Natural Language Processing is one of the fields where Machine Learning has really boosted progress in the past few years. One of the reasons why there was such progress is of course the Transformer architecture introduced in 2017. However, in addition to that, it's unlikely that you haven't heard about the GPT class of language models. This class, which includes the GPT-2 and GPT-3 architectures, has been attracting global attention since they can produce text which resembles text written by humans.
In fact, Microsoft has acquired an exclusive license to the GPT-3 language model, which will likely give it a prominent role in its cloud environment. In addition to that, many other cloud services using GPT-like models are seeing the light of day. Language models like these can possibly change the world of text in unprecedented ways.
But how does the GPT class of models work? In this article, we'll cover the first model from that range: the OpenAI GPT (i.e. GPT-1) model. It was proposed in a 2018 paper by Radford et al. and produced state-of-the-art at the time. This article will explain the GPT model as intuitively as possible.
It is structured as follows. Firstly, we'll take a look at performing semi-supervised learning in NLP models - i.e., pretraining on large unlabeled corpora (the unsupervised part) and subsequent fine-tuning on relatively small, labeled corporate (the supervised part). Using this approach, it becomes possible to use the large, pretrained model for building a very task-specific model.
Following this is the actual introduction as GPT. We're going to find out how it utilizes the decoder segment of the original Transformer as its base architecture. We will also cover the hyperparameters used for training the decoder segment in pre-training and in fine-tuning. This way, you'll understand how GPT works in detail - without a lot of heavy maths. Looking at fine-tuning, we will also cover the variety of tasks that the GPT model was fine-tuned on, and see how it performs.
Finally, we are going to look at a few extra takeaways of the GPT paper. We'll find out what the effect is of 'locking' certain layers of the pretrained model in terms of performance deterioriation. We'll also see that the pretrained model shows zero-shot behavior, meaning that some performance is achieved when it has not had any fine-tuning. This suggests that the unsupervised language model also learns to recognize linguistic patterns within the text. Finally, we'll compare the performance of Transformer based architectures for semi-supervised learning to that of LSTMs.
How GPT is trained: Semi-supervised learning for NLP
Before we can take a look at how GPT works (and how it is trained precisely), we must take a look at the general approach that it utilizes. According to Radford et al. (2018), GPTs fall under the category of semi-supervised learning.
Our work broadly falls under the category of semi-supervised learning for natural language. This paradigm has attracted significant interest, with applications to tasks like sequence labeling or text classification.
Radford et al. (2018)
Semi-supervised learning is composed of an unsupervised component and a supervised component (hence the name _semi-_supervised). They are the following:
- Pretraining, which is unsupervised, utilizes an unlabeled corpus of (tokenized) text. Here, the goal is not to find a model that works well for a specific task, but rather to find a good initialization point from which to start when learning for a specific task (Radford et al., 2018).
- Fine-tuning, which is supervised, utilizes a labeled corpus of (tokenized) text specifically tailored to a specific language task, such as summarization, text classification or sentiment analysis.
The approach has attracted significant interest because it demonstrates to improve the performance of language models significantly (Radford et al., 2018). One of the key reasons for this observation is that there is a scarcity of labeled datasets; they are often also labeled for one particular domain. Unlabeled text, however, does contain all the patterns, but has no labels. It is also much more abundant compared to labeled text. If we can extract certain linguistic patterns from the unlabeled text, we might find a better starting point from which to specialize further. For this latter job, we can use the labeled but often much smaller dataset.
Semi-supervised learning for natural language has been visualized in the figure below. In green, we can see three tasks: a pretraining task and two finetuning tasks. The pretraining task utilizes a large corpus of unlabeled text to pretrain the model. Using the pretrained model, we can then use different corpora that are task-oriented for finetuning. The outcome is a model that is finetuned to a specific task, but which benefits from pretraining significantly (Radford et al., 2018).

How GPT works: an introduction
Now that we know what semi-supervised learning for natural language involves, we can actually take a look at GPT and how it works. We'll do this in three parts. Firstly, we're going to take a look at the architecture - because we'll need to understand the model that is trained first. The next thing we'll cover is the pre-training task, which is formulated as a language modeling task. Finally, we're going to cover fine-tuning and give you a wide range of example tasks that the pre-trained GPT model can specialize to, as well as the corresponding datasets (Radford et al., 2018).
Using the Transformer decoder segment
From the original article about the Transformer architecture, we know that the version proposed by Vaswani et al. (2017) is composed of an encoder segment and a decoder segment.
