When you are training a Supervised Machine Learning model, scaling your data before you start fitting the model can be a crucial step for training success. In fact, without doing so, there are cases when the model's loss function will behave very strangely. However, not every dataset is made equal. There are cases when standard approaches to scaling don't work so well. Having a sparse dataset is one such scenario. In this article, we'll find out why and what we can do about it.
The article is structured as follows. Firstly, we will look at Feature Scaling itself. What is it? Why is it necessary? And what are those standard approaches that we have just talked about? Then, we move on to the sparsity characteristic of a dataset. What makes it sparse? Those questions will be answered first before we move to the core of our article.
This core combines the two topics: why we can't apply default Feature Scaling techniques when our dataset is sparse. We will show you what happens and why this is a bad thing. We do however also show you an example of how to handle this, involving Python and the Scikit-learn MaxAbsScaler. This way, you can still perform scaling, even when your dataset is sparse.
Let's take a look! 😎
Update 25/Nov/2020: fixed issue where wrong MaxAbsScaler output was displayed.
What is Feature Scaling?
Suppose that we have the following dataset:
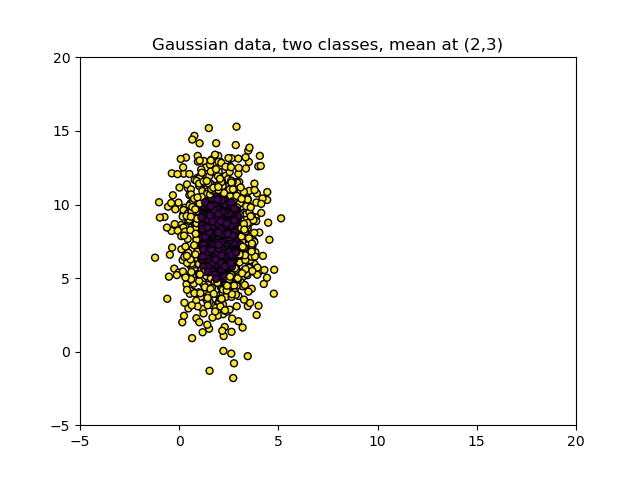
It visualizes two variables and two classes of variables.
We can use both variables to tell us something about the class: the variables closest to \((X, Y) = (2, 8)\) likely belong to the purple-black class, while variables towards the edge belong to the yellow class.
In other words, we can create a classifier that helps us determine what class a new sample belongs to. When we train a classifier, it will attempt to learn from the variables. Depending on the algorithm, there are various issues that can possibly occur when doing that:
- When our classifier involves a distance computation for class computation, e.g. when we use Radial Basis Function networks, our classifier will possibly be distorted by large distances, especially if the distances for one variable are large (e.g. it ranges from \([0, 1000000]\)) and low for another one (e.g. \([0, 1]\). If not made comparable, it thinks that the distances from the first variable are way more important, because the deltas are larger.
- When our classifier utilizes regularization for reducing model complexity, we can get ourselves into trouble as well, because the most common regularizers are based on distance metrics. Here, the same thing goes wrong.
- Sometimes, especially when we are using traditional Machine Learning algorithms, we don't want too many variables in our feature space - because of the curse of dimensionality. In those cases, we want to select the variables that contribute most first. Algorithms we can use for this purpose, such as Principal Component Analysis, rely on the variance of the variables for picking the most important ones.
Variance is the expectation of the squared deviation of a random variable from its mean. Informally, it measures how far a set of numbers is spread out from their average value.
Wikipedia (2001)
Given the three points mentioned above and the dataset displayed above, we can intuitively say the following:
Variance of the vertical variable is larger than the one of the horizontal one.
Or is it?
Can we actually compare those variables? What if we can't?
Let's check with standardization. Using this technique, with which we can express our variables in terms of their differences in standard deviation from the variable's mean value, we get the following picture:
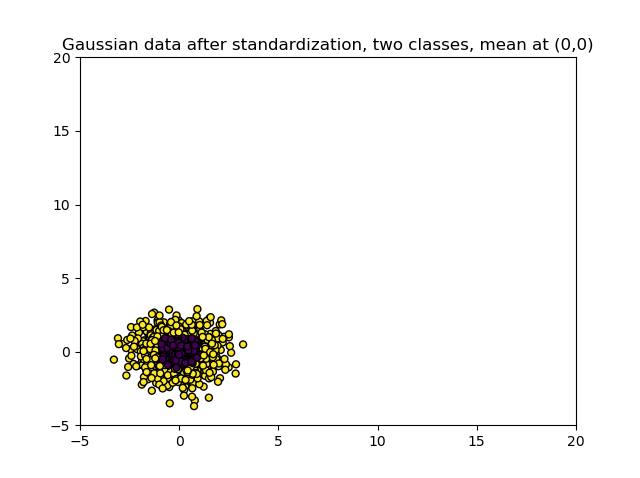
So it seems to be the case that the first variable was not more important than the second one after all!
