Transformers are taking the world of NLP by storm. After being introduced in Vaswani et al.'s Attention is all you need work back in 2017, they - and particularly their self-attention mechanism requiring no recurrent elements to be used anymore - have proven to show state-of-the-art performance on a wide variety of language tasks.
Nevertheless, what's good can still be improved, and this process has been applied to Transformers as well. After the introduction of the 'vanilla' Transformer by Vaswani and colleagues, a group of people at OpenAI have used just the decoder segment and built a model that works great. However, according to Devlin et al., the authors of a 2018 paper about pretrained Transformers in NLP, they do one thing wrong: the attention that they apply is unidirectional.
This hampers learning unnecessarily, they argue, and they proposed a bidirectional variant instead: BERT, or Bidirectional Encoder Representations from Transformers. It is covered in this article. Firstly, we'll briefly take a look at finetuning-based approaches in NLP, which is followed by BERT as well. It is necessary to get sufficient context for reading about how BERT works: we'll cover both the architecture i.e. the what and how BERT is trained i.e. the why. This includes a detailed look at how the inputs to a BERT model must be constructed.
You'll take away from this article:
- Understanding how fine-tuning approaches are different from feature-based approaches.
- How inputs to BERT are structured.
- How BERT works.
Let's take a look! 😎
Finetuning-based approaches in NLP
A BERT Transformer follows the so-called finetuning-based approach in Natural Language Processing. It is different than the feature-based approach, which is also used commonly, and more thoroughly in older language models or models that haven't been pretrained.
Because pretraining is tightly coupled to finetuning, in the sense that they are very much related. Let's take a look at this approach in more detail and then compare it with the feature-based approach also mentioned above.
If you take a look at the image below, you'll see a schematic representation of a finetuning-based approach in NLP. Note that we will be using the same model architecture and often the same model for all the tasks, visualized in green. The yellow blocks represent model states, and specifically the state of weights when we're talking about neural networks.
Of course, we start with a neural network thas has been initialized pseudorandomly. We'll then train it using an unlabeled corpus, which is often big. The task performed is often language modeling: is the predicted next token actually the next token? It allows us to use large, unlabeled datasets to train a model that can detect very generic linguistic patterns in text: the pretrained model.
We do however often want to create a machine learning model that can perform one task really well. This is where finetuning comes in: using a labeled corpus, which is often smaller, we can then train the pretrained model further, with an additional or replacing NLP task. The end result is a model that has been pretrained on the large unlabeled corpus and which is finetuned to a specific language task, such as summarization, text generation in a particular domain, or translation.

Finetuning-based approaches are different to feature-based approaches, which use pretrained models to generate features that are then used as features in a separate model. In other words, with finetuning, we train using the same model all the time, whereas in a feature-based approach we chain two models together in a pipeline, allowing joint training to occur.
Performing pretraining allows us to use unlabeled datasets. This is good news, because labeling data is expensive, and by consequence most datasets that are labeled are small. Training a machine learning model however requires large datasets for sufficient generalization. Combining unlabeled and labeled data into a semi-supervised approach, with pretraining and finetuning, allows us to benefit from the best of both worlds.
Let's now take a look at how BERT utilizes finetuning for achieving significant capabilities on language tasks.
How BERT works: an introduction
BERT was introduced in a 2018 paper by Devlin et al. called Bert: Pre-training of deep bidirectional transformers for language understanding. BERT, which stands for Bidirectional Encoder Representations from Transformers, is today widely used within Google Search, to give just one example.
Let's take a look at how it works. Firstly, we'll cover the why: we will see that BERT was proposed to overcome the issue of unidirectionality in previous Transformer approaches, such as GPT. Then, we'll take a look at the Transformer encoder segment, which BERT borrows from the original Transformer proposed by Vaswani et al. (2017). Then, we'll take a look at how BERT is pretrained, as well as how it can be finetuned across many language understanding tasks.
Why BERT?
