.')
# Print about testing
print('Starting testing')
# Saving the model
save_path = './mlp.pth'
torch.save(mlp.state_dict(), save_path)
# Testing loop
correct, total = 0, 0
with torch.no_grad():
# Iterate over the test data and generate predictions
for i, data in enumerate(trainloader_test, 0):
# Get inputs
inputs, targets = data
# Generate outputs
outputs = mlp(inputs)
# Set total and correct
_, predicted = torch.max(outputs.data, 1)
total += targets.size(0)
correct += (predicted == targets).sum().item()
# Print accuracy
print('Accuracy: %d %%' % (100 * correct / total))
PyTorch Lightning
Another way of using PyTorch is with Lightning, a lightweight library on top of PyTorch that helps you organize your code. In Lightning, you must specify testing a little bit differently... with .test(), to be precise. Like the training loop, it removes the need to define your own custom testing loop with a lot of boilerplate code. In the test_step within the model, you can specify precisely what ought to happen when performing model evaluation.
Here, you'll find a full example for model evaluation with PyTorch Lightning. If you want to understand Lightning in more detail, make sure to read on as well!
import os
import torch
from torch import nn
from torchvision.datasets import MNIST
from torch.utils.data import DataLoader
from torchvision import transforms
import pytorch_lightning as pl
class MLP(pl.LightningModule):
def __init__(self):
super().__init__()
self.layers = nn.Sequential(
nn.Linear(28 * 28 * 1, 64),
nn.ReLU(),
nn.Linear(64, 32),
nn.ReLU(),
nn.Linear(32, 10)
)
self.ce = nn.CrossEntropyLoss()
def forward(self, x):
return self.layers(x)
def training_step(self, batch, batch_idx):
x, y = batch
x = x.view(x.size(0), -1)
y_hat = self.layers(x)
loss = self.ce(y_hat, y)
self.log('train_loss', loss)
return loss
def test_step(self, batch, batch_idx):
x, y = batch
x = x.view(x.size(0), -1)
y_hat = self.layers(x)
loss = self.ce(y_hat, y)
y_hat = torch.argmax(y_hat, dim=1)
accuracy = torch.sum(y == y_hat).item() / (len(y) * 1.0)
output = dict({
'test_loss': loss,
'test_acc': torch.tensor(accuracy),
})
return output
def configure_optimizers(self):
optimizer = torch.optim.Adam(self.parameters(), lr=1e-4)
return optimizer
if __name__ == '__main__':
# Load the datasets
dataset = MNIST(os.getcwd(), download=True, transform=transforms.ToTensor(), train=True)
dataset_test = MNIST(os.getcwd(), download=True, transform=transforms.ToTensor(), train=False)
# Set seed
pl.seed_everything(42)
# Initialize model and Trainer
mlp = MLP()
trainer = pl.Trainer(auto_scale_batch_size='power', gpus=1, deterministic=True, max_epochs=15)
# Perform training
trainer.fit(mlp, DataLoader(dataset, num_workers=15, pin_memory=True))
# Perform evaluation
trainer.test(mlp, DataLoader(dataset_test, num_workers=15, pin_memory=True))
Why evaluate your model after training?
At a high level, training a deep neural network involves two main steps: the first is the forward pass, and the second is the backwards pass and subsequent optimization.
When you start training a model, you'll initialize the weights and biases of the neurons pseudorandomly. During the first iteration, which is also called an epoch, all the data from your training set is fed through the model, generating predictions. This is called the forward pass. The predictions from this forward pass are compared with the actual targets for these training samples, which are called ground truth. The offset between the predictions and the targets is known as a loss value. At the beginning of a training process, loss values are relatively high.
Once the loss value is known, we perform the backwards pass. Here, we compute the contribution of the individual neurons to the error. Having computed this contribution, which is also known as a gradient, we can perform optimization with an optimizer such as gradient descent or Adam. Optimization slightly changes the weights into the opposite direction of the gradients, and it likely makes the model better. We then start a new iteration, or epoch, and the process starts again.
