Training a deep learning model is both simple and complex at the same time. It's simple because with libraries like TensorFlow 2.0 (tensorflow.keras, specifically) it's very easy to get started. But while creating a first model is easy, fine-tuning it while knowing what you are doing is a bit more complex.
For example, you will need some knowledge on the supervised learning process, gradient descent or other optimization, regularization, and a lot of other contributing factors.
Tweaking and tuning a deep learning models therefore benefits from two things: insight into what is happening and automated control to avoid the need for human intervention where possible. In Keras, this can be achieved with the tensorflow.keras.callbacks API. In this article, we will look into Callbacks in more detail. We will first illustrate what they are by displaying where they play a role in the supervised machine learning process. Then, we cover the Callbacks API - and for each callback, illustrate what it can be used for together with a small example. Finally, we will show how you can create your own Callback with the tensorflow.keras.callbacks.Base class.
Let's take a look :)
Update 11/Jan/2021: changed header image.
Callbacks and their role in the training process
In our article about the supervised machine learning process, we saw how a supervised machine learning model is trained:
- A machine learning model (today, often a neural network) is initialized.
- Samples from the training set are fed forward, through the model, resulting in a set of predictions.
- The predictions are compared with what is known as the ground truth (i.e. the labels corresponding to the training samples), resulting in one value - a loss value - telling us how bad the model performs.
- Based on the loss value and the subsequent backwards computation of the error, the weights are changed a little bit, to make the model a bit better. Then, we're either moving back to step 2, or we stop the training process.
As we can see, steps 2-4 are iterative, meaning that the model improves in a cyclical fashion. This is reflected in the figure below.
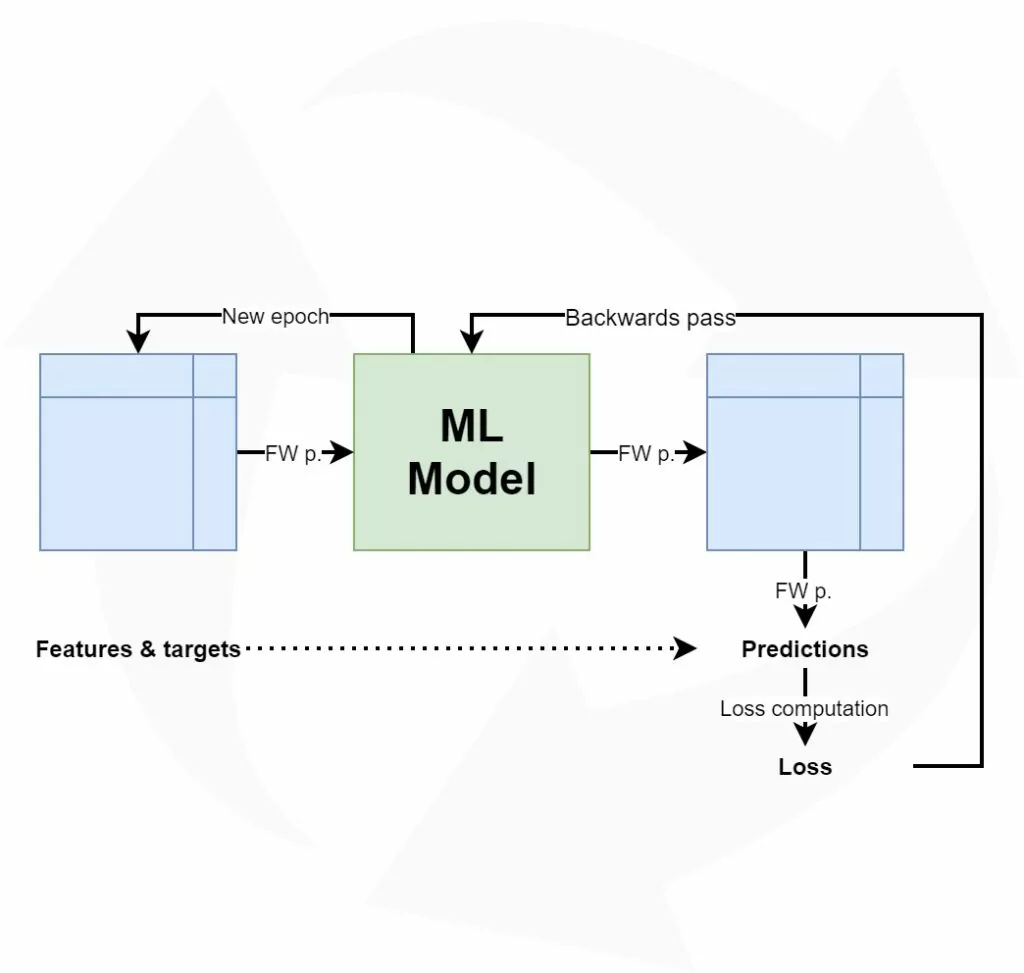
In Machine Learning terms, each iteration is also called an epoch. Hence, training a machine learning model involves the completion of at least one, but often multiple epochs. Note from the article about gradient descent based optimization that we often don't feed forward all data at once. Instead, we use what is called a minibatch approach - the entire batch of data is fed forward in smaller batches called minibatches. By consequence, each epoch consists of at least one but often multiple batches of data.
Now, it can be the case that you want to get insights from the training process while it is running. Or you want to provide automated steering in order to avoid wasting resources. In those cases, you might want to add a callback to your Keras model.
