TensorFlow Cloud: easy cloud-based training of your Keras model
October 16, 2020 by Chris
Training a supervised machine learning model does often require a significant amount of resources. With ever-growing datasets and models that continuously become deeper and sometimes wider, the computational cost of getting a well-performing model increases day after day. That's why it's sometimes not worthwhile to train your model on a machine that is running on-premise: the cost of buying and maintaining such a machine doesn't outweigh the benefits.
In those cases, cloud platforms come to the rescue. By means of various service offerings, many cloud vendors - think Amazon Web Services, Microsoft Azure and Google Cloud Platform - have pooled together resources that can be used and paid for as you use them. For example, they allow you to train your model with a few heavy machines, while you simply turn them off after you've finished training your model. In many cases, the limited costs of this approach (especially compared to the cost of owning and maintaining a heavy-resource machine) really makes training your models off-premises worthwhile.
Traditionally, training a model in the cloud hasn't been stupidly easy. TensorFlow Cloud changes this. By simply connecting to the Google Cloud Platform, with a few lines of code, it allows you to train your Keras models in the cloud. This is great, because a training job can even be started from your own machine. What's more, if desired, TensorFlow Cloud supports parallelism - meaning that you can use multiple machines for training, all at once! While training a model in the cloud was not difficult before, doing so distributed was.
In this article, we'll be exploring TensorFlow Cloud in more detail. Firstly, we'll be looking at the need for cloud-based training, by showing the need for training with heavy equipment as well as the cost of getting such a device. We then also argue for why cloud services can help you reduce the cost without losing the benefits of such heavy machinery. Subsequently, we introduce the Google Cloud AI Platform, with which TensorFlow Cloud connects for training your models. This altogether gives us the context we need for getting towards the real work.
The real work, here, is TensorFlow cloud itself. We'll introduce it by looking at the TensorFlow Cloud API and especially at the cloud strategies that can be employed, allowing you to train your model in a distributed way. After the introduction, we will show how TensorFlow Cloud can be installed and linked to your Keras model. Finally, we demonstrate how a Keras model can actually be trained in the cloud. This concludes today's article.
Let's take a look! :)
Update 02/Nov/2020: fixed issue with file name in Step 2.
The need for cloud-based training: resources required for training
Deep learning has been very popular for eight years now, as of 2020. Especially in the fields of Computer Vision and Natural Language Processing, deep learning models have outperformed previously state-of-the-art non-ML approaches. In many cases
For example, only today, I was impressed because the municipality of my nation's capital - Amsterdam - has trained and deployed deep learning models to detect garbage alongside the road, or to detect whether people maintain mandatory social distancing measures against the COVID-19 pandemic. They in fact used a variety of open source frameworks and libraries, and pretrained models - a great feat!
Now, they also argued that training some of the models was costly in terms of the computational resources that are required. For example, in a case study where a data engineer showed how a model was created for detecting bicycle road signs on road pavement, he argued that approximately 150 GB of data was to be used for training. It cost three full hours to train the model on four NVIDIA Tesla V100 GPUs, which are one of the fastest currently on the market.
With a cost of approximately $11.500 for just one 32GB GPU (and hence $46k), the investment would be enormous if you were to purchase a machine for your deep learning workloads. For $46k, you only have the GPUs! Now, even worse, it's very likely that you wouldn't run deep learning workloads for 24/7, all the time between the 'go live' moment and the end-of-life of the purchased hardware.
This is in effect a waste of money.
Cloud vendors, such as Amazon Web Services, Digital Ocean, Microsoft Azure and Google Cloud Platform have recognized this matter and have very competitive offerings available for deep learning workloads. For example, at the time of writing, a 64GB EC2 P3 machine with Amazon costs only $12.24 per hour. Yes: those 3 hours of training would now cost less than $40. That makes training worthwhile!