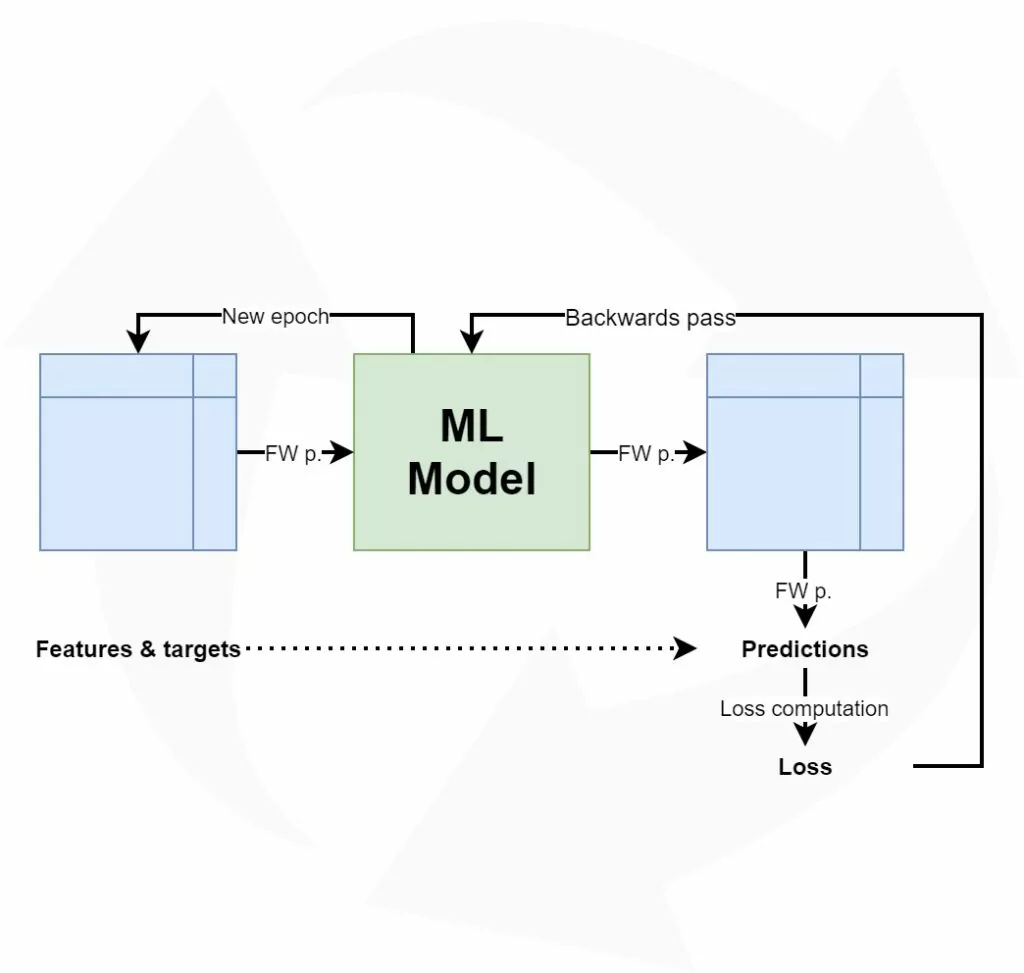
Once you finish training the model, you want to use it in the real world. But can it easily be applied there? Who guarantees that it actually works, and that it didn't capture some spurious patterns present in the training set? Relevant questions which must be answered by means of model evaluation.
From this high-level process description, it does however become clear that the data from the training set is used in optimization, i.e. for making the model better. This is true for the actual training data as well as the validation data, which come from the same dataset but which are used for slightly different purposes. This is problematic if we want to evaluate the model, because we cannot simply rely on this data for evaluation purposes. If we would do that, it would equal a student grading their own exams. In other words, we need different data for this purpose.
Testing data comes at the rescue here. By generating a train/test split before training the model, setting apart a small portion of the training data, we can evaluate our model with data that was never seen during the training process. In other words, the student is no longer grading their own homework. This ensures that we create models that are more likely to work in the real world if evaluation passes. And precisely that is what we are now going to do. We'll show you how to evaluate your models created with PyTorch or PyTorch Lightning.
Evaluating your PyTorch model
Let's now take a look at how we can evaluate a model that was created with PyTorch.
The model we will evaluate
This is the model that we want to evaluate. If you want to understand how it works, make sure to read this tutorial too.
import os
import torch
from torch import nn
from torchvision.datasets import MNIST
from torch.utils.data import DataLoader
from torchvision import transforms
class MLP(nn.Module):
'''
Multilayer Perceptron.