A callback is an object that can perform actions at various stages of training (e.g. at the start or end of an epoch, before or after a single batch, etc).
Keras Team (n.d.)
As we shall see later in this article, among others, there are callbacks for monitoring and for stopping the training process when it no longer makes the model better. This is possible because with callbacks, we can 'capture' the training process while it is happening. They essentially 'hook' into the training process by allowing the training process to invoke certain callback definitions. In Keras, each callback implements at least one, but possibly multiple of the following definitions (Keras Team, n.d.).
- With the
on_train_beginandon_train_enddefinitions, we can perform a certain action either whenmodel.fitstarts executing or when the training process has just ended. - With the
on_epoch_beginandon_epoch_enddefinitions, we can perform a certain action just before the start of an epoch, or directly after it has ended. - With the
on_test_beginandon_test_enddefinitions, we can perform a certain action just before or after the model is evaluated. - With the
on_predict_beginandon_predict_enddefinitions, we can do the same, but then when we generate new predictions. If we predict for a batch rather than a single sample, we can use theon_predict_batch_beginandon_predict_batch_enddefinitions. - With the
on_train_batch_begin,on_train_batch_end,on_test_batch_beginandon_test_batch_enddefinitions, we can perform a certain action directly before or after we feed a batch to either the training or testing process.
As we can see, by using a callback, through the definitions outlined above, we can control the training process at a variety of levels.
The Keras Callbacks API
Now that we understand what callbacks are, how they can help us, and what definitions - and hence hooks - are available for 'breaking into' your training process in TensorFlow 2.x based Keras. Now, it's time to take a look at the Keras Callbacks API. Available as tensorflow.keras.callbacks, it's a set of generally valuable Callbacks that can be used in a variety of cases.
Most specifically, it contains the following callbacks, and we will cover each of them next:
- ModelCheckpoint callback: can be used to automatically save a model after each epoch, or just the best one.
- TensorBoard callback: allows us to monitor the training process in realtime with TensorBoard.
- EarlyStopping callback: ensures that the training process stops if the loss value does no longer improve.
- LearningRateScheduler callback: updates the learning rate before the start of an epoch, based on a
schedulerfunction. - ReduceLROnPlateau callback: reduces learning rate if the loss value does no longer improve.
- RemoteMonitor callback: sends TensorFlow training events to a remote monitor, such as a logging system.
- LambdaCallback: allows us to define simple functions that can be executed as a callback.