One of the first questions that I had when reading the BERT paper was "why"? Why BERT? What makes it better than other approaches, such as the vanilla Transformer proposed by Vaswani et al. (2017) or the GPT model which utilizes the decoder segment of the original Transformer together with pretraining?
The authors argue as follows:
We argue that current techniques restrict the power of the pre-trained representations, especially for the fine-tuning approaches. The major limitation is that standard language models are unidirectional, and this limits the choice of architectures that can be used during pre-training.
Devlin et al. (2018)
What does this mean? We'll have to briefly take a look at e.g. the GPT model to know for sure - why unidirectional models can underperform.
From our article about GPT: "The input is then served to a masked multi-head attention segment, which computes self-attention in a unidirectional way. Here, the residual is added and the result is layer normalized."
Indeed, GPT (which uses the Transformer decoder segment autoregressively during pretraining) and the original Transformer (which performs Seq2Seq), apply a mask in one of the attention modules - the masked multi-head self-attention subsegment in the decoder segment.
For any token, this mask sets the values for any future tokens to infinite, as can be seen in the example below. For example, for the doken "am", "doing ok" is set to minus infinite, so that after applying Softmax activation the attention to future tokens is zero. This ensures
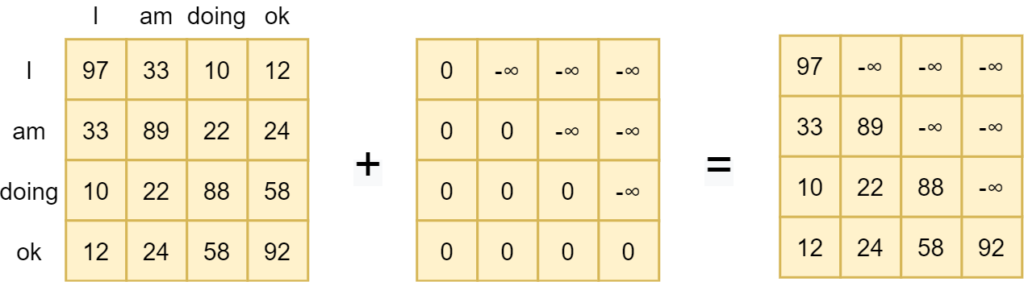
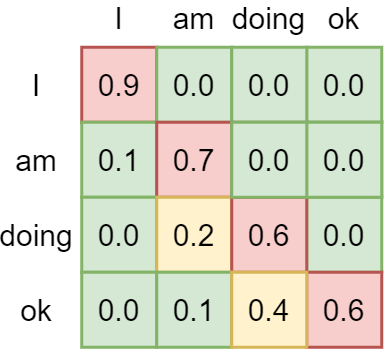
We call this a left-to-right model because attention is applied in a left-to-right fashion: only words to the left of a token are attended to, whereas tokens to the right are ignored. As this is one direction, we call such models unidirectional. Devlin et al. (2018) argue that this is suboptimal or even harmful during finetuning:
For example, in OpenAI GPT, the authors use a left-toright architecture, where every token can only attend to previous tokens in the self-attention layers of the Transformer (…) Such restrictions are sub-optimal for sentence-level tasks, and could be very harmful when applying finetuning based approaches to token-level tasks such as question answering, where it is crucial to incorporate context from both directions.
Devlin et al. (2018)
The why is related to the context that is provided to a token during processing. During pretraining, unidirectionality in language models is not of much concern, given the training task performed by GPT during pretraining ("given all previous tokens, predict the next one" - a strict left-to-right or right-to-left task, depending on the language).
During finetuning, the problem becomes more clear. If we want to finetune to a specific task, not only previous tokens become important, but also future tokens with respect to some token will be. Let's draw a human analogy. If our task is to summarize, we'll first read the text once, which can be compared to the "pretraining step" - because your brain effectively guesses which token (i.e. word) comes next based on what you've read so far.
