Training a Supervised Machine Learning model involves feeding forward data from a training dataset, through the model, generating predictions. These predictions are then compared with what is known as the ground truth, or the corresponding targets for the training data. Subsequently, the model is improved, by minimizing a cost, error or loss function.
It is important to prepare your dataset before feeding it to your model. When you pass through data without doing so, the model may show some very interesting behavior - and training can become really difficult, if not impossible. In those cases, when inspecting your model code, it could very well be the case that you forgot to apply normalization or standardization. What are they? Why are they necessary? And how do they work? Precisely that is what we will look at in this article.
Firstly, we will take a look at why you need a normalized or standardized dataset. Subsequently, we'll move forward and see how those techniques actually work. Finally, we give a lot of step-by-step examples by using Scikit-learn and Python for making your dataset ready for Machine Learning models.
Let's take a look! :)
Update 08/Dec/2020: added references to PCA article.
Normalization and Standardization for Feature Scaling
Before studying the what of something, I always think that it helps studying the why first. At least, it makes you understand why you have to apply certain techniques or methods. The same is true for Normalization and Standardization. Why are they necessary? Let's take a look at this in more detail.
They are required by Machine Learning algorithms
When you are training a Supervised Machine Learning model, you are feeding forward data through the model, generating predictions, and subsequently improving the model. As you read in the introduction, this is achieved by minimizing a cost/error/loss function, and it allows us to optimize models in their unique ways.
For example, a Support Vector Machine is optimized by finding support vectors that support the decision boundary with the greatest margin between two classes, effectively computing a distance metric. Neural networks use gradient descent for optimization, which involves walking down the loss landscape into the direction where loss improves most. And there are many other ways. Now, here are some insights about why datasets must be scaled for Machine Learning algorithms (Wikipedia, 2011):
- Gradient descent converges much faster when the dataset is scaled.
- If the model depends on measuring distance (think SVM), the distances are comparable after the dataset was scaled. In fact, if it is not scaled, computation of the loss can be "governed by this particular feature" if the feature has a really big scale compared to other features (Wikipedia, 2011).
- If you apply regularization, you must also apply scaling, because otherwise some features may be penalized more than strictly necessary.
They help Feature Selection too
Suppose that we given a dataset of a runner's diary and that our goal is to learn a predictive model between some of the variables and runner performance. What we would normally do in those cases is perform a feature selection procedure, because we cannot simply feed all samples due to two reasons:
- The curse of dimensionality: if we look at our dataset as a feature space with each feature (i.e., column) representing one dimension, our space would be multidimensional if we use many features. The more dimensions we add, the more training data we need; this need increases exponentially. By consequence, although we should use sufficient features, we don't want to use every one of them.
- We don't want to use features that contribute insignificantly. Some features (columns) contribute to the output less significantly than others. It could be that when removed, the model will still be able to perform, but at a significantly lower computational cost. We therefore want to be able to select the features that contribute most significantly.
In machine learning problems that involve learning a "state-of-nature" from a finite number of data samples in a high-dimensional feature space with each feature having a range of possible values, typically an enormous amount of training data is required to ensure that there are several samples with each combination of values.
Wikipedia (n.d.) about the curse of dimensionality
We would e.g. apply algorithms such as Principal Component Analysis (PCA) to help us determine which features are most important. If we look at how these algorithms work, we see that e.g. PCA extracts new features based on the principal directions in the dataset, i.e. the directions in your data where variance is largest (Scikit-learn, n.d.).
Variance is the expectation of the squared deviation of a random variable from its mean. Informally, it measures how far a set of numbers is spread out from their average value.
Wikipedia (2001)
Let's keep this in mind when looking at the following dataset:
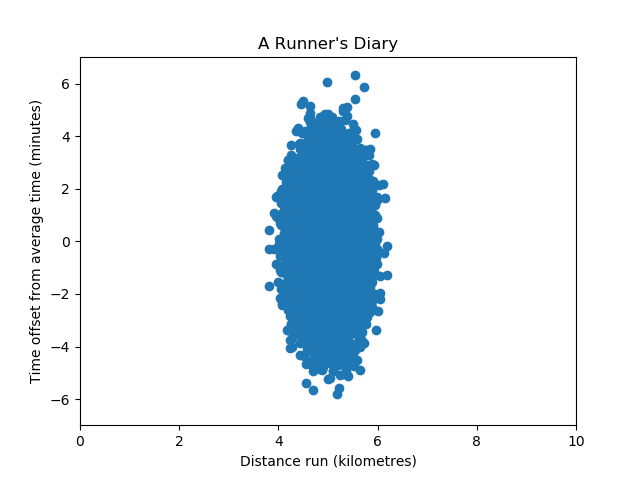
Here, the variance of the variable Time offset is larger than that of the variable Distance run.