- TerminateOnNaN callback: if the loss value is Not a Number (NaN), the training process stops.
- CSVLogger callback: streams the outcome of an epoch to a CSV file.
- ProgbarLogger callback: used to determine what is printed to standard output in the Keras progress bar.
How do we add a callback to a Keras model?
Before we take a look at all the individual callbacks, we must take a look at how we can use the tensorflow.keras.callbacks API in the first place. Doing so is really simple and only changes your code in a minor way:
- You must add the specific callbacks to the model imports.
- You must initialize the callbacks you want to use, including their configuration; preferably do so in a list.
- You must add the callbacks to the
model.fitcall.
With those three simple steps, you ensure that the callbacks are hooked into the training process!
For example, if we want to use both ModelCheckpoint and EarlyStopping - as we do here - for step (1), we first add the imports:
from tensorflow.keras.callbacks import EarlyStopping, ModelCheckpoint
Then, for step (2), we initialize the callbacks in a list:
keras_callbacks = [
EarlyStopping(monitor='val_loss', patience=5, mode='min', min_delta=0.01),
ModelCheckpoint(checkpoint_path, monitor='val_loss', save_best_only=True, mode='min')
]
And then, for step (3), we simply add the callbacks to model.fit:
model.fit(train_generator,
epochs=50,
verbose=1,
callbacks=keras_callbacks,
validation_data=val_generator)
ModelCheckpoint callback
If you want to periodically save your Keras model - or the model weights - to some file, the ModelCheckpoint callback is what you need.
Callback to save the Keras model or model weights at some frequency.
TensorFlow (n.d.)
It is available as follows:
tf.keras.callbacks.ModelCheckpoint(
filepath, monitor='val_loss', verbose=0, save_best_only=False,
save_weights_only=False, mode='auto', save_freq='epoch', options=None, **kwargs
)
With the following arguments:
- With
filepath, you can specify where the model must be saved. - If you want to save only if some quantity has changed, you can set this quantity by means of
monitor. It is set to validation loss by default. - With
verbose, you can specify if the callback output should be output in your standard output (often, your terminal). - If you only want to save the model when the monitored quantity improves, you can set
save_best_onlytoTrue. - Normally, the entire model is saved - that is, the stack of layers as well as the model weights. If you want to save the weights only (e.g. because you can initialize the model yourself), you can set
save_weights_onlytoTrue. - With
mode, you can determine in what direction themonitorquantity must move to consider it to be an improvement. You can choose any from{auto, min, max}. When it is set toauto, it determines themodebased on themonitor- with loss, for example, it will bemin; with accuracy, it will bemax. - The
save_freqallows you to determine when to save the model. By default, it is saved after every epoch (or checks whether it has improved after every epoch). By changing the'epoch'string into an integer, you can also instruct Keras to save after everynminibatches. - If you want, you can specify other compatible
optionsas well. Check theModelCheckpointdocs (see link in references) for more information about theseoptions.
Using ModelCheckpoint is easy - and here is an example based on a generator:
checkpoint_path=f'{os.path.dirname(os.path.realpath(__file__))}/covid-convnet.h5'
keras_callbacks = [
ModelCheckpoint(checkpoint_path, monitor='val_loss', save_best_only=True, mode='min')
]
model.fit(train_generator,
epochs=50,
verbose=1,
callbacks=keras_callbacks,
validation_data=val_generator)
TensorBoard callback
Did you know that you can visualize the training process realtime with TensorBoard?
With the TensorBoard callback, you can link TensorBoard with your Keras model.
Enable visualizations for TensorBoard.
TensorFlow (n.d.)