The encoder segment converts the original sequence into a hidden and intermediary representation, whereas the decoder segment converts this back into a target sequence. Being a classic Seq2Seq model, the classic Transformer allows us to perform e.g. translation using neural networks.
The GPT based Transformer extends this work by simply taking the decoder segment and stacking it 12 times, like visualized here:

As you can see, it has both the masked multi-head attention segment, the feed forward segment, the residuals and their corresponding addition & layer normalization steps.
This, in other words, means that:
- First, the (learned) embedding is position embedded (which contrary to the classic Transformer is also performed using a learned embedding).
- The input is then served to a masked multi-head attention segment, which computes self-attention in a unidirectional way. Here, the residual is added and the result is layer normalized.
- The result is then passed through a position-wise feedforward network, meaning that every token is passed individually and that the result is merged back together. Once again, the residual is added and the result is layer normalized.
- The outcome either passes to the next decoder segment or is the output of the model as a whole.
Pre-training task
Pretraining of the GPT Transformer is performed with the BooksCorpus dataset. This dataset, which is unfortunately not wholly distributed anymore but can be reconstructed (see the link for more information), contains more than 7.000 unpublished books (Radford et al., 2018). It includes many genres and hence texts from many domains, such as adventure, fantasy and romance.
An excerpt from the corpus, found here, is as follows:
April Johnson had been crammed inside an apartment in San Francisco for two years, as the owners of the building refurbished it, where they took a large three story prewar home and turned it into units small enough where she felt a dog’s kennel felt larger than where she was living and it would be a step up. And with the walls so thin, all she could do was listen to the latest developments of her new neighbors. Their latest and only developments were the sex they appeared to be having late at night on the sofa, on the kitchen table, on the floor, and in the shower. But tonight the recent development occurred in the bed. If she had her way she would have preferred that they didn’t use the bed for sex because for some reason it was next to the paper thin wall which separated her apartment from theirs.
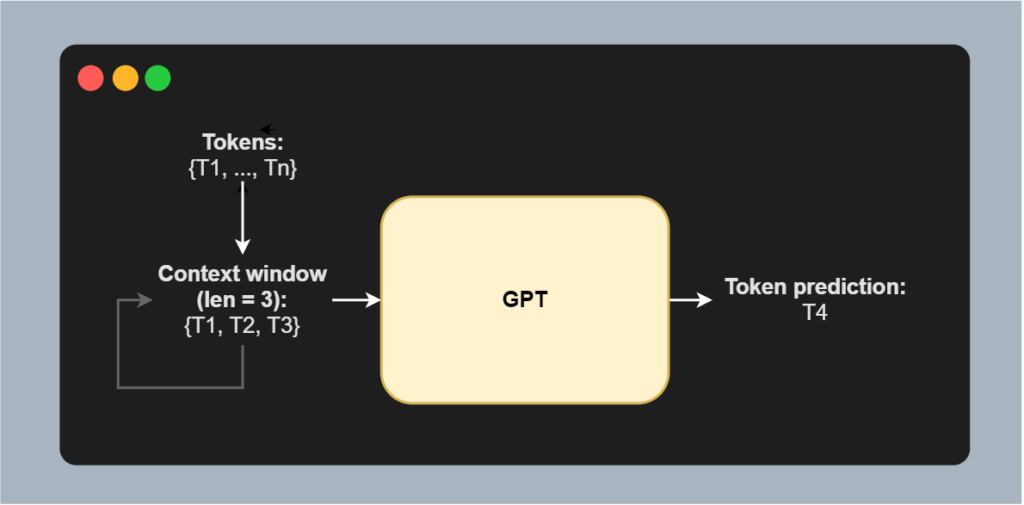
Once more: pretraining happens in an unsupervised way, meaning that there are no labels whatsoever in order to help us steer the training process into the right direction. What we can do with our large corpus of tokens \(\{T_1, ..., T_n\}\) however is applying a (sliding) context window of length \(k\). In other words, we can structure our text into the following windows: \(\{T_1, T_2, T_3\}\), \(\{T_2, T_3, T_4\}\), and so on, here with \(k = 3\).
If we then feed a context window to the GPT model, we can predict the next token - e.g. \(T_4\) in the case of the \(\{T_1, T_2, T_3\}\) window:
The goal is then to maximize the following loss function. Here is what optimization of GPT looks like:
Source: Radford et al. (2018)
This function is a really complex way of writing down the following:

- For each token \(T_i\) (in the formula also called \(u_i\)) in the corpus \(U\), we compute log loss of the probability that it occurs given the context window \(u_{i-k} \rightarrow u_{1-1}\), i.e. the \(k\) tokens prior to token \(i\).
