Transformer models like GPT-3 and BERT have been really prominent in today's Natural Language Processing landscape. They have built upon the original Transformer model, which performed sequence-to-sequence tasks, and are capable of performing a wide variety of language tasks such as text summarization and machine translation. Text generation is also one of their capabilities, this is true especially for the models from the GPT model family.
While being very capable, in fact capable of generating human-like text, they also come with one major drawback: they are huge. The size of models like BERT significantly limits their adoption, because they cannot be run on normal machines and even require massive GPU resources to even get them running properly.
In other words: a solution for this problem is necessary. In an attempt to change this, Lan et al. (2019) propose ALBERT, which stands for A Lite BERT. By changing a few things in BERT's architecture, they can create a model that is capable of achieving the same performance as BERT, but only at a fraction of the parameters and hence computational cost.
In this article, we'll explain the ALBERT model. First of all, we're going to take a look at the problem in a bit more detail, by taking a look at BERT's size drawback. We will then introduce the ALBERT model and take a look at the three key differences compared to BERT: factorized embeddings, cross-layer parameter sharing and another language task, namely inter-sentence coherence loss. Don't worry about the technical terms, because we're going to take a look at them in relatively plain English, to make things understandable even for beginners.
Once we know how ALBERT works, we're going to take a brief look at its performance. We will see that it actually works better, and we will also see that this behavior emerges from the changes ALBERT has incorporated.
Let's take a look! 😎
BERT's (and other models') drawback: it's huge
If you want to understand what the ALBERT model is and what it does, it can be a good idea to read our Introduction to the BERT model first.
In that article, we're going to cover BERT in more detail, and we will see how it is an improvement upon the vanilla Transformer proposed in 2017, and which has changed the Natural Language Processing field significantly by showing that language models can be created that rely on the attention mechanism alone.
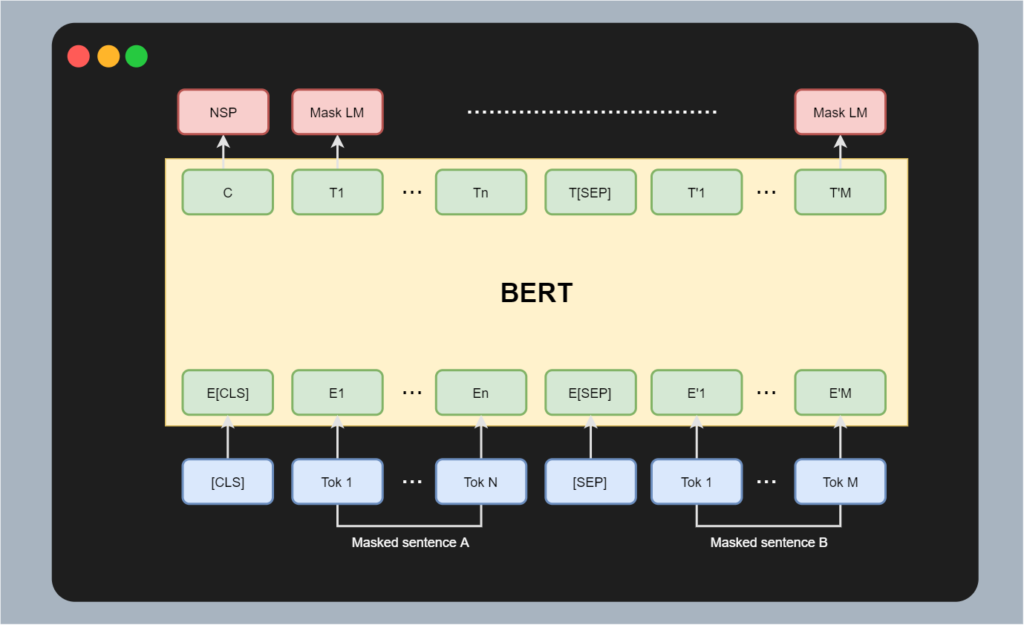
However, let's take a quick look at BERT here as well before we move on. Below, you can see a high-level representation of BERT, or at least its input and outputs structure.
- BERT always takes two sets of tokens as inputs, a sentence A and a sentence B. Note that dependent on the task, sentence B can be empty (i.e. the set of token is empty there) whereas sentence A is filled all the time. This latter scenario happens during regular text classification tasks such as sentiment analysis, whereas with other tasks (such as textual entailment, i.e. learning text directionality) both sentences must be filled.
- Text from sentences A and B is first tokenized. Before the tokens from set A, we add a classification token or
. This token learns to contain sentence-level information based on interactions with the textual tokens in BERT's attention mechanism. The output of the token called C can be used to e.g. fine-tune the model on sentence level tasks. - After
, we add the tokens from sentence A. We then add a separation token and then continue with the tokens from sentence B. In other words, the input to BERT is therefore a set of tokens, with some manual token interventions in between and in front of the textual tokens. - Tokens are fed into BERT, meaning that they are word embedded first. They are then taken through the Transformer model, meaning that attention is computed across tokens, and that the output is a set of vectors representing state.