The callback logs a range of items from the training process into your TensorBoard log location:
- Metrics summary plots
- Training graph visualization
- Activation histograms
- Sampled profiling
It is implemented as follows:
tf.keras.callbacks.TensorBoard(
log_dir='logs', histogram_freq=0, write_graph=True, write_images=False,
update_freq='epoch', profile_batch=2, embeddings_freq=0,
embeddings_metadata=None, **kwargs
)
- With
log_dir, you can specify the file path to your TensorBoard log folder. - The
TensorBoardcallback computes activation and weight histograms. Withhistogram_freq, you can specify the frequency (in epochs) when this should happen. Histograms will not be computed whenhistogram_freqis set to 0. - Whether to write the TensorFlow graph to the logs can be configured with
write_graph. - If you want to visualize your model weights as images in TensorBoard, you can set
write_imagestoTrue. - With
update_freq, you can specify when this callback sends data to TensorBoard. If it's set toepoch, it will send data every epoch. If set tobatch, data will be sent on every batch. If set to an integerninstead, data will be sent everynbatches. - With the TensorFlow Profiler, we can calculate the compute performance of TensorFlow - that is, the resources it needs at a point in time. With
profile_batch, you can specify a batch to profile, meaning that Profiling information will be sent to TensorBoard as well. - If you are using Embeddings, it is possible to let TensorFlow visualize them. Specifying the
embeddings_freqallows you to configure when Embeddings need to be visualized; it represents the frequency in epochs. Embeddings will not be visualized when the frequency is set to 0. - A dictionary with Embeddings metadata can be passed along with
embeddings_metadata.
Here is an example of using the TensorBoard callback within your Keras model:
keras_callbacks = [
TensorBoard(log_dir="./logs")
]
model.fit(train_generator,
epochs=50,
verbose=1,
callbacks=keras_callbacks,
validation_data=val_generator)
EarlyStopping callback
Optimizing your neural network involves applying gradient descent or another optimizer to a loss value generated by feeding forward batches of training samples, generating predictions that are compared with the corresponding training labels.
During this process, you want to find a model that performs well in terms of predictions (i.e., it is not underfit) but that is not too rigid with respect to the dataset it is trained on (i.e., it is neither overfit). That's why the EarlyStopping callback can be useful if you are dealing with a situation like this.
Stop training when a monitored metric has stopped improving.
TensorBoard (n.d.)
It is implemented as follows:
tf.keras.callbacks.EarlyStopping(
monitor='val_loss', min_delta=0, patience=0, verbose=0, mode='auto',
baseline=None, restore_best_weights=False
)
- The
monitoris the quantity to monitor for improvement; it is similar to the quantity monitored forModelCheckpointing. - The same goes for the
mode. - With
min_delta, you can configure the minimum change that must happen from the currentmonitorin order to consider the change an improvement. - With
patience, you can indicate how long in epochs to wait for additional improvements before stopping the training process. - With
verbose, you can specify the verbosity of the callback, i.e. whether the output is written to standard output. - The
baselinevalue can be configured to specify a minimummonitorthat must be achieved at all before any change can be considered an improvement. - As you would expect, having a
patience> 0 will ensure that the model is trained forpatiencemore epochs, possibly making it worse. Withrestore_best_weights, we can restore the weights of the best-performing model instance when the training process stops. This can be useful if you directly perform model evaluation after stopping the training process.
Here is an example of using EarlyStopping with Keras:
keras_callbacks = [
EarlyStopping(monitor='val_loss', min_delta=0.001, restore_best_weights=True)
]
model.fit(train_generator,
epochs=50,
verbose=1,
callbacks=keras_callbacks,
validation_data=val_generator)
LearningRateScheduler callback
During the optimization process, a so called weight update is computed. However, if we compare the optimization process with rolling a ball down a mountain (reflecting the loss landscape), we want to smooth the ride, ensuring that our ball does not bounce out of control. That is why a learning rate is applied: it specifies a fraction of the weight update to be used by the optimizer.
Preferably being relatively large during the early iterations and lower in the later stages, we must adapt the learning rate during the training process. This is called learning rate decay and shows what a learning rate scheduler can be useful for. The LearningRateScheduler callback implements this functionality.