'''
def __init__(self):
super().__init__()
self.layers = nn.Sequential(
nn.Flatten(),
nn.Linear(28 * 28 * 1, 64),
nn.ReLU(),
nn.Linear(64, 32),
nn.ReLU(),
nn.Linear(32, 10)
)
def forward(self, x):
'''Forward pass'''
return self.layers(x)
if __name__ == '__main__':
# Set fixed random number seed
torch.manual_seed(42)
# Prepare MNIST dataset
dataset = MNIST(os.getcwd(), download=True, transform=transforms.ToTensor(), train=True)
dataset_test = MNIST(os.getcwd(), download=True, transform=transforms.ToTensor(), train=False)
trainloader = torch.utils.data.DataLoader(dataset, batch_size=10, shuffle=True, num_workers=1)
trainloader_test = torch.utils.data.DataLoader(dataset_test, batch_size=10, shuffle=True, num_workers=1)
# Initialize the MLP
mlp = MLP()
# Define the loss function and optimizer
loss_function = nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(mlp.parameters(), lr=1e-4)
# Run the training loop
for 15 epochs
for epoch in range(0, 15):
# Print epoch
print(f'Starting epoch {epoch+1}')
# Set current loss value
current_loss = 0.0
# Iterate over the DataLoader for training data
for i, data in enumerate(trainloader, 0):
# Get inputs
inputs, targets = data
# Zero the gradients
optimizer.zero_grad()
# Perform forward pass
outputs = mlp(inputs)
# Compute loss
loss = loss_function(outputs, targets)
# Perform backward pass
loss.backward()
# Perform optimization
optimizer.step()
# Print statistics
current_loss += loss.item()
if i % 500 == 499:
print('Loss after mini-batch %5d: %.3f' %
(i + 1, current_loss / 500))
current_loss = 0.0
# Process is complete.
print('Training process has finished.')
Adding evaluation code
As you can see in the code above, PyTorch requires you to define many aspects of the training process yourself. For example, we have defined the entire training loop above. The same is true for model evaluation. In classic PyTorch, we also have to define our own testing loop.
We can define the testing loop so in the following way.
- We print that testing starts and save the model, so that we can use it layer (and test it separately, if we wanted to do that).
- We define the testing loop:
- We first set
torch.no_grad()to ensure no gradients are updated, and setcorrectandtotal(the number of correct and total number of values processed during testing) to zero. - We then iterate over the test data generator.
- During every minibatch iteration, we decompose the data into inputs and targets, generate the outputs, compare the predictions with the ground truth values, and update the
totalandcorrectvariables. Here,torch.max(outputs.data, 1)looks complex, but it is simple - it simply takes a look at the indices of the classes that have the highest maximum value. Now that's a smart approach, because these are the indices of our classes too! In one line of code, we can make our predictions comparable with the targets.
- We first set
- Finally, we print the accuracy.
# Print about testing
print('Starting testing')
# Saving the model
save_path = './mlp.pth'
torch.save(mlp.state_dict(), save_path)
# Testing loop
correct, total = 0, 0
with torch.no_grad():
# Iterate over the test data and generate predictions
for i, data in enumerate(trainloader_test, 0):
# Get inputs
inputs, targets = data
# Generate outputs
outputs = mlp(inputs)
# Set total and correct
_, predicted = torch.max(outputs.data, 1)
total += targets.size(0)
correct += (predicted == targets).sum().item()
# Print accuracy
print('Accuracy: %d %%' % (100 * correct / total))
Results
After running the model for 15 epochs, we get an accuracy of 96% on the MNIST dataset:
...
Starting epoch 15
Loss after mini-batch 500: 0.080
Loss after mini-batch 1000: 0.083
Loss after mini-batch 1500: 0.079
Loss after mini-batch 2000: 0.090
Loss after mini-batch 2500: 0.075
Loss after mini-batch 3000: 0.089
Loss after mini-batch 3500: 0.081
Loss after mini-batch 4000: 0.069
Loss after mini-batch 4500: 0.086
Loss after mini-batch 5000: 0.085
Loss after mini-batch 5500: 0.091
Loss after mini-batch 6000: 0.085
Training process has finished.
Starting testing
Accuracy: 96 %
Evaluating your PyTorch Lightning model
Today, many engineers who are used to PyTorch are using PyTorch Lightning, a library that runs on top of classic PyTorch and which helps you organize your code. Below, we'll also show you how to evaluate your model when created with PyTorch Lightning.
