Using ReLU, Sigmoid and Tanh with PyTorch, Ignite and Lightning
January 21, 2021 by Chris
Rectified Linear Unit, Sigmoid and Tanh are three activation functions that play an important role in how neural networks work. In fact, if we do not use these functions, and instead use no function, our model will be unable to learn from nonlinear data.
This article zooms into ReLU, Sigmoid and Tanh specifically tailored to the PyTorch ecosystem. With simple explanations and code examples you will understand how they can be used within PyTorch and its variants. In short, after reading this tutorial, you will...
- Understand what activation functions are and why they are required.
- Know the shape, benefits and drawbacks of ReLU, Sigmoid and Tanh.
- Have implemented ReLU, Sigmoid and Tanh with PyTorch, PyTorch Lightning and PyTorch Ignite.
All right, let's get to work! 🔥
Summary and example code: ReLU, Sigmoid and Tanh with PyTorch
Neural networks have boosted the field of machine learning in the past few years. However, they do not work well with nonlinear data natively - we need an activation function for that. Activation functions take any number as input and map inputs to outputs. As any function can be used as an activation function, we can also use nonlinear functions for that goal.
As results have shown, using nonlinear functions for that purpose ensure that the neural network as a whole can learn from nonlinear datasets such as images.
The Rectified Linear Unit (ReLU), Sigmoid and Tanh activation functions are the most widely used activation functions these days. From these three, ReLU is used most widely. All functions have their benefits and their drawbacks. Still, ReLU has mostly stood the test of time, and generalizes really well across a wide range of deep learning problems.
In this tutorial, we will cover these activation functions in more detail. Please make sure to read the rest of it if you want to understand them better. Do the same if you're interested in better understanding the implementations in PyTorch, Ignite and Lightning. Next, we'll show code examples that help you get started immediately.
Classic PyTorch and Ignite
In classic PyTorch and PyTorch Ignite, you can choose from one of two options:
- Add the activation functions
nn.Sigmoid(),nn.Tanh()ornn.ReLU()to the neural network itself e.g. innn.Sequential. - Add the functional equivalents of these activation functions to the forward pass.
The first is easier, the second gives you more freedom. Choose what works best for you!
import torch.nn.functional as F
# (1). Add to __init__ if using nn.Sequential
def __init__(self):
super().__init__()
self.layers = nn.Sequential(
nn.Linear(28 * 28, 256),
nn.Sigmoid(),
nn.Linear(256, 128),
nn.Tanh(),
nn.Linear(128, 10),
nn.ReLU()
)
# (2). Add functional equivalents to forward()
def forward(self, x):
x = F.sigmoid(self.lin1(x))
x = F.tanh(self.lin2(x))
x = F.relu(self.lin3(x))
return x
With Ignite, you can now proceed and finalize the model by adding Ignite specific code.
PyTorch Lightning
In Lightning, too, you can choose from one of the two options:
- Add the activation functions to the neural network itself.
- Add the functional equivalents to the forward pass.
import torch
from torch import nn
import torch.nn.functional as F
import pytorch_lightning as pl
# (1) IF USED SEQUENTIALLY
class SampleModel(pl.LightningModule):
def __init__(self):
super().__init__()
self.layers = nn.Sequential(
nn.Linear(28 * 28, 256),
nn.Sigmoid(),
nn.Linear(256, 128),
nn.Tanh(),
nn.Linear(128, 56),
nn.ReLU(),
nn.Linear(56, 10)
)
self.ce = nn.CrossEntropyLoss()
def forward(self, x):
return self.layers(x)
# (2) IF STACKED INDEPENDENTLY
class SampleModel(pl.LightningModule):
def __init__(self):
super().__init__()
self.lin1 = nn.Linear(28 * 28, 256)
self.lin2 = nn.Linear(256, 128)
self.lin3 = nn.Linear(128, 56)
self.lin4 = nn.Linear(56, 10)
self.ce = nn.CrossEntropyLoss()
def forward(self, x):
x = F.sigmoid(self.lin1(x))
x = F.tanh(self.lin2(x))
x = F.relu(self.lin3(x))
x = self.lin4(x)
return x
Activation functions: what are they?
