One-Hot Encoding for Machine Learning with Python and Scikit-learn
November 24, 2020 by Chris
Machine Learning models work with numbers. That is, they are mathematical models which improve themselves by performing mathematical optimization. It possibly makes the hype a little bit less fascinating, but it's the truth. Now, when you look at this from a real-world point of view, you might get into a struggle soon when you look at datasets. Datasets are almost never numbers only. For example, if your dataset contains categories, you have no numbers in your dataset. Neither is the case when your dataset contains an ordered list of names, e.g. to illustrate the winners in some kind of competition.
Machine Learning models don't support such data natively.
Fortunately, with one-hot encoding, we can ensure that we can still use these features - simply by converting them into numeric vector format in a smart way. This article illustrates how we can do that with Python and Scikit-learn. Firstly, however, we will look at one-hot encoding in more detail. What is it? Why apply it in the first place? Once we know the answers, we'll move on to the Python example. There, we explain step by step how to use the Scikit-learn OneHotEncoder feature.
What is One-Hot Encoding?
The natural question that we might need to answer first before we move towards a practical implementation is the one related to the what. What is one-hot encoding? And how does it work?
If we look at Wikipedia, we read the following:
In digital circuits and machine learning, a one-hot is a group of bits among which the legal combinations of values are only those with a single high (1) bit and all the others low (0).
Wikipedia (2005)
In other words, if we have a set of bits (recall that these can have 0/1 values only), a one-hot encoded combination means that one of the set is 1 while the others are zero. Hence 'one-hot' encoding: there is one that is 'hot', or activated, while the others are 'cold'.
Let's take a look at an example.
If we want to express the decimal numbers 0-3 into binary format, we see that they can be expressed as a set of two bits: the bits take all forms between 00 and 11 to express the decimal numbers.
| Decimal | Binary | One-hot |
| 0 | 00 | 0001 |
| 1 | 01 | 0010 |
| 2 | 10 | 0100 |
| 3 | 11 | 1000 |
However, this expression does not align with the definition of one-hot encoding: there is no single high in the latter case. If we added more bits, e.g. expressed 7 into binary format (111), we could clearly see that this is a recurring problem.
On the right of the table, we also see the expression of the binary format into one-hot encoded format. Here, the expression ranges from 0001 to 1000, and there is only one hot value per encoding. This illustrates the use of one-hot encoding in expressing values.
Why apply One-Hot Encoding?
Machine Learning models work with numeric data only. That is, they cannot natively accept text data and learn from it. This occurs because of the method with which Machine Learning models are trained. If you are training one in a supervised way, you namely feed forward samples through the model, which generates predictions. You then compare the predictions and the corresponding labels (called ground truth) and compute how bad the model performs. Then, you improve the model, and you repeat the cycle.
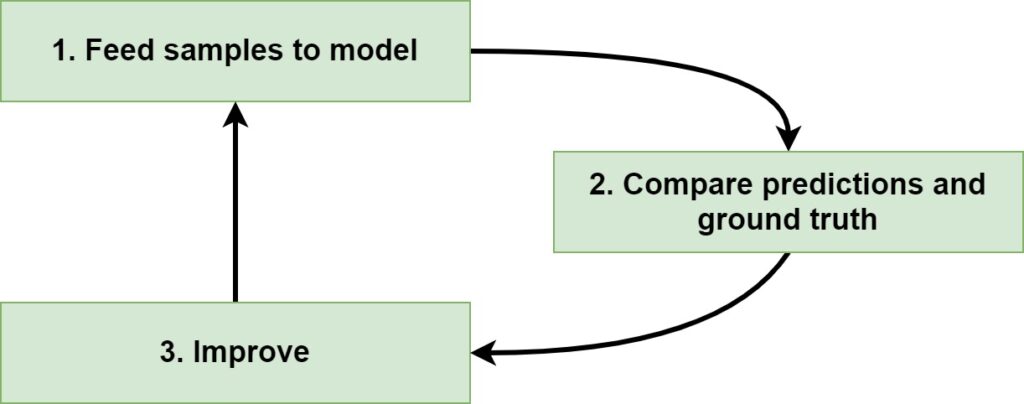
Of course, for the third step, there are many different approaches for improving a Machine Learning model. Many of them are dependent on the algorithm that you are using. In the case of Neural Networks, for example, the contribution of neurons to the loss function can be computed by a technique called backpropagation. If we know the contribution, we also know (by means of a concept called gradients, or the slope of loss change given some change in neuron parameters) into what direction we must change the weights if we want to improve the model.