- BERT utilizes two language tasks for this purpose: a Masked Language Model (MLM) task for predicting output tokens ("given these input tokens, what is the most likely output token" - indeed, it should be the actual next token from the input, but it's the task of the model to learn this). It also utilizes a Next Sentence Prediction (NSP) task to learn sentence-level information available in C.
Previous studies (such as the study creating BERT or the one creating GPT) have demonstrated that the size of language models is related to performance. The bigger the language model, the better the model performs, is the general finding.
Evidence from these improvements reveals that a large network is of crucial importance for achieving state-of-the-art performance
Lam et al. (2019)
While this allows us to build models that really work well, this also comes at a cost: models are really huge and therefore cannot be used widely in practice.
An obstacle to answering this question is the memory limitations of available hardware. Given that current state-of-the-art models often have hundreds of millions or even billions of parameters, it is easy to hit these limitations as we try to scale our models. Training speed can also be significantly hampered in distributed training, as the communication overhead is directly proportional to the number of parameters in the model.
Lam et al. (2019)
Recall that BERT comes in two flavors: a \(\text{BERT}_\text{BASE}\) model that has 110 million trainable parameters, and a \(\text{BERT}_\text{LARGE}\) model that has 340 million ones (Devlin et al., 2018).
This is huge! Compare this to relatively simple ConvNets, which if really small can be < 100k parameters in size.
The effect, as suggested above, is that scaling models often means that engineers run into resource limits during deployment. There is also an impact on the training process, especially when training is distributed (i.e. across many machines), because the computational overhead of distributed training strategies can be really big, especially with so many parameters.
In their work, Lam et al. (2019) have tried to answer one question in particular: Is having better NLP models as easy as having larger models? As a result, they come up with a better BERT design, yielding a drop in parameters with only a small loss in terms of performance. Let's now take a look at ALBERT, or a lite BERT.
ALBERT, A Lite BERT
And according to them, the answer is a clear no - better NLP models does not necessarily mean that models must be bigger. In their work, which is referenced below as Lam et al. (2019) including a link, they introduce A Lite BERT, nicely abbreviated to ALBERT. Let's now take a look at it in more detail, so that we understand why it is smaller and why it supposedly works just as well, and perhaps even better when scaled to the same number of parameters as BERT.

From the paper, we come to understand that ALBERT simply utilizes the BERT architecture. This architecture, which itself is the encoder segment from the original Transformer (with only a few minor tweaks), is visible in the image on the right. It is changed in three key ways, which bring about a significant reduction in parameters:
- Key difference 1: embeddings are factorized, decomposing the parameters of embedding into two smaller matrices in addition to adaptations to embedding size and hidden state size.
- Key difference 2: ALBERT applies cross-layer parameter sharing. In other words, parameters between certain subsegments from the (stacked) encoder segments are shared, e.g. the parameters of the Multi-head Self-Attention Segment and the Feedforward Segment. This is counter to BERT, which allows these segments to have their own parameters.
- Key difference 3: following post-BERT works which suggest that the Next Sentence Prediction (NSP) task utilized by BERT actually underperforms compared to what the model should be capable of, Lam et al. (2019) introduce a sentence-order prediction (SOP) loss task that actually learns about sentence coherence.
If things are not clear by now, don't worry - that was expected :D We're going to take a look at each difference in more detail next.
Key difference 1: factorized embedding parameters
The first key difference between the BERT and ALBERT models is that parameters of the word embeddings are factorized.
In mathematics, factorization (...) or factoring consists of writing a number or another mathematical object as a product of several factors, usually smaller or simpler objects of the same kind. For example, 3 × 5 is a factorization of the integer 15
Wikipedia (2002)
Factorization of these parameters is achieved by taking the matrix representing the weights of the word embeddings \(E\) and decomposing it into two different matrices. Instead of projecting the one-hot encoded vectors directly onto the hidden space, they are first projected on some-kind of lower-dimensional embedding space, which is then projected to the hidden space (Lan et al, 2019). Normally, this should not produce a different result, but let's wait.
Another thing that actually ensures that this change reduces the number of parameters is that the authors suggest to reduce the size of the embedding matrix. In BERT, the shape of the vocabulary/embedding matrix E equals that of the matrix for the hidden state H. According to the authors, this makes no sense from both a theoretical and a practical point of view.
First of all, theoretically, the matrix E captures context-independent information (i.e. a general word encoding) whereas the hidden representation H captures context-dependent information (i.e. related to the dataset with which is trained). According to Lan et al. (2019), BERT's performance emerges from using context to learn context-dependent representations. The context-independent aspects are not really involved. For this reason, they argue, \(\text{H >> E}\) (H must be a lot greater than E) in order to make things more efficient.
The authors argue that this is also true from a practical point of view. When \(\text{E = H}\), increasing the hidden state (and hence the capability for BERT to capture more contextual details) also increases the size of the matrix for E, which makes no sense, as it's context-independent. By consequence, models with billions of parameters become possible, most of which are updated only sparsely during training (Lan et al, 2019).
In other words, a case can be made that this is not really a good idea.