Training ML models in Google Cloud AI Platform
Google's offering for training deep learning models is embedded in the Google Cloud AI Platform. It's one platform to build, deploy and manage machine learning models, as the introductory text argues:
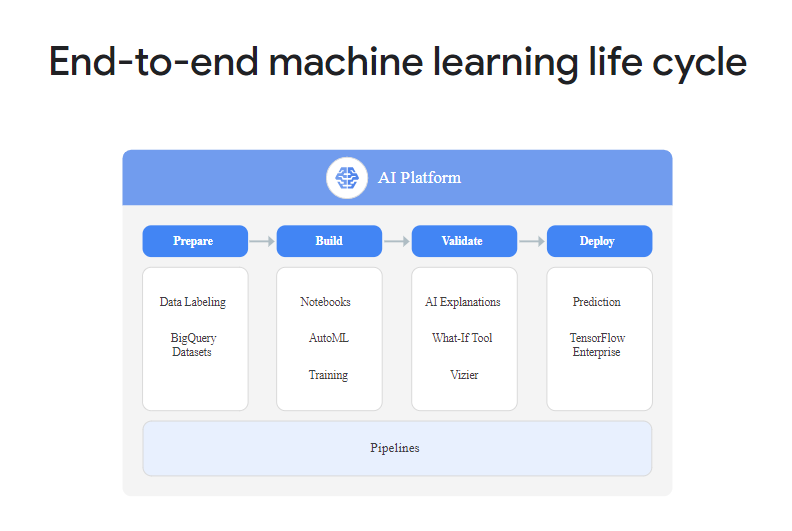
In fact, it supports multiple phases. At a high level, the AI Platform provides functionality for preparing your dataset, building your model, validating your model and deploying your model. Effectively, it allows you to do these things in the individual stages:
- Prepare stage: labeling your dataset as well as storing and retrieving it to and from Google BigQuery.
- Build: playing around with code in Notebooks, training your models on highly powered machines, and applying AutoML functionality for training automation.
- Validate: once a model is trained, the AI Platform allows you to perform activities related to explainable AI, and black-box optimization with a tool called Vizier.
- Deploy: once trained, validated and considered ready for production usage, a model can be deployed through Google too.
Today, we will be using only a minor part of the AI Platform: from the build step, we'll be using the highly powered machines to train our model with. In addition, we'll be using the Google Cloud Container Registry to temporarily store the Docker image that we'll build with TensorFlow Cloud, to be run by the AI Platform machines. As we're now talking about TensorFlow Cloud, let's inspect it in more detail, before we move on to actual coding stuff :)
The next five years of Keras: introducing TensorFlow Cloud
In early 2020, during the Scaled Machine Learning Conference, there was a talk by François Chollet - the creator of the Keras framework that is being widely used for training deep learning models today.
Below, you can see the talk, but in it, Chollet argued that three key developments will drive the next five years of Keras development:
- Automation
- Scale & Cloud
- Into the real world
https://www.youtube.com/watch?v=HBqCpWldPII
Automating models & applying them in the real world
Here, with automation, Chollet means that developments like automated hyperparameter tuning, architecture search and even Automated Machine Learning (AutoML) will help commoditize the field of Machine Learning. Gone will be the days where practicing Deep Learning will be considered a field only accessible to people who are highly familiar with mathematics and complex programming. No, instead, the ML power user (and perhaps even the more introductory user!) will provide a dataset and desired model outcomes, and some automation program will find the best set of architectural and hyper-architectural principles to apply.
With into the real world, Chollet argues that future Keras developments will focus on getting Deep Learning models out there. By packaging data preprocessing with the model, to give just an example, models can be run in the field much more robustly. In addition, it's likely that edge equipment shall be used more often, requiring the need to optimize models.
And so on, and so on!
Scaling & cloud-based training
However, related to this blog post is scaling the model and training them in the cloud. Chollet argues that it's sometimes better to not train models on-premise, for the reason that clouds provide services dedicated to training your models efficiently. We saw that training a deep learning model will be fastest when you have a heavyweight GPU in your machine. It becomes even faster by having many of such GPUs and applying a local distributed training strategy. However, it's unlikely that your deep learning machine runs 24/7, making it inefficient in terms of the total cost of ownership for such a machine.