The process of standardization is part of a class of techniques called Feature Scaling techniques. They involve methods to make variable scales comparable, and involve two mainly used techniques:
- Normalization, or min-max normalization, uses the minimum and maximum values from the dataset to normalize the variables into the \([0, 1]\) or \([a, b]\) ranges depending on your choice.
- Standardization, or Z-score normalization, converts the scale into the deviation in standard intervals from the mean for each variable. We already saw what could happen when applying standardization before.
If you want to understand Feature Scaling techniques in more detail, it would be good to read this article first before moving on.
What is Sparse Data?
Suppose that this is a sample from the dataset that you are training a Machine Learning model with. You can see that it is five-dimensional; there are five features that can - when desired - jointly be used to generate predictions.
For example, they can be measurements of e.g. particles, or electrical current, or anything like that. If it's zero, it means that there is no measurement.
This is what such a table can look like:
| Feature 1 | Feature 2 | Feature 3 | Feature 4 | Feature 5 |
| 0 | 0 | 0 | 0 | 0 |
| 0 | 0 | 0 | 7,7 | 0 |
| 1,26 | 0 | 0 | 0 | 0 |
| 0 | 0 | 0 | 0 | 0 |
| 2,12 | 0 | 2,11 | 0 | 0 |
| 0 | 0 | 0 | 0 | 0 |
| 0 | 0 | 0 | 0 | 0 |
| 0 | 0 | 0 | 0 | 0 |
| 0 | 0 | 0 | 0 | 0 |
| 0 | 1,28 | 0 | 0 | 0 |
| 0 | 0 | 0 | 0 | 0 |
| 0 | 0 | 0 | 0 | 1,87 |
This is an example of sparse data:
A variable with sparse data is one in which a relatively high percentage of the variable's cells do not contain actual data. Such "empty," or NA, values take up storage space in the file.
Oracle (n.d.)
Having sparse data is common when you are creating Machine Learning models related to time series. As we shall see, Feature Scaling can be quite problematic in that case.
Feature Scaling with Sparse Data
Suppose that we take the first feature and use standardization to rescale it:
import numpy as np
from sklearn.preprocessing import StandardScaler
samples_feature = np.array([0, 0, 1.26, 0, 2.12, 0, 0, 0, 0, 0, 0, 0]).reshape(-1, 1)
scaler = StandardScaler()
scaler.fit(samples_feature)
standardized_dataset = scaler.transform(samples_feature)
print(standardized_dataset)
This would be the output:
[[-0.43079317]
[-0.43079317]
[ 1.49630526]
[-0.43079317]
[ 2.81162641]
[-0.43079317]
[-0.43079317]
[-0.43079317]
[-0.43079317]
[-0.43079317]
[-0.43079317]
[-0.43079317]]
Not good!
As you can see, all values formerly 0 have turned into \(\approx -0.431\). By consequence, the scalars from feature 1 are not sparse anymore - and the entire dataset has become dense!
If your Machine Learning setting depends on sparse data, e.g. when it needs to fit into memory, applying standardization entirely removes the benefits that would become present in another case (StackOverflow, n.d.).
Using the MaxAbsScaler to handle Sparse Data
Fortunately, there is a way in which Feature Scaling can be applied to Sparse Data. We can do so using Scikit-learn's MaxAbsScaler.
Scale each feature by its maximum absolute value. This estimator scales and translates each feature individually such that the maximal absolute value of each feature in the training set will be 1.0. It does not shift/center the data, and thus does not destroy any sparsity.
Scikit-learn (n.d.)
As we can see, it uses the maximum absolute value to perform the scaling - and it therefore works in a similar way compared to regular min-max normalization, except then that we use absolute values here. The MaxAbsScaler does not center the data, but rather scales the range. This is why it works perfectly with sparse data. In fact, it is the recommenmded
import numpy as np
from sklearn.preprocessing import MaxAbsScaler
samples_feature = np.array([0, 0, 1.26, 0, 2.12, 0, 0, 0, 0, 0, 0, 0]).reshape(-1, 1)
scaler = MaxAbsScaler()
scaler.fit(samples_feature)
standardized_dataset = scaler.transform(samples_feature)
print(standardized_dataset)
...indeed gives the sparsity and scaling that we were looking for:
[[0. ]
[0. ]
[0.59433962]
[0. ]
[1. ]
[0. ]
[0. ]
[0. ]
[0. ]
[0. ]
[0. ]
[0. ]]
Why MaxAbsScaler and not MinMaxScaler for sparse data?
Great, I thought, but why use the MaxAbsScaler - and why cannot we use simple min-max normalization when we have a sparse dataset?
Especially because the output would be the same if we applied the MinMaxScaler, which is Scikit-learn's implementation of min-max normalization, to the dataset we used above:
[[0. ]
[0. ]
[0.59433962]
[0. ]
[1. ]
[0. ]
[0. ]
[0. ]
[0. ]
[0. ]
[0. ]
[0. ]]
Now, here's the catch - all values in the original input array to the scaler were positive. This means that the minimum value is zero and that, because it scales by minimum and maximum value, all values will be in the range \([0, 1]\). Since the maximum absolute value here equals the overall maximum value.