PCA will therefore naturally select the Time offset variable over the Distance run variable, because the eigenpairs are more significant there.
However, this does not necessarily mean that it is in fact more important - because we cannot compare variance. Only if variance is comparable, and hence the scales are equal in the unit they represent, we can confidently use algorithms like PCA for feature selection. That's why we must find a way to make our variables comparable.
Introducing Feature Scaling
And, to be speaking most generally, that method is called feature scaling - and it is applied during the data preprocessing step.
Feature scaling is a method used to normalize the range of independent variables or features of data. In data processing, it is also known as data normalization and is generally performed during the data preprocessing step.
Wikipedia (2011)
There are two primary ways for feature scaling which we will cover in the remainder of this article:
- Rescaling, or min-max normalization: we scale the data into one of two ranges: \([0, 1]\) or \([a, b]\), often \([-1, 1]\).
- Standardization, or Z-score normalization: we scale the data so that the mean is zero and variance is 1.
Let's now cover each of the three methods in more detail, find out how they work, and identify when they are used best.
Rescaling (min-max normalization)
Rescaling, or min-max normalization, is a simple method for bringing your data into one out of two ranges: \([0, 1]\) or \([a, b]\). It highly involves the minimum and maximum values from the dataset in normalizing the data.
How it works - the [0, 1] way
Suppose that we have the following array:
dataset = np.array([1.0, 12.4, 3.9, 10.4])
Min-max normalization for the range \([0, 1]\) can be defined as follows:
normalized_dataset = (dataset - min(dataset)) / (max(dataset) - min(dataset))
In a naïve way, using Numpy, we can therefore normalize our data into the \([0, 1]\) range in the following way:
import numpy as np
dataset = np.array([1.0, 12.4, 3.9, 10.4])
normalized_dataset = (dataset - np.min(dataset)) / (np.max(dataset) - np.min(dataset))
print(normalized_dataset)
This indeed yields an array where the lowest value is now 0.0 and the biggest is 1.0:
[0. 1. 0.25438596 0.8245614 ]
How it works - the [a, b] way
If instead we wanted to scale it to some other arbitrary range - say \([0, 1.5]\), we can apply min-max normalization but then for the \([a, b]\) range, where \(a\) and \(b\) can be chosen yourself.
We can use the following formula for normalization:
normalized_dataset = a + ((dataset - min(dataset)) * (b - a) / (max(dataset) - min(dataset)))
Or, for the dataset from the previous section, using a naïve Python implementation:
import numpy as np
a = 0
b = 1.5
dataset = np.array([1.0, 12.4, 3.9, 10.4])
normalized_dataset = a + ((dataset - np.min(dataset)) * (b - a) / (np.max(dataset) - np.min(dataset)))
print(normalized_dataset)
Which yields:
[0. 1.5 0.38157895 1.23684211]
Applying the MinMaxScaler from Scikit-learn
Scikit-learn, the popular machine learning library used frequently for training many traditional Machine Learning algorithms provides a module called MinMaxScaler, and it is part of the sklearn.preprocessing API.
It allows us to fit a scaler with a predefined range to our dataset, and subsequently perform a transformation for the data. The code below gives an example of how to use it.
- We import
numpyas a whole and theMinMaxScalerfromsklearn.preprocessing. - We define the NumPy array that we just defined before, but now, we have to reshape it:
.reshape(-1, 1). This is a Scikit-learn requirement for arrays with just one feature per array item (which in our case is true, because we are using scalar values). - We then initialize the
MinMaxScalerand here we also specify our \([a, b]\) range:feature_range=(0, 1.5). Of course, as \([0, 1]\) is also an \([a, b]\) range, we can implement that one as well usingMinMaxScaler. - We then fit the data to our scaler, using
scaler.fit(dataset). This way, it becomes capable of transforming datasets. - We finally transform the
datasetusingscaler.transform(dataset)and print the result.