However, if your finetuning task is then to learn to generate a summary for the particular text, you won't read the text in a left-to-right fashion and then write the summary. Rather, you'll read back and forth, compare context from the past with context from 'the future', i.e. the left and the right, and then write your summary.
That is why Devlin et al. (2018) argue why previous Transformers underperform given what they should be capable of: the masked self-attention layer is not suitable for many finetuning tasks, at least intuitively. And they set out to prove their idea: the creation of a bidirectional language model, where token attention is generated in a bidirectional way.
Say hello to BERT :)
Transformer encoder segment
First: the architecture. Understanding BERT requires you to understand the Vanilla Transformer first, because BERT utilizes the encoder segment of the original Transformer as the architecture.
This segment looks as follows:
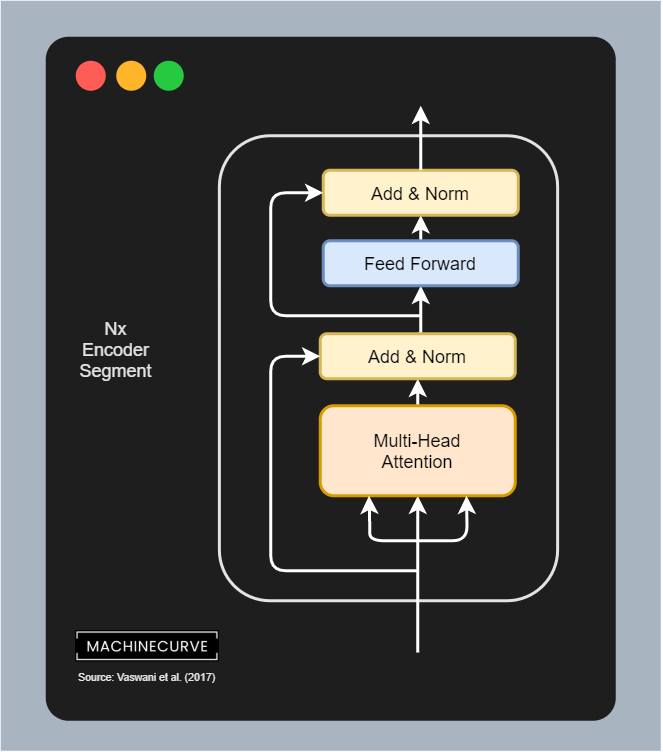
It has two subsegments:
- The multi-head attention segment, which computes self-attention over the inputs, then adds back the residual and layer normalizes everything. The attention head can be split into multiple segments, hence the name multi-head.
- The multi-head attention segment differentiates itself from the masked multi-head attention segment used by the GPT model and is why Devlin et al. (2018) propose BERT. It's exactly the same, except for the mask. In other words, this is how bidirectionality is added to the self-attention mechanism.
- The feedforward segment, which is applied to each individual input, after which the residual and layer normalization is performed once again.
BERT specifically comes in two flavors:
- BERT base (\(\text{BERT}_\text{BASE}\)), which has 12 Encoder Segments stacked on top of each other, has 768-dimensional intermediate state, and utilizes 12 attention heads (with hence 768/12 = 64-dimensional attention heads).
- BERT large (\(\text{BERT}_\text{LARGE}\)), which has 24 Encoder Segments, 1024-dimensional intermediate state, and 16 attention heads (64-dimensional attention heads again).
The models are huge: the BERT base model has 110 million trainable parameters; the BERT large model has 340 million (Devlin et al., 2018). In comparison, classic vanilla ConvNets have hundreds of thousands to a few million. Training them hence requires a lot of resources: in the case of GPT, it's not strange to find that they have to be pretrained for a month using massive machinery, whereas fine-tuning is more cost efficient.
Speaking about training, let's now take a look at how BERT is actually trained.
Data flow through a BERT model: from inputs to outputs
Pretraining a language model like BERT allows us to take a look at two things: the task that is used during pretraining, as well as the datasets used for pretraining.