Neural networks are composed of layers of neurons. They represent a system that together learns to capture patterns hidden in a dataset. Each individual neuron here processes data in the form Wx + b. Here, x represents the input vector - which can either be the input data (in the first layer) or any subsequent and partially processed data (in the downstream layers). b is the bias and W the weights vector, and they represent the trainable components of a neural network.
Performing Wx + b equals making a linear operation. In other words, the mapping from an input value to an output value is always linear. While this works perfectly if you need a model to generate a linear decision boundary, it becomes problematic when you don't. In fact, when you need to learn a decision boundary that is not linear (and there are many such use cases, e.g. in computer vision), you can't if only performing the operation specified before.
Activation functions come to the rescue in this case. Stacked directly after the neurons, they take the neuron output values and map this linear input to a nonlinear output. By consequence, each neuron, and the system as a whole, becomes capable of learning nonlinear patterns. The exact flow of data flowing through one neuron is visualized below and can be represented by these three steps:
- Input data flows through the neuron, performing the operation
Wx + b. - The output of the neuron flows through an activation function, such as ReLU, Sigmoid and Tanh.
- What the activation function outputs is either passed to the next layer or returned as model output.
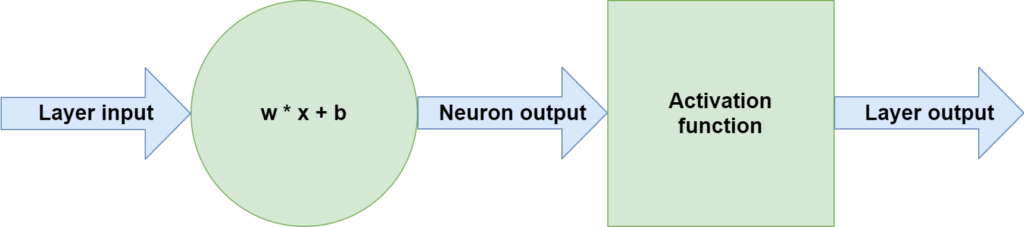
ReLU, Sigmoid and Tanh are commonly used
There are many activation functions. In fact, any activation function can be used - even \(f(x) = x\), the linear or identity function. While you don't gain anything compared to using no activation function with that function, it shows that pretty much anything is possible when it comes to activation functions.
The key consideration that you have to make when creating and using an activation function is the function's computational efficiency. For example, if you would design an activation function that trumps any such function in performance, it doesn't really matter if it is really slow to compute. In those cases, it's more likely that you can gain similar results in the same time span, but then with more iterations and fewer resources.
That's why today, three key activation functions are most widely used in neural networks:
- Rectified Linear Unit (ReLU)
- Sigmoid
- Tanh
Click the link above to understand these in more detail. We'll now take a look at each of them briefly.