The model we will evaluate
The PyTorch model that will be used for testing is similar to the one created with classic PyTorch above:
import os
import torch
from torch import nn
from torchvision.datasets import MNIST
from torch.utils.data import DataLoader
from torchvision import transforms
import pytorch_lightning as pl
class MLP(pl.LightningModule):
def __init__(self):
super().__init__()
self.layers = nn.Sequential(
nn.Linear(28 * 28 * 1, 64),
nn.ReLU(),
nn.Linear(64, 32),
nn.ReLU(),
nn.Linear(32, 10)
)
self.ce = nn.CrossEntropyLoss()
def forward(self, x):
return self.layers(x)
def training_step(self, batch, batch_idx):
x, y = batch
x = x.view(x.size(0), -1)
y_hat = self.layers(x)
loss = self.ce(y_hat, y)
self.log('train_loss', loss)
return loss
def test_step(self, batch, batch_idx):
x, y = batch
x = x.view(x.size(0), -1)
y_hat = self.layers(x)
loss = self.ce(y_hat, y)
y_hat = torch.argmax(y_hat, dim=1)
accuracy = torch.sum(y == y_hat).item() / (len(y) * 1.0)
output = dict({
'test_loss': loss,
'test_acc': torch.tensor(accuracy),
})
return output
def configure_optimizers(self):
optimizer = torch.optim.Adam(self.parameters(), lr=1e-4)
return optimizer
Adding evaluation code
Frankly, most of the evaluation code was already added in the code example above. More precisely, in the test_step, we perform a forward pass for each minibatch (batch), compute test loss and accuracy, and return everything as a dictionary.
What remains now is to add the runtime code, which loads the datasets (both training and testing data), sets the seed of the random number generator, initializes the model and the Trainer object, and performs training and evaluation.
if __name__ == '__main__':
# Load the datasets
dataset = MNIST(os.getcwd(), download=True, transform=transforms.ToTensor(), train=True)
dataset_test = MNIST(os.getcwd(), download=True, transform=transforms.ToTensor(), train=False)
# Set seed
pl.seed_everything(42)
# Initialize model and Trainer
mlp = MLP()
trainer = pl.Trainer(auto_scale_batch_size='power', gpus=1, deterministic=True, max_epochs=15)
# Perform training
trainer.fit(mlp, DataLoader(dataset, num_workers=15, pin_memory=True))
# Perform evaluation
trainer.test(mlp, DataLoader(dataset_test, num_workers=15, pin_memory=True))
Results
Running the model and evaluation gives an 96% accuracy again!
``` Epoch 0: 100%|███████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 60000/60000 [09:23<00:00, 106.57it/s, loss=0.0544, v_num=14] Testing: 100%|███████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 10000/10000 [00:46<00:00, 214.89it/s]

Hi, I'm Chris!
I know a thing or two about AI and machine learning. Welcome to MachineCurve.com, where machine learning is explained in gentle terms.
Getting started
Foundation models
Learn how large language models and other foundation models are working and how you can train open source ones yourself.
Keras
Keras is a high-level API for TensorFlow. It is one of the most popular deep learning frameworks.
Machine learning theory
Read about the fundamentals of machine learning, deep learning and artificial intelligence.
Most recent articles
January 2, 2024
What is Retrieval-Augmented Generation?
December 27, 2023
In-Context Learning: what it is and how it works
December 22, 2023
CLIP: how it works, how it's trained and how to use it
Article tags
Most popular articles
February 18, 2020
How to use K-fold Cross Validation with TensorFlow 2 and Keras?
December 28, 2020
Introduction to Transformers in Machine Learning
December 27, 2021
StyleGAN, a step-by-step introduction
July 17, 2019
This Person Does Not Exist - how does it work?
October 26, 2020
Your First Machine Learning Project with TensorFlow 2.0 and Keras
Connect on social media
Connect with me on LinkedIn
To get in touch with me, please connect with me on LinkedIn. Make sure to write me a message saying hi!
Side info
The content on this website is written for educational purposes. In writing the articles, I have attempted to be as correct and precise as possible. Should you find any errors, please let me know by creating an issue or pull request in this GitHub repository.
All text on this website written by me is copyrighted and may not be used without prior permission. Creating citations using content from this website is allowed if a reference is added, including an URL reference to the referenced article.
If you have any questions or remarks, feel free to get in touch.
TensorFlow, the TensorFlow logo and any related marks are trademarks of Google Inc.
PyTorch, the PyTorch logo and any related marks are trademarks of The Linux Foundation.
Montserrat and Source Sans are fonts licensed under the SIL Open Font License version 1.1.
Mathjax is licensed under the Apache License, Version 2.0.