Then, using an optimizer, we can actually change the weights.
Such operations do however require that data is available in numeric format. The neuron weights are expressed as numbers. For example, this can be a weights vector: \([2.61, 3.92, -2.4, 0.11, 1.11]\). This also means that in step (1), feeding forward samples to models, computations must be made with respect to these weight vectors, in order to learn patterns. In fact, this is the case. An input vector \(\textbf{x}\) to a neuron is multiplied with the weights vector \(\textbf{b}\), after which a bias value - \(b\) - is added. This output is then fed through an activation function and serves as one of the output values of the Neural layer.
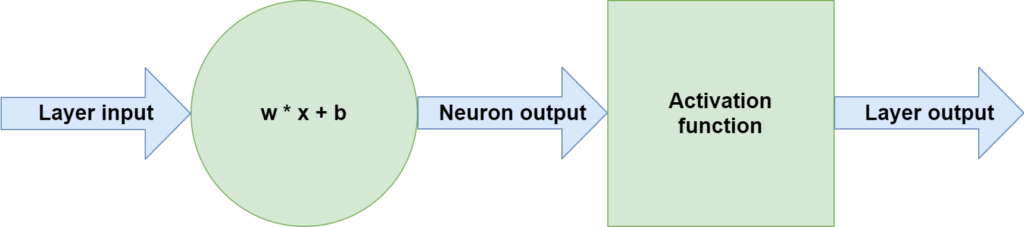
The point, here, is that in order to make the computation, the input / feature vector \(\textbf{x}\) must contain numbers. If it contains text, it will fail: there is no way in which we can multiply numbers (the weights vector) with text (the feature vector).
The problem is that there are many cases where data comes in the form of text - take for example the case of categorical data (Wikipedia, 2012). When data is of this type, it assigns 'groups' to samples - e.g. in the case of a health check. The group variable here is categorical with the possible values being Healthy and Unhealthy.
| Age | Group |
| 12 | Healthy |
| 24 | Unhealthy |
| 54 | Healthy |
| … | … |
Why One-Hot Encoding helps in this case
If you are somewhat creative, you can already start to see the relationships between the previous two sections. Here is the primary one: if you want to express categorical data into numeric format, you can use one-hot encoding for doing so.
Let's take the Group example from the previous section to illustrate how. The case is pretty simple, actually: we can represent the Group values as a set of two bits. For example, if the person is Unhealthy, the category can be expressed as \([0 \ 1]\), while Healthy can be expressed as \([1 \ 0]\). Naturally, we see that we now have a numeric (vector based) representation of our categories, which we can use in our Machine Learning model.
Long story short: one-hot encoding is of great help when solving classification problems.
One-Hot Encoding and multidimensional settings
However, there is a catch when it comes to one-hot encoding your data. Suppose that you have a textual dataset with phrases like this:
- hi there
- i am chris
Applying one-hot encoding to the text can be done as follows:
\([1, 0, 0, 0, 0] \rightarrow \text{hi}\)
\([0, 1, 0, 0, 0] \rightarrow \text{there} \)
\([0, 0, 1, 0, 0] \rightarrow \text{i} \)
\([0, 0, 0, 1, 0] \rightarrow \text{am} \)
\([0, 0, 0, 0, 1] \rightarrow \text{chris} \)
If your corpus is big, this will become problematic, because you get one-hot encoded vectors with many dimensions (here, there are just five). Hence, one-hot encoding is as limited as it is promising: while it can help you fix the issue of textual data with a relatively lower-dimensional case, it is best not to use it when you have many categories or when you want to convert text into numbers. In those cases, learning an Embedding can be the way to go.
A Python Example: One-Hot Encoding for Machine Learning
Now that we know about one-hot encoding and how to apply it in theory, it's time to start using it in practice. Let's take a look at two settings and apply the OneHotEncoder from Scikit-learn. The first setting is a simple one: we simply one-hot encode an array with categorical values, representing the Group feature from a few sections back. The second setting is a more real-world one, where we apply one-hot encoding to the TensorFlow/Keras based MNIST dataset.