- In plain English, this means: we let the model output the probability that token \(u_i\) is the next token given the context window of length \(k\), and compute log loss for this probability, indicating how off the prediction is.
- In the image on the right, you can see that when the prediction is 100% correct, loss is 0; when it gets worse, loss increases exponentially.
- If we sum this together for all tokens \(i \in U\), we get the loss as a whole and we can perform backpropagation based error computation and subsequent optimization. In fact, GPT is optimized with Adam with a learning rate schedule with a maximum rate of 2.5e-4.
Radford et al. (2018) ran the training process for 100 epochs with a minibatch approach using 64 randomly sampled batches of 512 tokens per batch.
Our approach requires an expensive pre-training step - 1 month on 8 GPUs. (...) The model does fine-tune to new tasks very quickly which helps mitigate the additional resource requirements.
OpenAI (2020)
Environmentally, pretraining the GPT model is not efficient. As you can see above, the whole pretraining operation - the full 100 epochs - cost 1 month and required the full utilization of 8 GPUs. Fortunately, OpenAI released the model weights for the pretrained model jointly with their paper. This means that we can use the pretrained GPT model for fine-tuning to more specific tasks. This, according to OpenAI, can be performed really quickly. That's some better news!
Let's now take a look at how we can use the pretrained model for fine-tuning.
Fine-tuning task
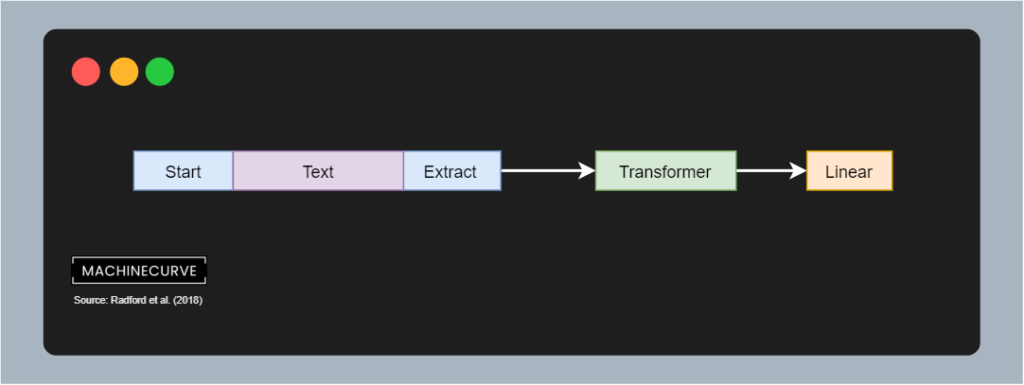
Once the GPT model has been pretrained, it can be finetuned. This involves a labeled dataset, which Radford et al. (2018) call \(C\). Each instance contains a sequence of tokens \(\{x^2, x^2, ..., x^m\}\), as well as a label \(y\). The sequence is passed through the pretrained Transformer architecture, which then is passed through a linear layer with weights \(W_y\) and Softmax activation for multiclass prediction.
In other words, we predict pseudoprobabilities over all the classes (which are task-specific). For example, these are possible tasks and corresponding classes:
- Classification problem (e.g. sentiment analysis): two or more classes (e.g. positive, neutral and negative in the case of sentiment analysis).
- Textual entailment: two classes (is next, is not next).
- Similarity: one class outcome from two options.
- Multiple choice: one class outcome from multiple options.
By taking the argmax of the outcome, we cna find the class that is most likely.
Textual representation during finetuning
We saw above that during fine-tuning text is fed to the Transformer as a sequence of tokens. Obviously, there are many finetuning tasks, four of which have been defined above; they were retrieved from Radford et al.'s work.
As these tasks are all different, we must also represent texts differently when inputting them to the model.
