Question Answering with Python, HuggingFace Transformers and Machine Learning
December 21, 2020 by Chris
In the last few years, Deep Learning has really boosted the field of Natural Language Processing. Especially with the Transformer architecture which has become a state-of-the-art approach in text based models since 2017, many Machine Learning tasks involving language can now be performed with unprecedented results. Question answering is one such task for which Machine Learning can be used. In this article, we will explore building a Question Answering model pipeline in a really easy way.
It is structured as follows. Firstly, we will take a look at the role of the Transformer architecture in Natural Language Processing. We're going to take a look at what Transformers are and how the encoder-decoder segments from the architecture work together. This includes a look at BERT, which is an extension of the original or vanilla Transformer, only using the encoder segment. Here, we also focus on the prevalent line of thinking in NLP that models must be pretrained on massive datasets and subsequently finetuned to specific tasks.
Jointly, this information provides the necessary context for introducing today's Transformer: a DistilBERT-based Transformer fine-tuned on the Stanford Question Answering Dataset, or SQuAD. It lies at the basis of the practical implementation work to be performed later in this article, using the HuggingFace Transformers library and the question-answering pipeline. HuggingFace Transformers democratize the application of Transformer models in NLP by making available really easy pipelines for building Question Answering systems powered by Machine Learning, and we're going to benefit from that today! :)
Let's take a look! 😎
Update 07/Jan/2021: added more links to relevant articles.
The role of Transformers in Natural Language Processing
Before we dive in on the Python based implementation of our Question Answering Pipeline, we'll take a look at some theory. I always think that Machine Learning should be intuitive and developer driven, but this doesn't mean that we should omit all theory. Rather, I think that having a basic and intuitive understanding of what is going on under the hood will only help in making sound choices with respect to Machine Learning algorithms and architectures that can be used.
For this reason, in this section, we'll be looking at three primary questions:
- What is a Transformer architecture?
- What is this pretraining and fine-tuning dogma?
- What does today's Transformer look like?
What is a Transformer architecture?
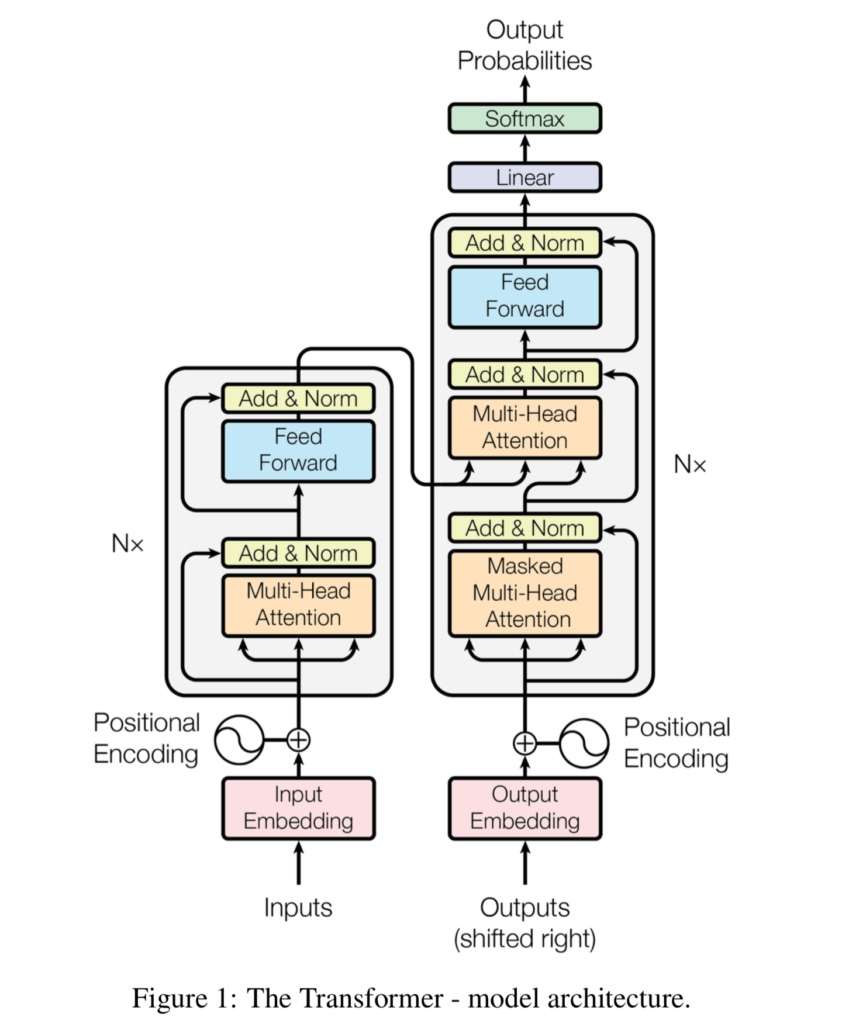
Source: Vaswani et al. (2017)
Back in 2017, researchers and engineers faced a problem when they wanted to train language models.