That's why in the video, Chollet introduced TensorFlow Cloud. It's a means for training your TensorFlow model in the cloud. In fact, the TensorFlow Cloud GitHub page describes it as follows:
The TensorFlow Cloud repository provides APIs that will allow to easily go from debugging, training, tuning your Keras and TensorFlow code in a local environment to distributed training/tuning on Cloud.
TensorFlow/cloud (n.d.)
Let's now take a look at those APIs, or primarily, the TensorFlow Cloud run API.
The TensorFlow Cloud API
Within the tensorflow_cloud module that will be available upon installing TensorFlow Cloud (we will get to that later), a definition called run is available in order to let your model train in the cloud. This definition will do multiple things:
- Making your Keras code cloud ready (TensorFlow/cloud, n.d.)
- Packaging your model code into a Docker container which can be deployed in the cloud for training.
- Subsequently, deploying this container and training the model with the TensorFlow training (distribution) strategy of your choice.
- Write logs to a cloud-hosted TensorBoard.
Here is the arguments list of the def - we'll describe the arguments soon, and show an example later in this article:
def run(
entry_point=None,
requirements_txt=None,
docker_config="auto",
distribution_strategy="auto",
chief_config="auto",
worker_config="auto",
worker_count=0,
entry_point_args=None,
stream_logs=False,
job_labels=None,
**kwargs
):
"""Runs your Tensorflow code in Google Cloud Platform.
Those are the arguments:
- The entry_point describes where TensorFlow Cloud must pick up your Python code (e.g. a file called
keras.py) or your Notebook (*.ipynb) for preprocessing and packaging it into a Docker container. - The requirements_txt (optional) is the file path to a file called
requirements.txtwhere you can specify additionalpippackages to be installed. - The docker_config (optional) allows you to configure additional settings for the Docker container. For example, by configuring the
base_image, you can specify a custom Docker image to start with as base image, and withimage_build_bucketyou can specify a bucket where Google Cloud Platform stores the built container if you choose to build it in the cloud. It defaults to 'auto', which means that default settings are used. - The distribution_strategy (optional) allows you to pick a training strategy for your cloud-based training. Those are distributed TensorFlow training strategies which we will cover in more detail later in this article. By default, it is set to 'auto', which means that an appropriate strategy is automatically inferred based on
chief_config,worker_configandworker_count. - In a distributed training scenario, it is often the case that one machine is the leader whereas others are followers. This ensures that there will be no decision-making issues related to the coordination of information about e.g. the state of a machine. The chief_config allows you to pick the Google Cloud Platform machine type for your 'chief', a.k.a. the leader. By default, it is set to 'auto', which means the deployment of a
COMMON_MACHINE_CONFIGS.T4_1Xmachine (8 cpu cores, 30GB memory, 1 Nvidia Tesla T4). - The worker_config (optional) describes the machine type of your workers, a.k.a. the followers. By default, it is also set to auto, meaning the deployment of a
COMMON_MACHINE_CONFIGS.T4_1Xmachine (8 cpu cores, 30GB memory, 1 Nvidia Tesla T4). - The worker_count (optional) describes the number of workers you want to deploy besides your chief.
- The entry_point_args (optional), which should be a list of Strings, represents extra arguments to be input to the program run through the
entry_point. - If enabled, stream_logs (optional, default False) streams logs back from the training job in the cloud.
- With job_labels (optional), you can specify up to 64 key-value pairs of labels and values that together organize the cloud training jobs. Very useful in a scenario where you'll train a lot of TensorFlow models in the cloud, as you can organize stuff programmatically instead of manually.