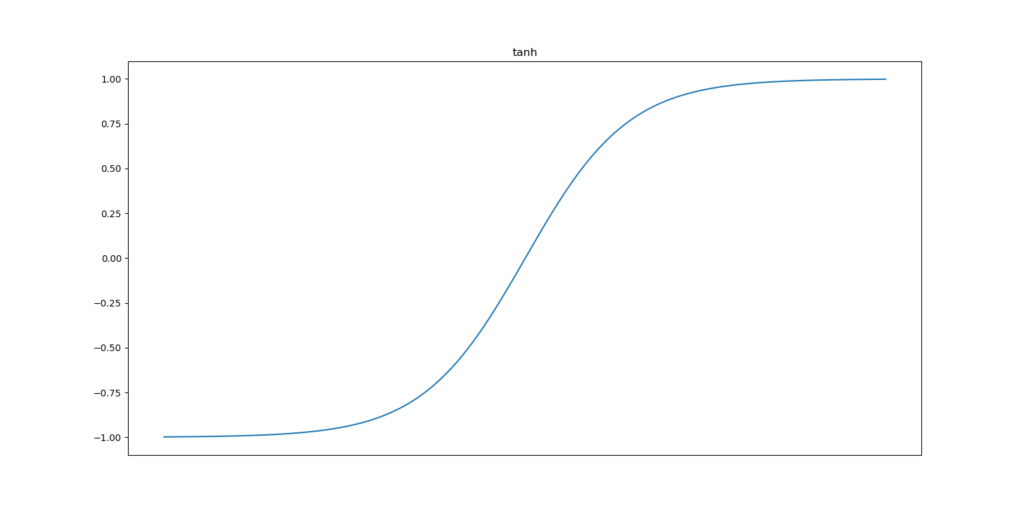
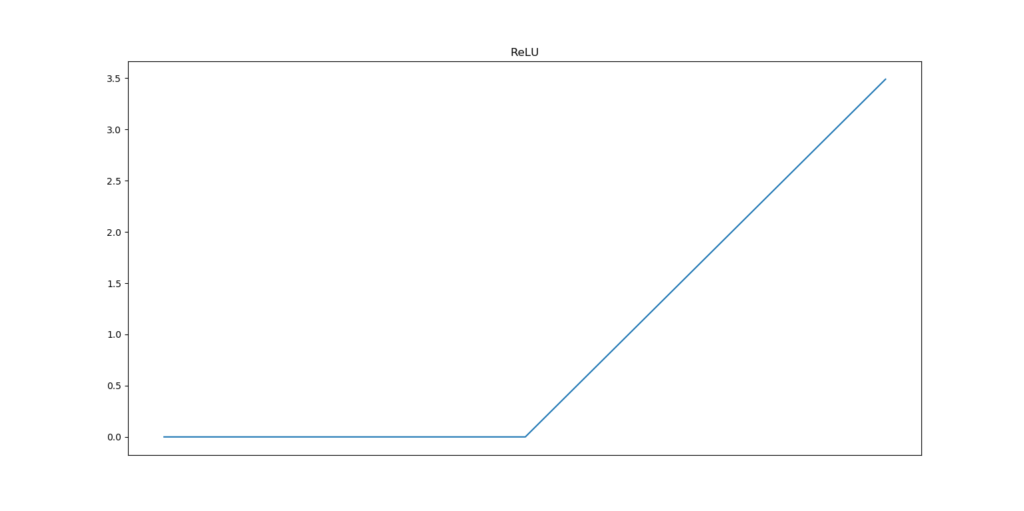
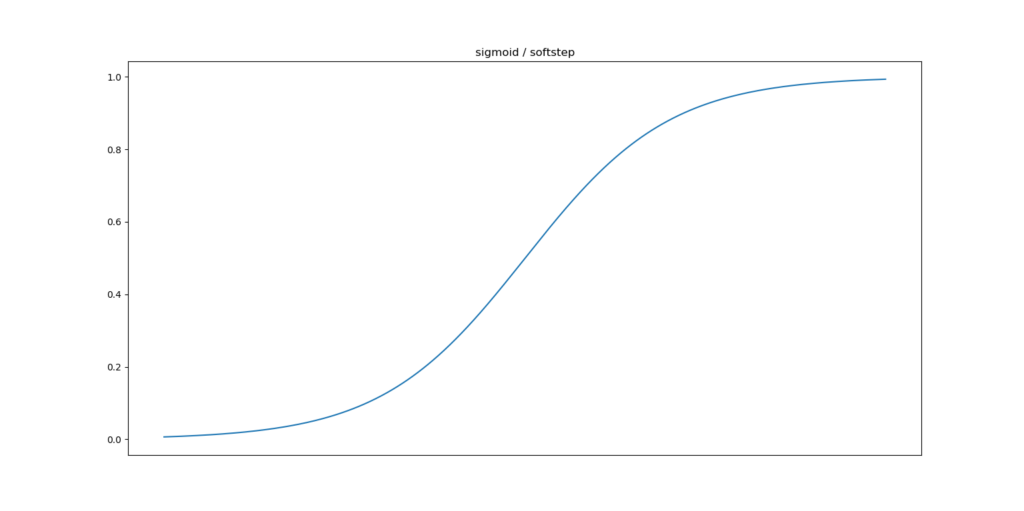
The Tanh and Sigmoid activation functions are the oldest ones in terms of neural network prominence. In the plot below, you can see that Tanh converts all inputs into the (-1.0, 1.0) range, with the greatest slope around x = 0. Sigmoid instead converts all inputs to the (0.0, 1.0) range, also with the greatest slope around x = 0. ReLU is different. This function maps all inputs to 0.0 if x <= 0.0. In all other cases, the input is mapped to x.