The state-of-the-art approaches at the time required sequences (such as sentences) to be processed in a sequential, word-by-word fashion. Each word had to be fed to the model individually, after which a prediction about the most likely token emerged. This was the only way in which some source sequences could be converted into corresponding target sequences.
Having solved the issues with respect to vanishing gradients (by means of LSTMs and GRUs) and long-term memory loss (by means of the previous ones as well as the attention mechanism), this was still bugging the Machine Learning communities involved with language models.
Until Vaswani et al. (2017) proposed an approach where the recurrent and hence sequential aspects from the model were removed altogether. In the landmark paper Attention is all you need, the authors outlined that by applying the attention mechanism in a smart way, i.e. in a self-attention fashion, inputs could be processed in parallel without losing the ability for particular inputs to attend to other inputs when generating the target sequence prediction.
This approach, which is called the Transformer architecture, has been a real breakthrough in Natural Language Processing. In fact, thanks to Transformers, LSTM and GRU based models are now no longer considered to be state-of-the-art. Rather, many model architectures have emerged based on the original or vanilla Transformer proposed by Vaswani et al. If you're reading about BERT (driving many Google Searches today) or GPT-based models (such as the exclusive GPT-3 license acquired by Microsoft), you're reading about Transformer-inspired architectures.
Transformers are a smart combination of two segments that work together nicely during the training process. There is an encoder segment which converts inputs, in the vanilla Transformer learned embeddings with positional encoding, into a high-dimensional, intermediate state. This is subsequently fed into the decoder segment, which processes the expected outputs jointly with the encoded inputs into a prediction for the subsequent token. By applying self-attention and doing so in a smart way so that many contexts can be looked at at once (the so-called multi-head attention), Transformers have really ensured that parallelism entered the world of Natural Language Processing.
This finally solved one of the remaining key issues with language models at the time.
Click here if you want to read more about vanilla Transformers. Here, we're going to continue by looking at the BERT architecture.
BERT: Bidirectional Encoder Representations from Transformer
Vanilla Transformers perform both encoding and decoding, meaning that when an input flows through the model, it automatically gets converted into an output prediction. In other words, if I input the English phrase I am doing great today into a model trained for a translation task into Dutch, the output would be Het gaat vandaag geweldig.
Sometimes, we don't want that, especially when we want to perform Transfer Learning activities: what if we can train a model to encode really well based on a really large dataset? If we'd add the decoder segment, there is only a limited opportunity for transfering what has been learned onto one's own Machine Learning task. If we leave the user with the encoded state instead, they can choose how to fine-tune on their own.
BERT
This is one of the key ideas in the BERT architecture, which stands for Bidirectional Encoder Representations from Transformer. It was proposed in a paper written by Devlin et al. (2018) and takes the encoder segment from the vanilla Transformer architecture. With additional changes (such as not taking any learned embeddings but rather WordPiece embeddings, and changing the learning tasks performed during training), a BERT-based model is really good at understanding natural language.
One of the other key changes is that a BERT based model is bidirectional in the sense that it does not only use the context in a left-to-right fashion (which is what vanilla Transformers do). It also does so in a right-to-left fashion - at the same time. This allows models to experience much richer context for generating encodings based on the input values.
Pretraining and fine-tuning
The idea of taking the encoder only is that when it is trained on a massive dataset, it can learn to perform the encoding task in a general way, and do so really well. This is precisely why BERT proposes that models are pretrained on really large datasets and subsequently fine-tuned to specific language tasks. For example, as we have seen in our article about text summarization, a BERT-like encoder can be coupled with a GPT-like decoder and subsequently be fine-tuned to summarization on a dataset related to the task.
Today's Transformer: DistilBERT
Even BERT was not the end station itself. The reason why is its computational intensity: in its two flavors, it has either 110 million parameters (BERT base) or 345 million parameters (BERT large). And that is a huge number, especially if you look at relatively simple ConvNets which have only hundreds of thousands of parameters.
The problem with such large amounts of parameters is that both fine-tuning and inference takes a really long time. If you have to wait seconds for your prediction to return, well, how can we expect to use that model in production?
This is why many approaches have emerged to make computation lighter, just like in Computer Vision - with e.g. the MobileNet architecture, and others. One of these approaches and the one that lies at the basis of today's Transformer-based Question Answering pipeline is the DistilBERT architecture, which was proposed in a 2019 paper by Sanh et al.
Here's the abstract for the work. If you would like to read about DistilBERT in more detail I'd suggest clicking here for the article, but from what the abstract suggests it was made 60% faster by performing a 40% size reduction while retaining 97% of its language understanding. This is a significant improvement and a great optimization with respect to traditional or 'vanilla' BERT.