Let's take a look.
One-Hot Encoding a NumPy Array
Suppose that we express the Group feautre, with healthy, unhealthy and healthy as a NumPy array. We can then use Scikit-learn for converting the values into a one-hot encoded array, because it offers the sklearn.preprocessing.OneHotEncoder module.
- We first import the
numpymodule for converting a Python list into a NumPy array, and thepreprocessingmodule from Scikit-learn. - We then initialize the
OneHotEncoderand define the data into thehealthvariable. Note the reshaping operation, which is necessary for data that is unidimensional. - We then fit the
healthvariable to theohevariable, which contains theOneHotEncoder. - We then perform a
.transform(..)operation on two elements from the array with features: first, on a Healthy; secondly, on an Unhealthy group member. We expect the outcome to be[1, 0]for the healthy group, and[0, 1]for the unhealthy group. - After the transform, we convert the data into array format and print it to standard output.
import numpy as np
from sklearn import preprocessing
ohe = preprocessing.OneHotEncoder()
health = np.array([['Healthy'], ['Unhealthy'], ['Healthy']]).reshape(-1, 1)
ohe.fit(health)
encoded_healthy = ohe.transform([health[0]]).toarray()
encoded_unhealthy = ohe.transform([health[1]]).toarray()
print(f'Healthy one-hot encoded: {encoded_healthy}')
print(f'Unhealthy one-hot encoded: {encoded_unhealthy}')
And indeed:
Healthy one-hot encoded: [[1. 0.]]
Unhealthy one-hot encoded: [[0. 1.]]
One-Hot Encoding Dataset Targets
Let's now take a look at a real-world dataset. We can load the MNIST dataset, which is a dataset of handwritten numbers, as follows:
from tensorflow.keras.datasets import mnist
(x_train, y_train), (x_test, y_test) = mnist.load_data()
The data looks like this:
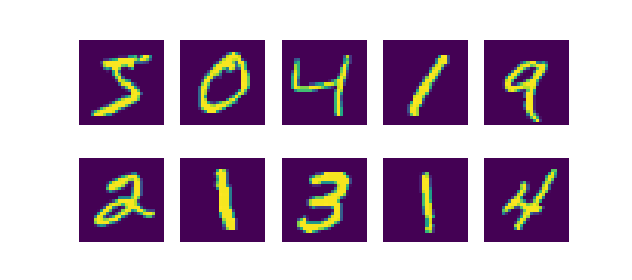
Now let's print one of the y values on screen:
from tensorflow.keras.datasets import mnist
(x_train, y_train), (x_test, y_test) = mnist.load_data()
print(y_test[123])
Outcome: 6. Clearly, the input number belongs to class 6 (and hence represents the number 7, because the classes range from 0-9). However, this does not represent one-hot encoding! If we are to train our Neural network, we can use sparse categorical crossentropy for computing loss in this case. However, if we do want to use categorical crossentropy instead (which makes no sense in this case, but we want to show one-hot encoding, so we go forward with it anyway), we must one-hot encode our feature vectors first.
Let's see how we can do this with Scikit-learn.
- In the imports, we specify NumPy, preprocessing and now also the
mnistimport fromtensorflow.keras.datasets - We then define and initialize the
OneHotEncoder. - We load the MNIST data and then reshape it - the reshape operation is required by Scikit-learn for performing one-hot encoding.
- We then perform fit and transform operations with the
OneHotEncoderinitialization for both the training and the testing segments of our dataset. - We finally print the results for the
yvariable we checked earlier.
import numpy as np
from sklearn import preprocessing
from tensorflow.keras.datasets import mnist
# Define the One-hot Encoder
ohe = preprocessing.OneHotEncoder()
# Load MNIST data
(x_train, y_train), (x_test, y_test) = mnist.load_data()
# Reshape data
y_train = y_train.reshape(-1, 1)
y_test = y_test.reshape(-1, 1)
# Fit and transform training data
ohe.fit(y_train)
transformed_train = ohe.transform(y_train).toarray()
# Fit and transform testing data
ohe.fit(y_test)
transformed_test = ohe.transform(y_test).toarray()
# Print results
print(f'Value without encoding: {y_test[123]}')
print(f'Value with encoding: {transformed_test[123]}')
The result:
Value without encoding: [6]
Value with encoding: [0. 0. 0. 0. 0. 0. 1. 0. 0. 0.]