While being very prominent, all of these functions come with drawbacks. These are the benefits and drawbacks for ReLU, Sigmoid and Tanh:
- Sigmoid and Tanh suffer greatly from the vanishing gradients problem. This problem occurs because the derivatives of both functions have a peak value at
x < 1.0. Neural networks use the chain rule to compute errors backwards through layers. This chain rule effectively chains and thus multiplies gradients. You can imagine what happens when, wheregis some gradient for a layer, you performg * g * g * .... The result for the most upstream layers is then very small. In other words, larger networks struggle or even fail learning when Sigmoid or Tanh is used. - In addition, with respect to Sigmoid, the middle point in terms of the
yvalue does not lie aroundx = 0. This makes the process somewhat unstable. On the other hand, Sigmoid is a good choice for binary classification problems. Use at your own caution. - Finally with respect to these two, the functions are more complex than that of ReLU, which essentially boils down to
[max(x, 0)](https://www.machinecurve.com/index.php/question/why-does-relu-equal-max0-x/). Computing them is thus slower than when using ReLU. -
While it seems to be the case that ReLU trumps all activation functions - and it surely generalizes to many problems and is really useful, partially due to its computational effectiveness - it has its own unique set of drawbacks. It's not smooth and therefore not fully differentiable, neural networks can start to explode because there is no upper limit on the output, and using ReLU also means opening up yourself to the dying ReLU problem. Many activation functions attempting to resolve these problems have emerged, such as Swish, PReLU and Leaky ReLU - and there are many more. But for some reason, they haven't been able to dethrone ReLU yet, and it is still widely used.
-
-
-



Implementing ReLU, Sigmoid and Tanh with PyTorch
Now that we understand how ReLU, Sigmoid and Tanh work, we can take a look at how we can implement with PyTorch. In this tutorial, you'll learn to implement these activation functions with three flavors of PyTorch:
- Classic PyTorch. This is where it all started and it is PyTorch as we know it.
- PyTorch Ignite. Ignite is a PyTorch-supported approach to streamline your models in a better way.
- PyTorch Lightning. The same is true for Lightning, which focuses on model organization and automation even more.
Let's start with classic PyTorch.
Classic PyTorch
In classic PyTorch, the suggested way to create a neural network is using a class that utilizes nn.Module, the neural networks module provided by PyTorch.
class Model(nn.Module):
def __init__(self):
super(Model, self).__init__()
self.lin1 = nn.Linear(28 * 28, 256),
self.lin2 = nn.Linear(256, 128)
self.lin3 = nn.Linear(128, 10)
You can also choose to already stack the layers on top of each other, like this, using nn.Sequential:
import torch.nn.functional as F
class Model(nn.Module):
def __init__(self):
super(Model, self).__init__()
self.layers = nn.Sequential(
nn.Linear(28 * 28, 256),
nn.Linear(256, 128),
nn.Linear(128, 10)
)
As you can see, this way of working resembles that of the tensorflow.keras.Sequential API, where you add layers on top of each other using model.add.