As Transfer Learning from large-scale pre-trained models becomes more prevalent in Natural Language Processing (NLP), operating these large models in on-the-edge and/or under constrained computational training or inference budgets remains challenging. In this work, we propose a method to pre-train a smaller general-purpose language representation model, called DistilBERT, which can then be fine-tuned with good performances on a wide range of tasks like its larger counterparts. While most prior work investigated the use of distillation for building task-specific models, we leverage knowledge distillation during the pre-training phase and show that it is possible to reduce the size of a BERT model by 40%, while retaining 97% of its language understanding capabilities and being 60% faster. To leverage the inductive biases learned by larger models during pre-training, we introduce a triple loss combining language modeling, distillation and cosine-distance losses. Our smaller, faster and lighter model is cheaper to pre-train and we demonstrate its capabilities for on-device computations in a proof-of-concept experiment and a comparative on-device study.
Sanh et al. (2019)
Fine-tuning DistilBERT on SQuAD
DistilBERT was pretrained on the same datasets as BERT, being "a concatenation of English Wikipedia and Toronto Book Corpus" (Sanh et al., 2019; HuggingFace, n.d.). The general distilled version of BERT was subsequently fine-tuned using the SQuAD dataset, which stands for Stanford Question Answering Dataset (Stanford Question Answering Dataset, n.d.).
Stanford Question Answering Dataset (SQuAD) is a reading comprehension dataset, consisting of questions posed by crowdworkers on a set of Wikipedia articles, where the answer to every question is a segment of text, or span, from the corresponding reading passage, or the question might be unanswerable.
Stanford Question Answering Dataset (n.d.)
A few questions with corresponding answer from this dataset are as follows:
- Q: In what country is Normandy located?
- A: France
- Q: What was the percentage of people that voted in favor of the Pico Act of 1859?
- A: 75
- Q: What is the second busiest airport in the United States?
- A: Los Angeles International Airport
In sum, DistilBERT improves BERT performance and is Transformer inspired. Having been pretrained on a massive dataset (like all BERT models) and subsequently been fine-tuned on the SQuAD dataset, it can be used for answering questions. Let's now take a look at how we can generate an easy Question Answering system with HuggingFace Transformers.
Implementing a Question Answering Pipeline with HuggingFace Transformers
Now that we understand the concepts behind today's Machine Learning pipeline for Question Answering, it's time to actually start building. Today, we're going to build a very easy implementation of a Question Answering system using the HuggingFace Transformers library. This library is becoming increasingly important for democratizing Transformer based approaches in Machine Learning and allows people to use Transformers out-of-the-box.
Let's quickly take a look at building that pipeline.
Full model code
Here it is, the full model code for our Question Answering Pipeline with HuggingFace Transformers:
- From
transformerswe import thepipeline, allowing us to perform one of the tasks that HuggingFace Transformers supports out of the box.- If you don't have
transformersinstalled yet, you can do so easily viapip install transformers. Make sure to have recent versions of PyTorch or TensorFlow installed as well!
- If you don't have
- Subsequently, we specify a
question("What is the capital of the Netherlands?") and provide some context (cited straight from the Wikipedia page about the Netherlands). - We initialize the
question-answeringPipeline allowing us to easily create the Question Answering pipeline, because it utilizes the DistilBERT model fine-tuned to SQuAD. - We then generate the answer from the context-based question, and print it on screen.
from transformers import pipeline
# Open and read the article
question = "What is the capital of the Netherlands?"
context = r"The four largest cities in the Netherlands are Amsterdam, Rotterdam, The Hague and Utrecht.[17] Amsterdam is the country's most populous city and nominal capital,[18] while The Hague holds the seat of the States General, Cabinet and Supreme Court.[19] The Port of Rotterdam is the busiest seaport in Europe, and the busiest in any country outside East Asia and Southeast Asia, behind only China and Singapore."
# Generating an answer to the question in context
qa = pipeline("question-answering")
answer = qa(question=question, context=context)
# Print the answer
print(f"Question: {question}")
print(f"Answer: '{answer['answer']}' with score {answer['score']}")
With one of the recent versions of HuggingFace Transformers, you might run into this issue:
RuntimeError: Expected tensor for argument #1 'indices' to have scalar type Long; but got torch.IntTensor instead (while checking arguments for embedding)
The fix so far is to install the most recent master branch with pip:
pip install git+https://github.com/huggingface/transformers
Et voila, running it now gives:
Question: What is the capital of the Netherlands?
Answer: 'Amsterdam' with score 0.37749919295310974
Brilliant! 😎
Summary
In today's article, we saw how we can build a Question Answering pipeline based on Transformers using HuggingFace Transformers. In doing so, we first looked at what Transformers are in the first place. We saw that by smartly connecting an encoder and decoder segment, removing sequential elements from processing data while keeping the benefits of attention, they have become state-of-the-art in Natural Language Processing.