At the beginning of every epoch, this callback gets the updated learning rate value from
schedulefunction provided at__init__, with the current epoch and current learning rate, and applies the updated learning rate on the optimizer.TensorFlow (n.d.)
Its implementation is really simple:
tf.keras.callbacks.LearningRateScheduler(
schedule, verbose=0
)
- It accepts a
schedulefunction which you can use to decide yourself how the learning rate must be scheduled during every epoch. - With
verbose, you can decide to illustrate the callback output in your standard output.
Here is an example of using the LearningRateScheduler with Keras:
def scheduler(epoch, learning_rate):
if epoch < 15:
return learning_rate
else:
return learning_rate * 0.99
keras_callbacks = [
LearningRateScheduler(scheduler)
]
model.fit(train_generator,
epochs=50,
verbose=1,
callbacks=keras_callbacks,
validation_data=val_generator)
ReduceLROnPlateau callback
During the optimization process - i.e., rolling the ball downhill - it can be the case that you encounter so-called loss plateaus. In those areas, the gradient of the loss function is close to zero, but not entirely - indicating that you are in the vicinity of a loss minimum. That is, close to where you want to be (unless you are dealing with a local minimum, of course).
Keeping your learning rate equal when close to a plateau means that your model will likely not improve any further. This happens because your model will optimize, oscillating around the loss minimum, simply because the steps the current learning rate it instructs to set are too big.
With the ReduceLROnPlateau callback, the optimization process can be instructed to reduce the learning rate (and hence the step) when a plateau is encountered.
Models often benefit from reducing the learning rate by a factor of 2-10 once learning stagnates. This callback monitors a quantity and if no improvement is seen for a 'patience' number of epochs, the learning rate is reduced.
TensorFlow (n.d.)
The callback is implemented as follows:
tf.keras.callbacks.ReduceLROnPlateau(
monitor='val_loss', factor=0.1, patience=10, verbose=0, mode='auto',
min_delta=0.0001, cooldown=0, min_lr=0, **kwargs
)
- The
monitorandpatienceresemble the monitors and patience values that we have already encountered. In other words, it is the quantity to observe that helps us judge whether improvement has happened. Patience tells us how long to wait before we consider improvement impossible. Themodeis related to themonitorand instructs what kind of operation to perform while monitoring:minormax(orautomatically determined). - The
min_deltatells us how much the model should improve at minimum before we consider the change an improvement. - The
factordetermines how much to decrease the learning rate upon encountering a plateau:new_lr = lr * factor. - The
verboseattribute can be configured to display the callback output in your standard output. - The
min_lrgives us a lower bound on the learning rate. - The
cooldownattribute instructs the model to wait with invoking this specific callback for a number of epochs, allowing us to find some improvement with the reduced learning rate (this could take a few epochs).
An example of using the ReduceLROnPlateau callback with Keras:
keras_callbacks = [
ReduceLROnPlateau(monitor='val_loss', factor=0.25, patience=5, cooldown=5, min_lr=0.000000001)
]
model.fit(train_generator,
epochs=50,
verbose=1,
callbacks=keras_callbacks,
validation_data=val_generator)
RemoteMonitor callback
Above, we saw that training logs can be distributed to TensorBoard for visualization and logging purposes. However, it can be the case that you have your own logging and visualization system - whether that's a cloud-based system or a locally installed Grafana or Elastic Stack visualization tooling.
In those cases, you might wish to send the training logs there instead. The RemoteMonitor callback can help you do this.
Callback used to stream events to a server.
TensorFlow (n.d.)
It is implemented as follows:
tf.keras.callbacks.RemoteMonitor(
root='http://localhost:9000', path='/publish/epoch/end/', field='data',
headers=None, send_as_json=False
)
- With the
rootargument, you can specify the root of the endpoint to where data must be sent. - The
pathindicates the path relative torootwhere data must be sent. In other words,root + pathdescribe the full endpoint. - The JSON field under which data is sent can be configured with
field. - In
headers, additional HTTP headers (such as an Authorization header) can be provided. - With
send_as_jsonasTrue, the content type of the request will be changed toapplication/json. Otherwise, it will be sent as part of a form.