What if we used a dataset where negative values are present?
samples_feature = np.array([-2.40, -6.13, 0.24, 0, 0, 0, 0, 0, 0, 2.13]).reshape(-1, 1)
Min-max normalization would produce this:
[[0.45157385]
[0. ]
[0.77118644]
[0.74213075]
[0.74213075]
[0.74213075]
[0.74213075]
[0.74213075]
[0.74213075]
[1. ]]
Bye bye sparsity!
The output of our MaxAbsScaler is good, as we would expect:
[[-0.39151713]
[-1. ]
[ 0.03915171]
[ 0. ]
[ 0. ]
[ 0. ]
[ 0. ]
[ 0. ]
[ 0. ]
[ 0.34747145]]
So that's why you should prefer absolute-maximum-scaling (using MaxAbsScaler) when you are working with a sparse dataset.
Summary
In this article, we looked at what to do when you have a sparse dataset and you want to apply Feature Scaling techniques. The reason why we did this is because applying the standard methods for Feature Scaling is problematic in this case, because it destroys the sparsity characteristic of the dataset, meaning that e.g. memory benefits are no longer applicable.
And with Machine Learning algorithms, which can use a lot of compute capacity from time to time, this can be really problematic.
Normalization and Standardization are therefore not applicable. However, fortunately, there is a technique that can be applied: scaling by means of the maximum absolute value from the dataset. In this case, we create a scaled dataset where sparsity is preserved. We saw that it works by means of a Python example using Scikit-learn's MaxAbsScaler. In the example, we also saw why regular max-min normalization doesn't work and why we really need the MaxAbsScaler.
I hope that you have learned something from today's article! If you did, please feel free to leave a message in the comments section below 💬 Please do the same if you have any questions or other remarks. Regardless, thank you for reading MachineCurve today and happy engineering! 😎
References
Wikipedia. (2001, June 30). Variance. Wikipedia, the free encyclopedia. Retrieved November 18, 2020, from https://en.wikipedia.org/wiki/Variance
Oracle. (n.d.). Defining data objects, 6 of 9. Moved. https://docs.oracle.com/cd/A91202_01/901_doc/olap.901/a86720/esdatao6.htm
StackOverflow. (n.d.). Features scaling and mean normalization in a sparse matrix. Stack Overflow. https://stackoverflow.com/questions/21875518/features-scaling-and-mean-normalization-in-a-sparse-matrix
Scikit-learn. (n.d.). Sklearn.preprocessing.MaxAbsScaler — scikit-learn 0.23.2 documentation. scikit-learn: machine learning in Python — scikit-learn 0.16.1 documentation. Retrieved November 23, 2020, from https://scikit-learn.org/stable/modules/generated/sklearn.preprocessing.MaxAbsScaler.html#sklearn.preprocessing.MaxAbsScaler

Hi, I'm Chris!
I know a thing or two about AI and machine learning. Welcome to MachineCurve.com, where machine learning is explained in gentle terms.
Getting started
Foundation models
Learn how large language models and other foundation models are working and how you can train open source ones yourself.
Keras
Keras is a high-level API for TensorFlow. It is one of the most popular deep learning frameworks.
Machine learning theory
Read about the fundamentals of machine learning, deep learning and artificial intelligence.
Most recent articles
January 2, 2024
What is Retrieval-Augmented Generation?
December 27, 2023
In-Context Learning: what it is and how it works
December 22, 2023
CLIP: how it works, how it's trained and how to use it
Article tags
Most popular articles
February 18, 2020
How to use K-fold Cross Validation with TensorFlow 2 and Keras?
December 28, 2020
Introduction to Transformers in Machine Learning
December 27, 2021
StyleGAN, a step-by-step introduction
July 17, 2019
This Person Does Not Exist - how does it work?
October 26, 2020
Your First Machine Learning Project with TensorFlow 2.0 and Keras
Connect on social media
Connect with me on LinkedIn
To get in touch with me, please connect with me on LinkedIn. Make sure to write me a message saying hi!
Side info
The content on this website is written for educational purposes. In writing the articles, I have attempted to be as correct and precise as possible. Should you find any errors, please let me know by creating an issue or pull request in this GitHub repository.
All text on this website written by me is copyrighted and may not be used without prior permission. Creating citations using content from this website is allowed if a reference is added, including an URL reference to the referenced article.
If you have any questions or remarks, feel free to get in touch.
TensorFlow, the TensorFlow logo and any related marks are trademarks of Google Inc.
PyTorch, the PyTorch logo and any related marks are trademarks of The Linux Foundation.
Montserrat and Source Sans are fonts licensed under the SIL Open Font License version 1.1.
Mathjax is licensed under the Apache License, Version 2.0.