Moving away from traditional or vanilla Transformers, we looked at the BERT model, and noticed that it only implements the encoder segment - which is pretrained on a large, massive corpus of unlabeled text. It can be fine-tuned and hence be tailor-made to your specific NLP problem. In fact, the emergence of the BERT model has given rise to the dogma of "pretraining and subsequent fine-tuning" that is very common today.
Now, BERT itself is really big: the base version has > 100 million parameters and the large version has > 300 million ones. This is too big for many projects and hence various people have improved BERT; DistilBERT is one such example, yielding only 3% information loss at 40-60% size and speed improvements. It is therefore unsurprising that DistilBERT, which is trained on the same corpus as traditional BERT, is used frequently today. In fact, it is used in the HuggingFace question-answering pipeline that we used for today's question answering model. It is fine-tuned on the Stanford Question Answering Dataset or SQuAD dataset.
In the final section of this article, we saw how we can use HuggingFace Transformers - a library driving democratization of Transformers in NLP - to implement a Question Answering pipeline without a hassle. With just a few lines of code, we generated a pipeline that can successfully answer questions.
I hope that you have learned something from today's article, whether that's how Transformers work, how Question Answering pipelines are pretrained and fine-tuned, or how to use the HuggingFace Transformers library for actual implementations. If you did, please feel free to leave a comment in the comments section below. I'd love to hear from you! 💬 Please do the same if you have any questions, or click the Ask Questions button to the right.
Thank you for reading MachineCurve today and happy engineering! 😎
References
Sanh, V., Debut, L., Chaumond, J., & Wolf, T. (2019). DistilBERT, a distilled version of BERT: smaller, faster, cheaper and lighter. arXiv preprint arXiv:1910.01108.
HuggingFace. (n.d.). Distilbert-base-cased · Hugging face. Hugging Face – On a mission to solve NLP, one commit at a time. https://huggingface.co/distilbert-base-cased
HuggingFace. (n.d.). Distilbert-base-cased-distilled-squad · Hugging face. Hugging Face – On a mission to solve NLP, one commit at a time. https://huggingface.co/distilbert-base-cased-distilled-squad
HuggingFace. (n.d.). Transformers.pipelines — transformers 4.1.1 documentation. Hugging Face – On a mission to solve NLP, one commit at a time. https://huggingface.co/transformers/_modules/transformers/pipelines.html
Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A. N., … & Polosukhin, I. (2017). Attention is all you need. Advances in neural information processing systems, 30, 5998-6008.
Devlin, J., Chang, M. W., Lee, K., & Toutanova, K. (2018). Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv preprint arXiv:1810.04805.
Stanford Question Answering Dataset. (n.d.). The Stanford question answering dataset. Pranav Rajpurkar. https://rajpurkar.github.io/SQuAD-explorer/

Hi, I'm Chris!
I know a thing or two about AI and machine learning. Welcome to MachineCurve.com, where machine learning is explained in gentle terms.
Getting started
Foundation models
Learn how large language models and other foundation models are working and how you can train open source ones yourself.
Keras
Keras is a high-level API for TensorFlow. It is one of the most popular deep learning frameworks.
Machine learning theory
Read about the fundamentals of machine learning, deep learning and artificial intelligence.
Most recent articles
January 2, 2024
What is Retrieval-Augmented Generation?
December 27, 2023
In-Context Learning: what it is and how it works
December 22, 2023
CLIP: how it works, how it's trained and how to use it
Article tags
Most popular articles
February 18, 2020
How to use K-fold Cross Validation with TensorFlow 2 and Keras?
December 28, 2020
Introduction to Transformers in Machine Learning
December 27, 2021
StyleGAN, a step-by-step introduction
July 17, 2019
This Person Does Not Exist - how does it work?
October 26, 2020
Your First Machine Learning Project with TensorFlow 2.0 and Keras
Connect on social media
Connect with me on LinkedIn
To get in touch with me, please connect with me on LinkedIn. Make sure to write me a message saying hi!
Side info
The content on this website is written for educational purposes. In writing the articles, I have attempted to be as correct and precise as possible. Should you find any errors, please let me know by creating an issue or pull request in this GitHub repository.
All text on this website written by me is copyrighted and may not be used without prior permission. Creating citations using content from this website is allowed if a reference is added, including an URL reference to the referenced article.
If you have any questions or remarks, feel free to get in touch.
TensorFlow, the TensorFlow logo and any related marks are trademarks of Google Inc.
PyTorch, the PyTorch logo and any related marks are trademarks of The Linux Foundation.
Montserrat and Source Sans are fonts licensed under the SIL Open Font License version 1.1.
Mathjax is licensed under the Apache License, Version 2.0.