An example of using the RemoteMonitor callback with Keras:
keras_callbacks = [
RemoteMonitor(root='https://some-domain.com', path='/statistics/keras')
]
model.fit(train_generator,
epochs=50,
verbose=1,
callbacks=keras_callbacks,
validation_data=val_generator)
LambdaCallback
Say that you want a certain function to fire after every batch or every epoch - a simple function, nothing special. However, it's not provided in the collection of callbacks presented with the tensorflow.keras.callbacks API. In this case, you might want to use the LambdaCallback.
Callback for creating simple, custom callbacks on-the-fly. This callback is constructed with anonymous functions that will be called at the appropriate time. Te
TensorFlow (n.d.)
It can thus be used to provide anonymous (i.e. lambda functions without a name) functions to the training process. The callback looks as follows:
tf.keras.callbacks.LambdaCallback(
on_epoch_begin=None, on_epoch_end=None, on_batch_begin=None, on_batch_end=None,
on_train_begin=None, on_train_end=None, **kwargs
)
Here, the on_epoch_begin, on_epoch_end, on_batch_begin, on_batch_end, on_train_begin and on_train_end event based arguments can be filled with Python definitions. They are executed at the right point in time.
An example of a LambdaCallback added to your Keras model:
keras_callbacks = [
LambdaCallback(on_batch_end=lambda batch, log_data: print(batch))
]
model.fit(train_generator,
epochs=50,
verbose=1,
callbacks=keras_callbacks,
validation_data=val_generator)
TerminateOnNaN callback
In some cases (e.g. when you did not apply min-max normalization to your input data), the loss value can be very strange - outputting values close to Infinity or values that are Not a Number (NaN). In those cases, you don't want to pursue further training. The TerminateOnNaN callback can help here.
Callback that terminates training when a NaN loss is encountered.
TensorFlow (n.d.)
It is implemented as follows:
tf.keras.callbacks.TerminateOnNaN()
An example of using the TerminateOnNaN callback with your Keras model:
keras_callbacks = [
TerminateOnNaN()
]
model.fit(train_generator,
epochs=50,
verbose=1,
callbacks=keras_callbacks,
validation_data=val_generator)
CSVLogger callback
CSV files can be very useful when you need to exchange data. If you want to flush your training logs into a CSV file, the CSVLogger callback can be useful to you.
Callback that streams epoch results to a CSV file.
TensorFlow (n.d.)
It is implemented as follows:
tf.keras.callbacks.CSVLogger(
filename, separator=',', append=False
)
- The
filenameattribute determines where the CSV file is located. If there is none, it will be created. - The
separatorattribute determines what character separates the columns in a single row, and is also called delimiter. - With
append, you can indicate whether data should simply be added to the end of the file, or a new file should overwrite the old one every time.
This is an example of using the CSVLogger callback with Keras:
keras_callbacks = [
CSVLogger('./logs.csv', separator=';', append=True)
]
model.fit(train_generator,
epochs=50,
verbose=1,
callbacks=keras_callbacks,
validation_data=val_generator)
ProgbarLogger callback
When you are training a Keras model with verbosity set to True, you will see a progress bar in your terminal. With the ProgbarLogger callback, you can change what is displayed there.
Callback that prints metrics to stdout.
TensorFlow (n.d.)
It is implemented as follows:
tf.keras.callbacks.ProgbarLogger(
count_mode='samples', stateful_metrics=None
)
- With
count_mode, you can instruct Keras to display samples or steps (i.e. batches) already fed forward through the model - The
stateful_metricsattribute can contain metrics that should not be averaged over time.