Available machine configurations
For worker_config and chief_config, there are many out-the-box machine configurations available within TensorFlow Cloud:
COMMON_MACHINE_CONFIGS = {
"CPU": MachineConfig(
cpu_cores=4,
memory=15,
accelerator_type=AcceleratorType.NO_ACCELERATOR,
accelerator_count=0,
),
"K80_1X": MachineConfig(
cpu_cores=8,
memory=30,
accelerator_type=AcceleratorType.NVIDIA_TESLA_K80,
accelerator_count=1,
),
"K80_4X": MachineConfig(
cpu_cores=16,
memory=60,
accelerator_type=AcceleratorType.NVIDIA_TESLA_K80,
accelerator_count=4,
),
"K80_8X": MachineConfig(
cpu_cores=32,
memory=120,
accelerator_type=AcceleratorType.NVIDIA_TESLA_K80,
accelerator_count=8,
),
"P100_1X": MachineConfig(
cpu_cores=8,
memory=30,
accelerator_type=AcceleratorType.NVIDIA_TESLA_P100,
accelerator_count=1,
),
"P100_4X": MachineConfig(
cpu_cores=16,
memory=60,
accelerator_type=AcceleratorType.NVIDIA_TESLA_P100,
accelerator_count=4,
),
"P4_1X": MachineConfig(
cpu_cores=8,
memory=30,
accelerator_type=AcceleratorType.NVIDIA_TESLA_P4,
accelerator_count=1,
),
"P4_4X": MachineConfig(
cpu_cores=16,
memory=60,
accelerator_type=AcceleratorType.NVIDIA_TESLA_P4,
accelerator_count=4,
),
"V100_1X": MachineConfig(
cpu_cores=8,
memory=30,
accelerator_type=AcceleratorType.NVIDIA_TESLA_V100,
accelerator_count=1,
),
"V100_4X": MachineConfig(
cpu_cores=16,
memory=60,
accelerator_type=AcceleratorType.NVIDIA_TESLA_V100,
accelerator_count=4,
),
"T4_1X": MachineConfig(
cpu_cores=8,
memory=30,
accelerator_type=AcceleratorType.NVIDIA_TESLA_T4,
accelerator_count=1,
),
"T4_4X": MachineConfig(
cpu_cores=16,
memory=60,
accelerator_type=AcceleratorType.NVIDIA_TESLA_T4,
accelerator_count=4,
),
"TPU": MachineConfig(
cpu_cores=None,
memory=None,
accelerator_type=AcceleratorType.TPU_V3,
accelerator_count=8,
),
}
Cloud distribution strategies
We saw that it is possible to pick a particular cloud distribution strategy when training a TensorFlow model by means of TensorFlow cloud. A distribution strategy is a common term for those who are already used to distributed training, but then locally, using multiple GPUs in e.g. one or multiple machines.
Here are the cloud distribution strategies available within TensorFlow Cloud. We'll cover them in more detail next:
- No distribution: a CPU-based chief without any workers.
- OneDeviceStrategy: a GPU-based chief without any workers.
- MirroredStrategy: a GPU-based chief with multiple GPUs, without any additional workers.
- MultiWorkerMirroredStrategy: a GPU-based chief with multiple GPUs, as well as additional workers
- TPUStrategy: a TPU-based config with a chief having 1 CPU and one worker having a TPU.
- Custom distribution strategy: picking a custom strategy is also possible, requiring you to turn off TensorFlow Cloud based distribution strategies.
Below, we'll cover those strategies in more detail. The code samples come from the TensorFlow Cloud GitHub page and are licensed under the Apache License 2.0.