Since the range of y values ranges from 0-9, we would expect a one-hot encoded vector with ten items - and this is the case. What's more, our y = 6 value is reflected by setting the 7th value (i = 6) in our one-hot encoded array to 1, while the rest remains at 0. Great!
Summary
Machine Learning models require numeric data for training. Sometimes, however, your dataset is not numeric - think about converting text into Machine Learning input, or handling categorical data. In those cases, one-hot encoding can be used for making your Machine Learning dataset usable for your ML projects.
In this article, we looked at applying one-hot encoding. We saw that it involves creating a set of bits where for each unique combination one bit is set to 1 ('hot'), while the others are set to zero ('cold'). For this reason, the technique is called one-hot encoding. We saw that it naturally fits making categorical data usable in Machine Learning problems and can help us significantly when we are solving a classification problem.
In the practical part of this article, we looked at how we can use Python and Scikit-learn to perform one-hot encoding. We applied Scikit's OneHotEncoder to a normal NumPy array, which reflected a simple one-hot encoding scenario with the Healthy and Unhealthy feature values we used in one of the earlier sections. In the second example, we loaded the MNIST data from TensorFlow, and applied one-hot encoding to make our targets compatible with categorical crossentropy loss. We saw that the data is nicely converted, which is nice!
I hope that you have learned something from today's article. If you did, please feel free to leave a message in the comments section below 💬 Please feel free to do the same if you have questions or other remarks. I'd love to hear from you and will respond whenever possible. Thank you for reading MachineCurve today and happy engineering! 😎
References
Wikipedia. (2005, June 16). One-hot. Wikipedia, the free encyclopedia. Retrieved November 24, 2020, from https://en.wikipedia.org/wiki/One-hot
Wikipedia. (2012, March 30). Statistical data type. Wikipedia, the free encyclopedia. Retrieved November 24, 2020, from https://en.wikipedia.org/wiki/Statistical_data_type

Hi, I'm Chris!
I know a thing or two about AI and machine learning. Welcome to MachineCurve.com, where machine learning is explained in gentle terms.
Getting started
Foundation models
Learn how large language models and other foundation models are working and how you can train open source ones yourself.
Keras
Keras is a high-level API for TensorFlow. It is one of the most popular deep learning frameworks.
Machine learning theory
Read about the fundamentals of machine learning, deep learning and artificial intelligence.
Most recent articles
January 2, 2024
What is Retrieval-Augmented Generation?
December 27, 2023
In-Context Learning: what it is and how it works
December 22, 2023
CLIP: how it works, how it's trained and how to use it
Article tags
Most popular articles
February 18, 2020
How to use K-fold Cross Validation with TensorFlow 2 and Keras?
December 28, 2020
Introduction to Transformers in Machine Learning
December 27, 2021
StyleGAN, a step-by-step introduction
July 17, 2019
This Person Does Not Exist - how does it work?
October 26, 2020
Your First Machine Learning Project with TensorFlow 2.0 and Keras
Connect on social media
Connect with me on LinkedIn
To get in touch with me, please connect with me on LinkedIn. Make sure to write me a message saying hi!
Side info
The content on this website is written for educational purposes. In writing the articles, I have attempted to be as correct and precise as possible. Should you find any errors, please let me know by creating an issue or pull request in this GitHub repository.
All text on this website written by me is copyrighted and may not be used without prior permission. Creating citations using content from this website is allowed if a reference is added, including an URL reference to the referenced article.
If you have any questions or remarks, feel free to get in touch.
TensorFlow, the TensorFlow logo and any related marks are trademarks of Google Inc.
PyTorch, the PyTorch logo and any related marks are trademarks of The Linux Foundation.
Montserrat and Source Sans are fonts licensed under the SIL Open Font License version 1.1.
Mathjax is licensed under the Apache License, Version 2.0.