With respect to the task, we must actually say tasks: during pretraining of BERT, the model is trained for a combination of two tasks. The first task is a Masked Language Model (MLM) task and the second one is a Next Sentence Prediction (NSP) task.
We'll cover the tasks themselves later. If we want to understand them, we must first take a look at what the input to BERT looks like. Put simply: each input to a BERT mode is either a whole sentence or two sentences packed together. All the words are tokenized and (through BERT) converted into a word embedding.
Visually, this input looks as follows. Below the image, we'll cover each component in plain English.
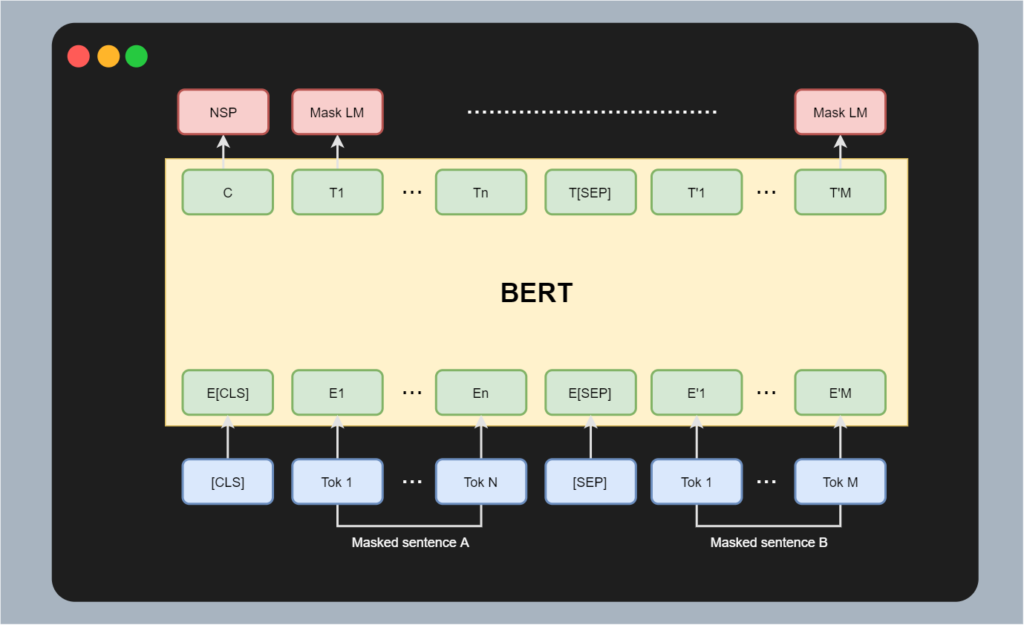
The bottom row represents an array with a variety of tokens. These tokens are separated into four elements:
- A [CLS] token, which is the "classification token". It signals that a new combination is input and its output value can later be used for sentence-level predictions during fine-tuning, as it will learn to contain sentence-level information.
- A Tok 1 ... Tok N ordered list of tokens, containing the tokens from the first sentence.
- A [SEP] token which separates two sentences, if necessary.
- A Tok 1 ... Tok M ordered list of tokens, containing the tokens from the first sentence.
From tokens to embeddings
The first component of the decoder segment (not visualized in the image above) is a word embedding. Word embeddings allow us to tokenized textual inputs (i.e., integers representing tokens) into vector-based format, which decreases dimensionality and hence improves representation. What's more, we can also embed similar words together, which is not possible with other approaches such as one-hot encoding.
BERT utilizes WordPiece embeddings for this purpose, having a 30.000 size word vocabulary (Devlin et al., 2018). The whole sequence from [CLS] to the final Tok M is first embedded within the Transformer, all at once.
BERT outputs
BERT utilizes the encoder segment, meaning that it outputs some vectors \(T_i\) for every token. The first vector, \(T_0\), is also called \(C\) in the BERT paper: it is the "class vector" that contains sentence-level information (or in the case of multiple sentences, information about the sentence pair). All other vectors are vectors representing information about the specific token.