Recall that ALBERT solves this issue by decomposing the embedding parameters into two smaller matrices, allowing a two-step mapping between the original word vectors and the space of the hidden state. In terms of computational cost, this no longer means \(\text{O(VxH)}\) but rather \(\text{O(VxE + ExH)}\), which brings a significant reduction when \(\text{H >> E}\).
Key difference 2: cross-layer parameter sharing
The next key difference is that between encoder segments, layer parameters are shared for every similar subsegment.
This means that e.g. with 12 encoder segments:
- The multi-head self-attention subsegments share parameters (i.e. weights) across all twelve layers.
- The same is true for the feedforward segments.
The consequence of this change is that the number of parameters is reduced significantly, simply because they are shared. Another additional benefit reported by Lan et al. (2019) is that something else can happen that is beyond parameter reduction: the stabilization of the neural network due to parameter sharing. In other words, beyond simply reducing the computational cost involved with training, the paper suggests that sharing parameters can also improve the training process.
Key difference 3: inter-sentence coherence loss
The third and final key difference is that instead of Next Sentence Prediction (NSP) loss, an inter-sentence coherence loss called sentence-order prediction (SOP) is used.
The authors, based on previous findings that themselves are based on evaluations of the BERT model, argue that the NSP task can be unreliable. The key problem with this loss is that it merges topic prediction and coherence prediction into one task. Recall that NSP was added to BERT to predict whether two sentences are related (i.e. whether sentence B is actually the next sentence for sentence A or whether it is not). This involves both looking at the topic ("what is this sentence about?") and some measure of coherence ("how related are the sentences?").
Intuitively, we can argue that topic prediction is much easier than coherence prediction. The consequence is that when the model discovers this, it can focus entirely on this subtask, and forget about the coherence prediction task; actually taking the path of least resistance. The authors actually demonstrate that this is happening with the NSP task, replacing it within their work with a sentence-order prediction or SOP task.
This task focuses on coherence prediction only. It utilizes the same technique as BERT (i.e. the passing of two consecutive segments), but is different because it doesn't take a random sentence in the case where the sentence ('is not next'). Rather, it simply swaps sentences that are always consecutive, effectively performing a related next sentence prediction problem focused entirely on coherence. It enforces that the model zooms into the hard problem instead of the difficult one.
Training ALBERT: high performance at lower cost
Now that we understand how ALBERT works and what the key differences are, let's take a look at how it is trained.
Various configurations
In the Lan et al. paper from 2019, four ALBERT types are mentioned and compared to the two BERT models.
We can see that the ALBERT base model attempts to mimic BERT base, with a hidden state size of 768, parameter sharing and a smaller embedding size due to factorization explained above. Contrary to the 108 million parameters, it has only 12 million. This makes a big difference when training the model.
Another model, ALBERT xxlarge (extra-extra large) has 235 million parameters, with 12 encoder segments, 4096-dimensional hidden state and 128-dimensional embedding size. It also includes parameter sharing. In theory, the context-dependent aspects of the model should be more performant than original BERT, since the hidden state is bigger. Let's now see whether this is true.
| Model | Type | No. Parameters | No. Encoder Segments | Hidden State Size | Embedding Size | Parameter Sharing | |

Hi, I'm Chris!
I know a thing or two about AI and machine learning. Welcome to MachineCurve.com, where machine learning is explained in gentle terms.
Getting started
Foundation models
Learn how large language models and other foundation models are working and how you can train open source ones yourself.
Keras
Keras is a high-level API for TensorFlow. It is one of the most popular deep learning frameworks.
Machine learning theory
Read about the fundamentals of machine learning, deep learning and artificial intelligence.
Most recent articles
January 2, 2024
What is Retrieval-Augmented Generation?
December 27, 2023
In-Context Learning: what it is and how it works
December 22, 2023
CLIP: how it works, how it's trained and how to use it
Article tags
Most popular articles
February 18, 2020
How to use K-fold Cross Validation with TensorFlow 2 and Keras?
December 28, 2020
Introduction to Transformers in Machine Learning
December 27, 2021
StyleGAN, a step-by-step introduction
July 17, 2019
This Person Does Not Exist - how does it work?
October 26, 2020
Your First Machine Learning Project with TensorFlow 2.0 and Keras
Connect on social media
Connect with me on LinkedIn
To get in touch with me, please connect with me on LinkedIn. Make sure to write me a message saying hi!
Side info
The content on this website is written for educational purposes. In writing the articles, I have attempted to be as correct and precise as possible. Should you find any errors, please let me know by creating an issue or pull request in this GitHub repository.
All text on this website written by me is copyrighted and may not be used without prior permission. Creating citations using content from this website is allowed if a reference is added, including an URL reference to the referenced article.
If you have any questions or remarks, feel free to get in touch.
TensorFlow, the TensorFlow logo and any related marks are trademarks of Google Inc.
PyTorch, the PyTorch logo and any related marks are trademarks of The Linux Foundation.
Montserrat and Source Sans are fonts licensed under the SIL Open Font License version 1.1.
Mathjax is licensed under the Apache License, Version 2.0.