Take classification, with sentiment analysis as an example. When we perform classification, we simply tokenize the text, add a
If the task is related to textual entailment, i.e. showing directionality in text, we structure text slightly differently. First of all, the
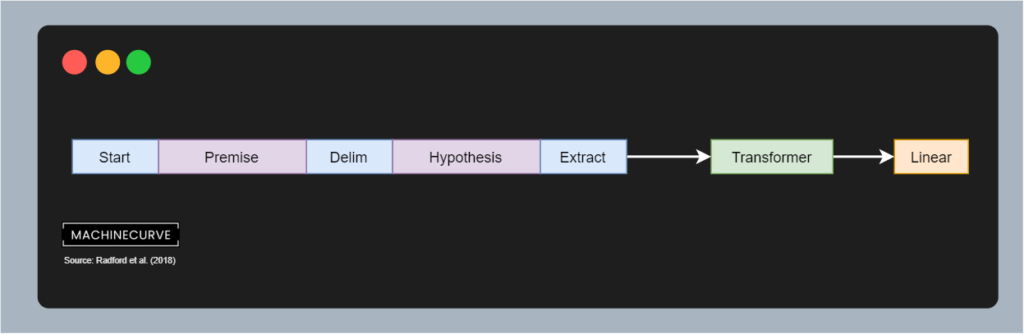
Another use case for GPT is similarity detection. Here, we also see the
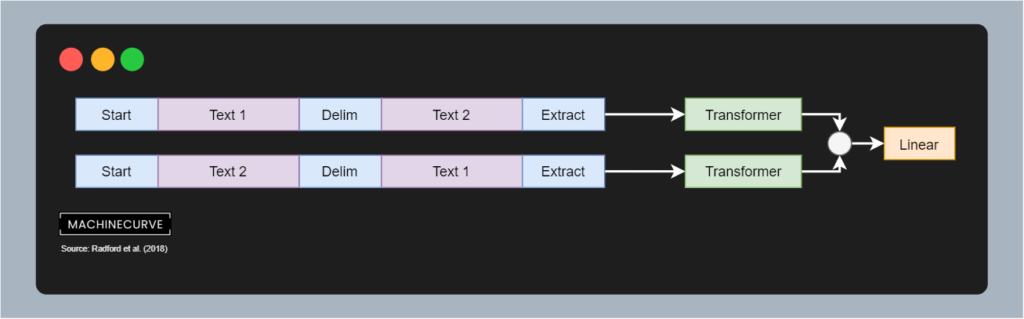
Finally, there's question answering and common sense reasoning. In the case of question answering, a context and answer with corresponding
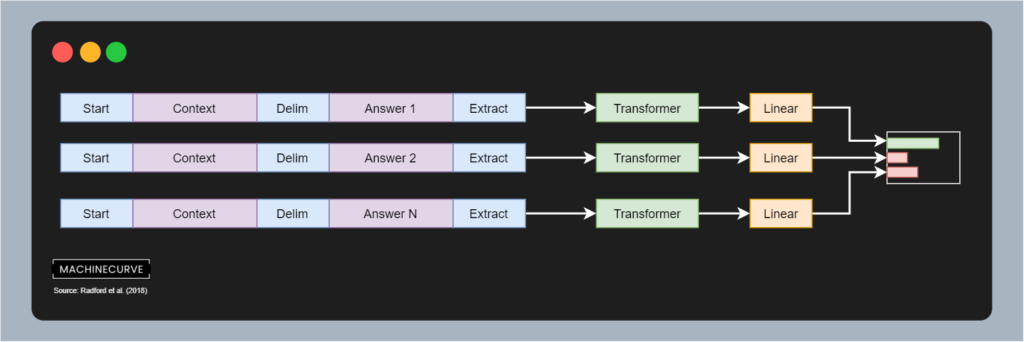
As you can see, the GPT Transformer can be fine-tuned on a wide variety of tasks given the pretrained model. This requires structuring the text a bit differently given the use case and possibly the dataset, but the same architecture and pretrained model can be used over and over again. This is one of the reasons why GPT is used quite widely these days and why it is present in e.g. the HuggingFace Transformers library.
Extra takeaways
Let's now take a look at three extra takeaways from the Radford et al. (2018) papers, which they achieved through ablation studies:
- Whether fine-tuning more layers of the model yields better performance.
- Whether zero-shot learning provides some accuracy. In other words, whether not performing any epochs and measuring the performance of the fine-tuning task yields some performance to begin with. If so, this suggests that the pretrained model itself is capable of understanding some language.
- What the performance differences are between LSTM networks and (GPT based) Transformer ones.
More layers used in finetuning means better performance
First of all, the number of Transformer layers that was fine-tuned. Recall that in any form of transfer learning, it is not necessary that the whole model is transferred. In fact, we can 'lock' certain layers to keep them untouched during fine-tuning. Radford et al. (2018) find that the more layers remain unlocked, the better the fine-tuned model performs. This was not entirely unexpected.
Zero-shot learning provides (some) accuracy
What's more and perhaps more surprising is that zero-shot learning provides some accuracy on a variety of language tasks. Zero-shot learning here means that the model is used for performing the downstream tasks without being finetuned first, i.e. by using the pretrained model.