Using outputs in language tasks
In other words, structuring BERT this way allows us to perform sentence-level tasks and token-level tasks. If we use BERT and want to work with sentence-level information, we build on top of the \(C\) token. If we want to perform tasks related to tokens only, we can use the individual tokens. It's a really awesome way to add versatility to a machine learning model.
Pre-training step
Now that we understand how inputs are represented in BERT, we can revisit the tasks for pretraining the model. The first, task 1, is a Masked Language Modeling task, or MLM. The second is a Next Sentence Prediction task, or NSP.
Both are necessary for the model to generalize well across a wide set of tasks during fine-tuning: the Masked Language Modeling task, as we shall see, will allow us to learn token-level information and hence information specific to arbitrary words. The Next Sentence Prediction task however will allow the model to learn sentence-level information through the \(C\) token.
Let's now take a look at each of the tasks in more detail.
Task 1: Masked Language Modeling (MLM)
The first task performed during pretraining is a Masked Language Modeling (MLM) task. It looks like the autoregressive Language Modeling task performed by the GPT model, which involves predicting the next token given the previous tokens, but it is in fact slightly different.
In Masked Language Modeling, an input sequence of tokens is provided, but with some of these tokens masked. The goal of the model is then to learn to predict the correct tokens that are hidden by the mask. If it can do so, it can learn token-level information given the context of the token.
In BERT, this is done as follows. 15% of all word embedded tokens is masked at random. From this 15%, 80% of the tokens is represented with a token called
Task 2: Next Sentence Prediction (NSP)
The other task is Next Sentence Prediction (NSP). This task ensures that the model learns sentence-level information. It is also really simple, and is the reason why the BERT inputs can sometimes be a pair of sentences. NSP involves textual entailment, or understanding the relationship between two sentences.
Next Sentence Prediction, given two sentences A and B, essentially involves predicting whether B is the next sentence given A or whether it is not.
Constructing a training dataset for this task is simple: given an unlabeled corpus, we take a phrase, and take the next one for the 50% of cases where BERT has a next sentence. We take another phase at random given A for the 50% where this is not the case (Devlin et al., 2018). This way, we can construct a dataset where there is a 50/50 split between 'is next' and 'is not next' sentences.
Pre-training data
As we can see from the BERT input structure above, during pretraining, BERT is trained jointly on both the MLM and NSP tasks. We can also see that the input structure supports this through the specific way of inputting data by means of
BERT is pretrained on two datasets. The first dataset that is being used is the BooksCorpus dataset, which contains 800 million words from "more than 7.000 unpublished books. It includes many genres and hence texts from many domains, such as adventure, fantasy and romance", we wrote in our article about GPT, which is pretrained on the same dataset.
BooksCorpus is however not the only dataset that is used for pretraining. The English Wikipedia dataset, with 2500 million words, is used as well. First, all lists, tables, headers and images are removed from the texts, because they have no linguistic representation whatsoever and are specific to Wikipedia (Devlin et al., 2018). Then, the texts are used.
The result is a model that is pretrained and which can be used for fine-tuning tasks.
Fine-tuning step
According to Devlin et al., fine-tuning the BERT architecture is straight-forward. And it actually is, because the way BERT works (i.e. self-attention over all the inputs by nature of the Transformer architecture) and how inputs are structured (i.e. the joint availability of sentence level information and token level information) allows for a wide variety of language tasks to which the model can be fine-tuned.
It thus does not matter whether your downstream task involves single text or text pairs: BERT can handle it. Structuring the text itself is dependent on the task to be performed, and for sentences A and B are similar to (Devlin et al., 2018):
- Sentence pairs in paraphrasing tasks.
- Hypothesis-premise pairs in textual entailment tasks.
- Question-answer pairs in question answering.
- Text-empty pair in text classification.