import numpy as np
from sklearn.preprocessing import MinMaxScaler
dataset = np.array([1.0, 12.4, 3.9, 10.4]).reshape(-1, 1)
scaler = MinMaxScaler(feature_range=(0, 1.5))
scaler.fit(dataset)
normalized_dataset = scaler.transform(dataset)
print(normalized_dataset)
And indeed, after printing, we can see that the outcome is the same as obtained with our naïve approach:
[[0. ]
[1.5 ]
[0.38157895]
[1.23684211]]
Standardization (Z-scale normalization)
In the previous example, we normalized our dataset based on the minimum and maximum values. Mean and standard deviation are however not standard, meaning that the mean is zero and that the standard deviation is one.
print(normalized_dataset)
print(np.mean(normalized_dataset))
print(np.std(normalized_dataset))
[[0. ]
[1.5 ]
[0.38157895]
[1.23684211]]
0.7796052631578947
0.611196249385709
Because the bounds of our normalizations would not be equal, it would still be (slightly) unfair to compare the outcomes e.g. with PCA.
For example, if we used a different dataset, our results would be different:
import numpy as np
from sklearn.preprocessing import MinMaxScaler
dataset = np.array([2.4, 6.2, 1.8, 9.0]).reshape(-1, 1)
scaler = MinMaxScaler(feature_range=(0, 1.5))
scaler.fit(dataset)
normalized_dataset = scaler.transform(dataset)
print(normalized_dataset)
print(np.mean(normalized_dataset))
print(np.std(normalized_dataset))
[[0.125 ]
[0.91666667]
[0. ]
[1.5 ]]
0.6354166666666665
0.6105090942538584
This is where standardization or Z-score normalization comes into the picture. Rather than using the minimum and maximum values, we use the mean and standard deviation from the data. By consequence, all our features will now have zero mean and unit variance, meaning that we can now compare the variances between the features.
How it works
The formula for standardization is as follows:
standardized_dataset = (dataset - mean(dataset)) / standard_deviation(dataset))
In other words, for each sample from the dataset, we subtract the mean and divide by the standard deviation. By removing the mean from each sample, we effectively move the samples towards a mean of 0 (after all, we removed it from all samples). In addition, by dividing by the standard deviation, we yield a dataset where the values describe by how much of the standard deviation they are offset from the mean.
Python example
This can also be implemented with Python:
import numpy as np
dataset = np.array([1.0, 2.0, 3.0, 3.0, 3.0, 2.0, 1.0])
standardized_dataset = (dataset - np.average(dataset)) / (np.std(dataset))
print(standardized_dataset)
Which yields:
[-1.37198868 -0.17149859 1.02899151 1.02899151 1.02899151 -0.17149859
-1.37198868]
In Scikit-learn, the sklearn.preprocessing module provides the StandardScaler which helps us perform the same action in an efficient way.
import numpy as np
from sklearn.preprocessing import StandardScaler
dataset = np.array([1.0, 2.0, 3.0, 3.0, 3.0, 2.0, 1.0]).reshape(-1, 1)
scaler = StandardScaler()
scaler.fit(dataset)
standardized_dataset = scaler.transform(dataset)
print(standardized_dataset)
print(np.mean(standardized_dataset))
print(np.std(standardized_dataset))
With as outcome:
[[-1.37198868]
[-0.17149859]
[ 1.02899151]
[ 1.02899151]
[ 1.02899151]
[-0.17149859]
[-1.37198868]]
3.172065784643304e-17
1.0
We see that the mean is really close to 0 (\(3.17 \times 10^{-17}\)) and that standard deviation is one.
Normalization vs Standardization: when to use which one?
Many people have the question when to use normalization, and when to use standardization? This is a valid question - and I had it as well.
Most generally, the rule of thumb would be to use min-max normalization if you want to normalize the data while keeping some differences in scales (because units remain different), and use standardization if you want to make scales comparable (through standard deviations).
The example below illustrates the effects of standardization. In it, we create Gaussian data, stretch one of the axes with some value to make them relatively incomparable, and plot the data. This clearly indicates the stretched blobs in an absolute sense. Then, we use standardization and plot the data again. We now see that both the mean has moved to \((0, 0)\) and that when the data is standardized, the variance of the axes is pretty similar!