No distribution
If you choose to train some_model.py in the cloud without any distribution strategy, TensorFlow Cloud will interpret your choice as "I don't want any GPUs to train with". In this case, it will spawn a CPU-based machine - i.e. one chief that runs on a CPU - and trains your model there. This could be an interesting choice from a cost perspective or getting used to using TensorFlow cloud, but it's not the best choice in terms of training a model at scale.
tfc.run(entry_point='some_model.py',
chief_config=tfc.COMMON_MACHINE_CONFIGS['CPU'])
OneDeviceStrategy
If you choose for a OneDeviceStrategy, TensorFlow Cloud will spawn a chief in Google Cloud Platform with one GPU attached. More specifically, it will spawn a T4_1X strategy, which means a machine having 8 cpu cores, 30GB memory, and 1 Nvidia Tesla T4. This will already give your training process a significant boost. Remember that by means of chief_config, you can choose to use another machine type, e.g. if you want a more powerful GPU.
tfc.run(entry_point='some_model.py')
MirroredStrategy
Choosing a MirroredStrategy will equal a mirrored strategy in local distributed training - that is, it will benefit from multiple GPUs on one machine. In this case, a machine will be spawned with 4 V100 GPUs, which will give your training process an enormous boost:
tfc.run(entry_point='some_model.py',
chief_config=tfc.COMMON_MACHINE_CONFIGS['V100_4X'])
MultiWorkerMirroredStrategy
If that's still not enough, you can also deploy a MultiWorkerMirroredStrategy. A mouth full of words, this strategy effectively combines the MirroredStrategy with a multi-device scenario. That is, here, beyond the chief_config, you also specify the config of your workers, as well as the number of workers you want. In the example below, one chief will run with one V100 GPU, whereas two workers will be spawned with 8 V100 GPUs each.
This will result in an extremely fast training process, but will also result in significant cost if you still have a substantial training operation. However, so do the other GPU-based and cloud strategies, so choose wisely!
tfc.run(entry_point='some_model.py',
chief_config=tfc.COMMON_MACHINE_CONFIGS['V100_1X'],
worker_count=2,
worker_config=tfc.COMMON_MACHINE_CONFIGS['V100_8X'])
TPUStrategy
If, however, you don't want to train your model with a GPU but with a TPU (a processing unit specifically tailored to Tensors and hence a good choice for training TensorFlow models), you can do so by employing a TPUStrategy:
tfc.run(entry_point="some_model.py",
chief_config=tfc.COMMON_MACHINE_CONFIGS["CPU"],
worker_count=1,
worker_config=tfc.COMMON_MACHINE_CONFIGS["TPU"])
Here, the chief runs with a CPU, while you have one TPU-based worker. At the time of writing, this only works with TensorFlow 2.1, which is the only version currently supported to run with a TPU-based strategy. (Please leave a comment if this is no longer the case, and I'll make sure to adapt!)
Custom distribution strategy
Sometimes, all the strategies mentioned before do not meet your requirements. In this case, it becomes possible to define a custom distribution strategy - but you must do so within your model code, as with regular distributed TensorFlow. In order not to have TensorFlow cloud interfere with your custom distribution strategy, you must turn it off in the TF Cloud code:
tfc.run(entry_point='some_model.py',
distribution_strategy=None,
worker_count=2)
Installing TensorFlow Cloud
Let's now take a look at how to install TensorFlow Cloud :)
Step 1: ensure that you meet the dependencies
First of all, it is important that you ensure that you have met all the dependencies for running TensorFlow cloud on your machine. Those dependencies are as follows:
- Python: you'll need Python version >= 3.5 (check with
python -V) - TensorFlow: you'll need TensorFlow 2.x, since you'll train a Keras model.
- Google Cloud Project: TensorFlow Cloud will run as this project.
- An authenticated GCP Service account: you'll need to authenticate as yourself if you wish to run jobs in the cloud, so you'll also need this.
- Google AI Platform APIs enabled: the AI platform is used for the deployment of the built Docker images on the Google Cloud Platform.
- Docker, or a Google Cloud Storage bucket/Google Cloud Build: although the creators of TensorFlow Cloud argue that it's better to use Google Cloud Build to build the Docker container, you can optionally do so as well with your local Docker daemon.
- Authentication to the Docker Container Registry.
- Nbconvert (optional) if you want to train directly from a Jupyter Notebook.