Here is an example of using the ProgbarLogger callback with Keras.
keras_callbacks = [
ProgbarLogger(count_mode='samples')
]
model.fit(train_generator,
epochs=50,
verbose=1,
callbacks=keras_callbacks,
validation_data=val_generator)
Experimental: BackupAndRestore callback
When you are training a neural network, especially in a distributed setting, it would be problematic if your training process suddenly stops - e.g. due to machine failure. Every iteration passed so far will be gone. With the experimental BackupAndRestore callback, you can instruct Keras to create temporary checkpoint files after each epoch, to which you can restore later.
BackupAndRestorecallback is intended to recover from interruptions that happened in the middle of a model.fit execution by backing up the training states in a temporary checkpoint file (based on TF CheckpointManager) at the end of each epoch.TensorFlow (n.d.)
It is implemented as follows:
tf.keras.callbacks.experimental.BackupAndRestore(
backup_dir
)
Here, the backup_dir attribute indicates the folder where checkpoints should be created.
Here is an example of using the BackupAndRestore callback with Keras.
keras_callbacks = [
BackupAndRestore('./checkpoints')
]
model.fit(train_generator,
epochs=50,
verbose=1,
callbacks=keras_callbacks,
validation_data=val_generator)
Applied by default: History and BaseLogger callbacks
There are two callbacks that are part of the tensorflow.keras.callbacks API but which can be covered less extensively - because of the simple reason that they are already applied to each Keras model under the hood.
They are the History and BaseLogger callbacks.
- The
Historycallback generates aHistoryobject when callingmodel.fit. - The
BaseLoggercallback accumulates basic metrics to display later.
Creating your own callback with the Base Callback
Sometimes, neither the default or the lambda callbacks can provide the functionality you need. In those cases, you can create your own callback, by using the Base callback class tensorflow.keras.callbacks.Callback. Creating one is very simple: you define a class, create the relevant definitions (you can choose from on_epoch_begin, on_epoch_end, on_batch_begin, on_batch_end, on_train_begin and on_train_end etc.), and then add the callback to your callbacks list. There you go!
class OwnCallback(tensorflow.keras.callbacks.Callback):
def on_train_begin(self, logs=None):
print('Training is now beginning!')
keras_callbacks = [
OwnCallback()
]
model.fit(train_generator,
epochs=50,
verbose=1,
callbacks=keras_callbacks,
validation_data=val_generator)
Summary
In this article, we looked at the concept of a callback for hooking into the supervised machine learning training process. Sometimes, you want to receive additional information while you are training a model. In other cases, you want to actively steer the process into a desired direction. Both cases are possible by means of a callback.
Beyond the conceptual introduction to callbacks, we also looked at how Keras implements them - by means of the tensorflow.keras.callbacks API. We briefly looked at each individual callback provided by Keras, ranging from automated changes to hyperparameters to logging in TensorBoard, file or into a remote monitor. We also looked at creating your own callback, whether that's with a LambdaCallback for simple custom callbacks or with the Base callback class for more complex ones.