Surprisingly, this zero-shot approach indicates that the pretrained model performs relatively poorly on the downstream tasks, but does show some performance. This suggests that pretraining supports the learning of a wide variety of task relevant functionality (Radford et al., 2018). In other words, it explains why pretraining does significantly improve language models.
Transformers vs LSTMs
In finding the effectiveness of the GPT Transformer based model, Radford et al. (2018) have also trained a 2048 unit single layer LSTM network. On average, across many of the tasks, the performance of the network dropped significantly when doing so. This clearly demonstrates that Transformer based models in general and GPT in particular does improve performance compared to previous approaches.
Summary
In this article, we have introduced the OpenAI GPT model architecture used for language modeling. It is a Transformer-based approach and one of the many articles that will follow about Transformers and the specific architectures. In doing so, we first saw that GPT based models are trained in a semi-supervised approach, with a general pretraining step followed by task-specific fine-tuning.
We then proceeded by looking at how GPT works: we saw that it uses the decoder segment from the original Transformer, which is pretrained on the BooksCorpus dataset in an autoregressive way. Once pretrained, which takes a significant amount of time (one month!), we can use it to perform specific fine-tuning. There is a wide variety of datasets (including your own) that can be used for this purpose. We did see however that texts must be structured in a particular way when fine-tuning is to be performed. More specifically, we also looked at represent text in the case of classification tasks, textual entailment tasks, question answering tasks and similarity detection tasks.
To finalize, we also appreciated three extra takeaways from the Radford et al. (2018) paper that may be present across many Transformed based approaches. Firstly, we saw that fine-tuning more layers yields better performing models compared to when only one or a few layers (i.e. Transformer segments) are fine-tuned. Secondly, we saw that zero-shot learning (i.e. performing the fine-tuned task with the pretrained model, so without extra finetuning epochs) already provides some performance. This suggests that pretraining really provides the performance boost that we suspected it to provide. Thirdly, and finally, the GPT architecture also demonstrates that the Transformer based architecture performs much better than previous LSTM-based approaches, as was experimentally identified during an ablation study.
I hope that you have learned something from this article. If you did, please feel free to leave a message in the comments section 💬 Please do the same if you have any questions, or use the Ask Questions button on the right. I'd love to hear from you :)
Thank you for reading MachineCurve today and happy engineering! 😎
References
Radford, A., Narasimhan, K., Salimans, T., & Sutskever, I. (2018). Improving language understanding by generative pre-training.
OpenAI. (2020, March 2). Improving language understanding with unsupervised learning. https://openai.com/blog/language-unsupervised/

Hi, I'm Chris!
I know a thing or two about AI and machine learning. Welcome to MachineCurve.com, where machine learning is explained in gentle terms.
Getting started
Foundation models
Learn how large language models and other foundation models are working and how you can train open source ones yourself.
Keras
Keras is a high-level API for TensorFlow. It is one of the most popular deep learning frameworks.
Machine learning theory
Read about the fundamentals of machine learning, deep learning and artificial intelligence.
Most recent articles
January 2, 2024
What is Retrieval-Augmented Generation?
December 27, 2023
In-Context Learning: what it is and how it works
December 22, 2023
CLIP: how it works, how it's trained and how to use it
Article tags
Most popular articles
February 18, 2020
How to use K-fold Cross Validation with TensorFlow 2 and Keras?
December 28, 2020
Introduction to Transformers in Machine Learning
December 27, 2021
StyleGAN, a step-by-step introduction
July 17, 2019
This Person Does Not Exist - how does it work?
October 26, 2020
Your First Machine Learning Project with TensorFlow 2.0 and Keras
Connect on social media
Connect with me on LinkedIn
To get in touch with me, please connect with me on LinkedIn. Make sure to write me a message saying hi!
Side info
The content on this website is written for educational purposes. In writing the articles, I have attempted to be as correct and precise as possible. Should you find any errors, please let me know by creating an issue or pull request in this GitHub repository.
All text on this website written by me is copyrighted and may not be used without prior permission. Creating citations using content from this website is allowed if a reference is added, including an URL reference to the referenced article.
If you have any questions or remarks, feel free to get in touch.
TensorFlow, the TensorFlow logo and any related marks are trademarks of Google Inc.
PyTorch, the PyTorch logo and any related marks are trademarks of The Linux Foundation.
Montserrat and Source Sans are fonts licensed under the SIL Open Font License version 1.1.
Mathjax is licensed under the Apache License, Version 2.0.