If you don't meet the requirements, don't worry. While you will need to install the correct Python version yourself, and will need to create your own Google account, we will take you through all the necessary steps
Step 2: becoming Google Cloud Ready
The first step is becoming 'cloud ready' with the Google Cloud Platform. We assume that you have already created a Google Account.
Becoming Cloud Ready involves two primary steps:
- Creating a Google Cloud Project that has the necessary APIs enabled.
- Creating a GCP service account for authenticating to the cloud from your machine.
Step 2A: create a Google Cloud Project with enabled APIs
First, navigate to the Project Selector page in the Google Cloud Platform, which looks like this:
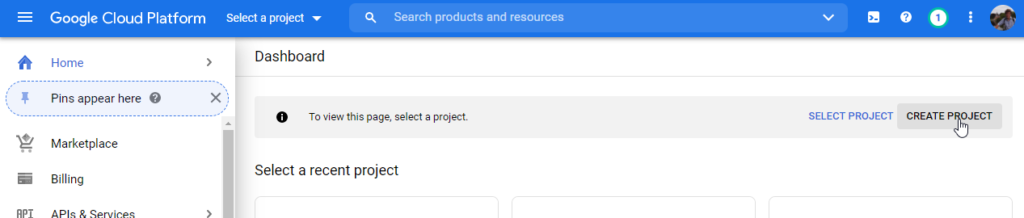
Select an existing project or create a new one by clicking 'Create Project'. This should look like this:
Then, make sure to enable billing: you can find out how here.
If you have created a Google Cloud Project (e.g. named TF Cloud, like me) and have enabled billing, it's time to enable the APIs that we need for running TensorFlow Cloud! Click here, which will allow you to enable the AI Platform Training & Prediction API and the Compute Engine API in your project.
Step 2B: creating a GCP service account for authentication
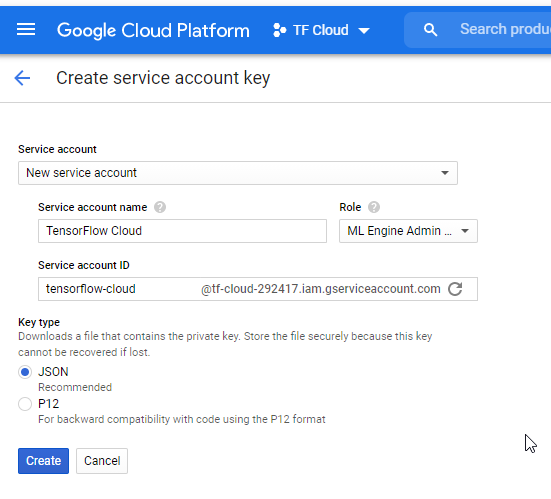
The next step is ensuring that you created what is called a Service Account for authenticating yourself from your machine. This can be done here. After having navigated to this page, follow the following steps:
- From the dropdown list Service account, click New service account.
- Enter a name in the Service account name field.
- Add the following Role items: Machine Learning Engineer > ML Engine Admin, and Storage > Storage Object Admin. Those roles ensure that you can (1) train your model in the cloud, and (2) store your built container in Google Cloud Storage.
- Click Create. Now, a JSON file containing the key of your service account is downloaded to your computer. Move it into some relatively persistent directory, e.g.
/home/username/tensorflow/credentials.json. - Export the path to the JSON file to
GOOGLE_APPLICATION_CREDENTIALS:- On Linux or MacOS, run
export GOOGLE_APPLICATION_CREDENTIALS="[PATH]"in a terminal, with[PATH]replaced by the path to your credentials file. - On Windows, open PowerShell (right mouse click on the Start Windows logo, then PowerShell, preferably Admin rights enabled), and run
$env:GOOGLE_APPLICATION_CREDENTIALS="[PATH]", with[PATH] replaced by the path to your credentials file. You might also wish to do so via the Start menu, then Environment variables (type this into your Win8/10 search bar), adding theGOOGLE_APPLICATION_CREDENTIALSvariable in the GUI. Sometimes, this works better than the other way.