Adding activation functions
In a nn.Module, you can then add a forward definition for the forward pass. The implementation differs based on the choice of building your neural network from above:
# If stacked on top of each other
def forward(self, x):
return self.layers(x)
# If stacked independently
def forward(self, x):
x = self.lin1(x)
x = self.lin2(x)
return self.lin3(x)
Adding Sigmoid, Tanh or ReLU to a classic PyTorch neural network is really easy - but it is also dependent on the way that you have constructed your neural network above. When you are using Sequential to stack the layers, whether that is in __init__ or elsewhere in your network, it's best to use nn.Sigmoid(), nn.Tanh() and nn.ReLU(). An example can be seen below.
If instead you are specifying the layer composition in forward - similar to the Keras Functional API - then you must use torch.nn.functional, which we import as F. You can then wrap the layers with the activation function of your choice, whether that is F.sigmoid(), F.tanh() or F.relu(). Quite easy, isn't it? :D
import torch.nn.functional as F
# Add to __init__ if using nn.Sequential
def __init__(self):
super().__init__()
self.layers = nn.Sequential(
nn.Linear(28 * 28, 256),
nn.Sigmoid(),
nn.Linear(256, 128),
nn.Tanh(),
nn.Linear(128, 10),
nn.ReLU()
)
# Add functional equivalents to forward()
def forward(self, x):
x = F.sigmoid(self.lin1(x))
x = F.tanh(self.lin2(x))
x = F.relu(self.lin3(x))
return x
PyTorch Ignite
You can use the classic PyTorch approach from above for adding Tanh, Sigmoid or ReLU to PyTorch Ignite. Model creation in Ignite works in a similar way - and you can then proceed adding all Ignite specific functionalities.
PyTorch Lightning
In Lightning, you can pretty much repeat the classic PyTorch approach - i.e. use nn.Sequential and specify calling the whole system in the forward() definition, or create the forward pass yourself. The first is more restrictive but easy, whereas the second gives you more freedom for creating exotic models at the cost of increasing difficulty.
Here's an example of using ReLU, Sigmoid and Tanh when you stack all layers independently and configure data flow yourself in forward:
import torch
from torch import nn
import torch.nn.functional as F
import pytorch_lightning as pl
class SampleModel(pl.LightningModule):
# IF STACKED INDEPENDENTLY
def __init__(self):
super().__init__()
self.lin1 = nn.Linear(28 * 28, 256)
self.lin2 = nn.Linear(256, 128)
self.lin3 = nn.Linear(128, 56)
self.lin4 = nn.Linear(56, 10)
self.ce = nn.CrossEntropyLoss()
def forward(self, x):
x = F.sigmoid(self.lin1(x))
x = F.tanh(self.lin2(x))
x = F.relu(self.lin3(x))
x = self.lin4(x)
return x
def training_step(self, batch, batch_idx):
x, y = batch
x = x.view(x.size(0), -1)
y_hat = self.layers(x)
loss = self.ce(y_hat, y)
self.log('train_loss', loss)
return loss
def configure_optimizers(self):
optimizer = torch.optim.Adam(self.parameters(), lr=1e-3)
return optimizer
Do note that the functional equivalents of Tanh and Sigmoid are deprecated and may be removed in the future:
UserWarning: nn.functional.sigmoid is deprecated. Use torch.sigmoid instead.
warnings.warn("nn.functional.sigmoid is deprecated. Use torch.sigmoid instead.")
UserWarning: nn.functional.tanh is deprecated. Use torch.tanh instead.
warnings.warn("nn.functional.tanh is deprecated. Use torch.tanh instead.")