If we hadn't applied feature scaling here, algorithms like PCA would have pretty much fooled us. ;-)
# Imports
import matplotlib.pyplot as plt
from sklearn.datasets import make_gaussian_quantiles
from sklearn.preprocessing import StandardScaler
# Make Gaussian data
plt.title("Gaussian data, two classes, mean at (2,3)")
X1, Y1 = make_gaussian_quantiles(n_features=2, n_classes=2, n_samples=1000, mean=(2,3))
# Stretch one of the axes
X1[:, 1] = 2.63 * X1[:, 1]
# Plot data
plt.scatter(X1[:, 0], X1[:, 1], marker='o', c=Y1,
s=25, edgecolor='k')
axes = plt.gca()
axes.set_xlim([-5, 20])
axes.set_ylim([-5, 20])
plt.show()
# Standardize Gaussian data
scaler = StandardScaler()
scaler.fit(X1)
X1 = scaler.transform(X1)
# Plot standardized data
plt.title("Gaussian data after standardization, two classes, mean at (0,0)")
plt.scatter(X1[:, 0], X1[:, 1], marker='o', c=Y1,
s=25, edgecolor='k')
axes = plt.gca()
axes.set_xlim([-5, 20])
axes.set_ylim([-5, 20])
plt.show()


Summary
In this article, we looked at Feature Scaling for Machine Learning. More specifically, we looked at Normalization (min-max normalization) which brings the dataset into the \([a, b]\) range. In addition to Normalization, we also looked at Standardization, which allows us to convert the scales into amounts of standard deviation, making the axes comparable for e.g. algorithms like PCA.
We illustrated our reasoning with step-by-step Python examples, including some with standard Scikit-learn functionality.
I hope that you have learned something from this article! If you did, feel free to leave a message in the comments section 💬 Please do the same if you have questions or other comments. I'd love to hear from you! Thank you for reading MachineCurve today and happy engineering 😎
References
Wikipedia. (2011, December 15). Feature scaling. Wikipedia, the free encyclopedia. Retrieved November 18, 2020, from https://en.wikipedia.org/wiki/Feature_scaling
Scikit-learn. (n.d.). Importance of feature scaling — scikit-learn 0.23.2 documentation. scikit-learn: machine learning in Python — scikit-learn 0.16.1 documentation. Retrieved November 18, 2020, from https://scikit-learn.org/stable/auto_examples/preprocessing/plot_scaling_importance.html
Wikipedia. (n.d.). Curse of dimensionality. Wikipedia, the free encyclopedia. Retrieved November 18, 2020, from https://en.wikipedia.org/wiki/Curse_of_dimensionality
Wikipedia. (2001, June 30). Variance. Wikipedia, the free encyclopedia. Retrieved November 18, 2020, from https://en.wikipedia.org/wiki/Variance

Hi, I'm Chris!
I know a thing or two about AI and machine learning. Welcome to MachineCurve.com, where machine learning is explained in gentle terms.
Getting started
Foundation models
Learn how large language models and other foundation models are working and how you can train open source ones yourself.
Keras
Keras is a high-level API for TensorFlow. It is one of the most popular deep learning frameworks.
Machine learning theory
Read about the fundamentals of machine learning, deep learning and artificial intelligence.
Most recent articles
January 2, 2024
What is Retrieval-Augmented Generation?
December 27, 2023
In-Context Learning: what it is and how it works
December 22, 2023
CLIP: how it works, how it's trained and how to use it
Article tags
Most popular articles
February 18, 2020
How to use K-fold Cross Validation with TensorFlow 2 and Keras?
December 28, 2020
Introduction to Transformers in Machine Learning
December 27, 2021
StyleGAN, a step-by-step introduction
July 17, 2019
This Person Does Not Exist - how does it work?
October 26, 2020
Your First Machine Learning Project with TensorFlow 2.0 and Keras
Connect on social media
Connect with me on LinkedIn
To get in touch with me, please connect with me on LinkedIn. Make sure to write me a message saying hi!
Side info
The content on this website is written for educational purposes. In writing the articles, I have attempted to be as correct and precise as possible. Should you find any errors, please let me know by creating an issue or pull request in this GitHub repository.
All text on this website written by me is copyrighted and may not be used without prior permission. Creating citations using content from this website is allowed if a reference is added, including an URL reference to the referenced article.
If you have any questions or remarks, feel free to get in touch.
TensorFlow, the TensorFlow logo and any related marks are trademarks of Google Inc.
PyTorch, the PyTorch logo and any related marks are trademarks of The Linux Foundation.
Montserrat and Source Sans are fonts licensed under the SIL Open Font License version 1.1.
Mathjax is licensed under the Apache License, Version 2.0.