I hope that you have learned something from today's article! If you did, please feel free to leave a comment in the comments section below 💬 Please do the same if you have any questions, remarks or suggestions for improvement. Thank you for reading MachineCurve today and happy engineering! 😎
References
Keras Team. (n.d.). Keras documentation: Callbacks API. Keras: the Python deep learning API. https://keras.io/api/callbacks/
Keras Team. (2020, April 15). Keras documentation: Writing your own callbacks. Keras: the Python deep learning API. https://keras.io/guides/writing_your_own_callbacks/#a-basic-example
TensorFlow. (n.d.). Tf.keras.callbacks.ModelCheckpoint. https://www.tensorflow.org/api_docs/python/tf/keras/callbacks/ModelCheckpoint
TensorFlow. (n.d.). Tf.keras.callbacks.TensorBoard. https://www.tensorflow.org/api_docs/python/tf/keras/callbacks/TensorBoard
TensorFlow. (n.d.). Tf.keras.callbacks.EarlyStopping. https://www.tensorflow.org/api_docs/python/tf/keras/callbacks/EarlyStopping
TensorFlow. (n.d.). Tf.keras.callbacks.LearningRateScheduler. https://www.tensorflow.org/api_docs/python/tf/keras/callbacks/LearningRateScheduler
TensorFlow. (n.d.). Tf.keras.callbacks.ReduceLROnPlateau. https://www.tensorflow.org/api_docs/python/tf/keras/callbacks/ReduceLROnPlateau
TensorFlow. (n.d.). Tf.keras.callbacks.RemoteMonitor. https://www.tensorflow.org/api_docs/python/tf/keras/callbacks/RemoteMonitor
TensorFlow. (n.d.). Tf.keras.callbacks.LambdaCallback. https://www.tensorflow.org/api_docs/python/tf/keras/callbacks/LambdaCallback
TensorFlow. (n.d.). Tf.keras.callbacks.TerminateOnNaN. https://www.tensorflow.org/api_docs/python/tf/keras/callbacks/TerminateOnNaN
TensorFlow. (n.d.). Tf.keras.callbacks.BaseLogger. https://www.tensorflow.org/api_docs/python/tf/keras/callbacks/BaseLogger
TensorFlow. (n.d.). Tf.keras.callbacks.CSVLogger. https://www.tensorflow.org/api_docs/python/tf/keras/callbacks/CSVLogger
TensorFlow. (n.d.). Tf.keras.callbacks.History. https://www.tensorflow.org/api_docs/python/tf/keras/callbacks/History
TensorFlow. (n.d.). Tf.keras.callbacks.ProgbarLogger. https://www.tensorflow.org/api_docs/python/tf/keras/callbacks/ProgbarLogger
TensorFlow. (n.d.). Tf.keras.callbacks.experimental.BackupAndRestore. https://www.tensorflow.org/api_docs/python/tf/keras/callbacks/experimental/BackupAndRestore
TensorFlow. (n.d.). Tf.keras.callbacks.Callback. https://www.tensorflow.org/api_docs/python/tf/keras/callbacks/Callback

Hi, I'm Chris!
I know a thing or two about AI and machine learning. Welcome to MachineCurve.com, where machine learning is explained in gentle terms.
Getting started
Foundation models
Learn how large language models and other foundation models are working and how you can train open source ones yourself.
Keras
Keras is a high-level API for TensorFlow. It is one of the most popular deep learning frameworks.
Machine learning theory
Read about the fundamentals of machine learning, deep learning and artificial intelligence.
Most recent articles
January 2, 2024
What is Retrieval-Augmented Generation?
December 27, 2023
In-Context Learning: what it is and how it works
December 22, 2023
CLIP: how it works, how it's trained and how to use it
Article tags
Most popular articles
February 18, 2020
How to use K-fold Cross Validation with TensorFlow 2 and Keras?
December 28, 2020
Introduction to Transformers in Machine Learning
December 27, 2021
StyleGAN, a step-by-step introduction
July 17, 2019
This Person Does Not Exist - how does it work?
October 26, 2020
Your First Machine Learning Project with TensorFlow 2.0 and Keras
Connect on social media
Connect with me on LinkedIn
To get in touch with me, please connect with me on LinkedIn. Make sure to write me a message saying hi!
Side info
The content on this website is written for educational purposes. In writing the articles, I have attempted to be as correct and precise as possible. Should you find any errors, please let me know by creating an issue or pull request in this GitHub repository.
All text on this website written by me is copyrighted and may not be used without prior permission. Creating citations using content from this website is allowed if a reference is added, including an URL reference to the referenced article.
If you have any questions or remarks, feel free to get in touch.
TensorFlow, the TensorFlow logo and any related marks are trademarks of Google Inc.
PyTorch, the PyTorch logo and any related marks are trademarks of The Linux Foundation.
Montserrat and Source Sans are fonts licensed under the SIL Open Font License version 1.1.
Mathjax is licensed under the Apache License, Version 2.0.