The solution would be as follows. You can also choose to use nn.Sequential and add the activation functions to the model itself:
import torch
from torch import nn
import torch.nn.functional as F
import pytorch_lightning as pl
class SampleModel(pl.LightningModule):
# IF USED SEQUENTIALLY
def __init__(self):
super().__init__()
self.layers = nn.Sequential(
nn.Linear(28 * 28, 256),
nn.Sigmoid(),
nn.Linear(256, 128),
nn.Tanh(),
nn.Linear(128, 56),
nn.ReLU(),
nn.Linear(56, 10)
)
self.ce = nn.CrossEntropyLoss()
def forward(self, x):
return self.layers(x)
def training_step(self, batch, batch_idx):
x, y = batch
x = x.view(x.size(0), -1)
y_hat = self.layers(x)
loss = self.ce(y_hat, y)
self.log('train_loss', loss)
return loss
def configure_optimizers(self):
optimizer = torch.optim.Adam(self.parameters(), lr=1e-3)
return optimizer
That's it, folks! As you can see, adding ReLU, Tanh or Sigmoid to any PyTorch, Ignite or Lightning model is a piece of cake. 🍰
If you have any comments, questions or remarks - please feel free to leave a comment in the comments section 💬 I'd love to hear from you. You can also leave your question here.
Thanks for reading MachineCurve today and happy engineering! 😎
References
PyTorch Ignite. (n.d.). Ignite your networks! — ignite master documentation. PyTorch. https://pytorch.org/ignite/
PyTorch Lightning. (2021, January 12). https://www.pytorchlightning.ai/
PyTorch. (n.d.). https://pytorch.org
PyTorch. (n.d.). ReLU — PyTorch 1.7.0 documentation. https://pytorch.org/docs/stable/generated/torch.nn.ReLU.html#torch.nn.ReLU
PyTorch. (n.d.). Sigmoid — PyTorch 1.7.0 documentation. https://pytorch.org/docs/stable/generated/torch.nn.Sigmoid.html#torch.nn.Sigmoid
PyTorch. (n.d.). Tanh — PyTorch 1.7.0 documentation. https://pytorch.org/docs/stable/generated/torch.nn.Tanh.html#torch.nn.Tanh
PyTorch. (n.d.). Torch.nn.functional — PyTorch 1.7.0 documentation. https://pytorch.org/docs/stable/nn.functional.html

Hi, I'm Chris!
I know a thing or two about AI and machine learning. Welcome to MachineCurve.com, where machine learning is explained in gentle terms.
Getting started
Foundation models
Learn how large language models and other foundation models are working and how you can train open source ones yourself.
Keras
Keras is a high-level API for TensorFlow. It is one of the most popular deep learning frameworks.
Machine learning theory
Read about the fundamentals of machine learning, deep learning and artificial intelligence.
Most recent articles
January 2, 2024
What is Retrieval-Augmented Generation?
December 27, 2023
In-Context Learning: what it is and how it works
December 22, 2023
CLIP: how it works, how it's trained and how to use it
Article tags
Most popular articles
February 18, 2020
How to use K-fold Cross Validation with TensorFlow 2 and Keras?
December 28, 2020
Introduction to Transformers in Machine Learning
December 27, 2021
StyleGAN, a step-by-step introduction
July 17, 2019
This Person Does Not Exist - how does it work?
October 26, 2020
Your First Machine Learning Project with TensorFlow 2.0 and Keras
Connect on social media
Connect with me on LinkedIn
To get in touch with me, please connect with me on LinkedIn. Make sure to write me a message saying hi!
Side info
The content on this website is written for educational purposes. In writing the articles, I have attempted to be as correct and precise as possible. Should you find any errors, please let me know by creating an issue or pull request in this GitHub repository.
All text on this website written by me is copyrighted and may not be used without prior permission. Creating citations using content from this website is allowed if a reference is added, including an URL reference to the referenced article.
If you have any questions or remarks, feel free to get in touch.
TensorFlow, the TensorFlow logo and any related marks are trademarks of Google Inc.
PyTorch, the PyTorch logo and any related marks are trademarks of The Linux Foundation.
Montserrat and Source Sans are fonts licensed under the SIL Open Font License version 1.1.
Mathjax is licensed under the Apache License, Version 2.0.