Yes, you read it right: sentence B is empty if your goal is to fine-tune for text classification. There simply is no sentence after the
Fine-tuning is also really inexpensive (Devlin et al., 2018). Using a Cloud TPU and a standard dataset, fine-tuning can be completed with more than adequate results within an hour. If you're using a GPU, it'll take only a few hours. And fortunately, there are many datasets available to which BERT can be finetuned. In fact, in their work, the authors have achieved state-of-the-art results (at the time) with their model architecture. That's really nice!
Summary
In this article, we provided an intuitive introduction to the BERT model. BERT, which is one of the relatively state-of-the-art approaches in Natural Language Processing these days (in fact, many models have sprung off the original BERT model), works by using the encoder segment from the original Transformer due to its bidirectionality benefits. By performing a joint sentence-level and token-level pretraining task by means of Masked Language Modeling (MLM) and Next Sentence Prediction (NSP), BERT can both be used for downstream task that require sentence-level and/or token-level information.
In other words, the pretrained version of BERT is a really good starting point for your own language related models.
The benefit of BERT compared to previous approaches such as GPT is bidirectionality. In the attention segment, both during pretraining and fine-tuning, the self-attention subsegment does not use a mask for hiding "inputs from the future". The effect is that inputs can both learn from the past and from the future, which can be a necessary thing for many downstream tasks.
I hope that you have learned something from this article! If you did, please feel free to leave a message in the comments section. I'd love to hear from you 💬 If you have questions, please feel free to leave a question through the Ask Questions button above. Where possible, I'll try to answer as soon as I can.
Thank you for reading MachineCurve today and happy engineering! 😎
References
Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A. N., … & Polosukhin, I. (2017). Attention is all you need. Advances in neural information processing systems, 30, 5998-6008.
Devlin, J., Chang, M. W., Lee, K., & Toutanova, K. (2018). Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv preprint arXiv:1810.04805.
Radford, A., Narasimhan, K., Salimans, T., & Sutskever, I. (2018). Improving language understanding by generative pre-training.

Hi, I'm Chris!
I know a thing or two about AI and machine learning. Welcome to MachineCurve.com, where machine learning is explained in gentle terms.
Getting started
Foundation models
Learn how large language models and other foundation models are working and how you can train open source ones yourself.
Keras
Keras is a high-level API for TensorFlow. It is one of the most popular deep learning frameworks.
Machine learning theory
Read about the fundamentals of machine learning, deep learning and artificial intelligence.
Most recent articles
January 2, 2024
What is Retrieval-Augmented Generation?
December 27, 2023
In-Context Learning: what it is and how it works
December 22, 2023
CLIP: how it works, how it's trained and how to use it
Article tags
Most popular articles
February 18, 2020
How to use K-fold Cross Validation with TensorFlow 2 and Keras?
December 28, 2020
Introduction to Transformers in Machine Learning
December 27, 2021
StyleGAN, a step-by-step introduction
July 17, 2019
This Person Does Not Exist - how does it work?
October 26, 2020
Your First Machine Learning Project with TensorFlow 2.0 and Keras
Connect on social media
Connect with me on LinkedIn
To get in touch with me, please connect with me on LinkedIn. Make sure to write me a message saying hi!
Side info
The content on this website is written for educational purposes. In writing the articles, I have attempted to be as correct and precise as possible. Should you find any errors, please let me know by creating an issue or pull request in this GitHub repository.
All text on this website written by me is copyrighted and may not be used without prior permission. Creating citations using content from this website is allowed if a reference is added, including an URL reference to the referenced article.
If you have any questions or remarks, feel free to get in touch.
TensorFlow, the TensorFlow logo and any related marks are trademarks of Google Inc.
PyTorch, the PyTorch logo and any related marks are trademarks of The Linux Foundation.
Montserrat and Source Sans are fonts licensed under the SIL Open Font License version 1.1.
Mathjax is licensed under the Apache License, Version 2.0.