- On Linux or MacOS, run
Step 3: install and configure latest TensorFlow Cloud
Now that you have enabled the necessary Google Cloud APIs and have become cloud ready for training your model, it's time to install TensorFlow Cloud. While the steps 1 and 2 looked a bit complex, installing TensorFlow Cloud is really easy and can be done with pip:
pip install -U tensorflow-cloud
Step 4: install Docker if you don't want to build your containers in the cloud
If you don't want to build the Docker container in which your training job runs in the cloud, you can also build it with a running Docker daemon on your machine. In that case, you must install Docker on your machine. Please find instructions for doing so here: Get Docker.
Step 5: install nbconvert if you'll train from a Jupyter Notebook
If you want to train in the cloud from a Jupyter Notebook, you must convert it into a workable format first. Nbconvert can be us ed for this purpose. Hence, if you want to run cloud-based training from a Jupyter Notebook - which is entirely optional, as it can be ran from .py files as well - then nbconvert must be installed as follows:
pip install nbconvert
Training your Keras model
Now that we have installed TensorFlow Cloud, it's time to look at training the Keras model itself - i.e., in the cloud. This involves four main steps:
- Creating a Keras model
- Training it locally, to ensure that it works
- Adding code for TensorFlow Cloud
- Running it!
Let's take a look in more detail.
Step 1: pick a Keras model to train
For training our Keras model in the cloud, we need - well, a Keras model. The model below is a relatively simple Convolutional Neural Network, for the creation of which you can find a detailed article here. Within a few iterations, it can reach significant accuracies on the MNIST dataset. Precisely this simplicity is what makes the model easy to follow, and why it's good for an educational setting like this. Obviously, you wouldn't train such easy and simple models in the cloud normally.
Open up your code editor, create a file called model.py, and add the following code.
import tensorflow
from tensorflow.keras.datasets import mnist
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense, Dropout, Flatten
from tensorflow.keras.layers import Conv2D, MaxPooling2D
# Model configuration
img_width, img_height = 28, 28
batch_size = 250
no_epochs = 1
no_classes = 10
validation_split = 0.2
verbosity = 1
# Load MNIST dataset
(input_train, target_train), (input_test, target_test) = mnist.load_data()
input_shape = (img_width, img_height, 1)
# Reshape data for ConvNet
input_train = input_train.reshape(input_train.shape[0], img_width, img_height, 1)
input_test = input_test.reshape(input_test.shape[0], img_width, img_height, 1)
input_shape = (img_width, img_height, 1)
# Parse numbers as floats
input_train = input_train.astype('float32')
input_test = input_test.astype('float32')
# Normalize [0, 255] into [0, 1]
input_train = input_train / 255
input_test = input_test / 255
# Convert target vectors to categorical targets
target_train = tensorflow.keras.utils.to_categorical(target_train, no_classes)
target_test = tensorflow.keras.utils.to_categorical(target_test, no_classes)
# Create the model
model = Sequential()
model.add(Conv2D(32, kernel_size=(3, 3), activation='relu', input_shape=input_shape))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Dropout(0.25))
model.add(Conv2D(64, kernel_size=(3, 3), activation='relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Dropout(0.25))
model.add(Flatten())
model.add(Dense(256, activation='relu'))
model.add(Dense(no_classes, activation='softmax'))
# Compile the model
model.compile(loss=tensorflow.keras.losses.categorical_crossentropy,
optimizer=tensorflow.keras.optimizers.Adam(),
metrics=['accuracy'])
# Fit data to model
model.fit(input_train, target_train,
batch_size=batch_size,
epochs=no_epochs,
verbose=verbosity,
validation_split=validation_split)
# Generate generalization metrics
score = model.evaluate(input_test, target_test, verbose=0)
print(f'Test loss: {score[0]} / Test accuracy: {score[1]}')
Step 2: train it locally, but briefly, to see that it works
Before running your model in the cloud, we should ensure that it can train properly. That is, that it loads data properly, that it configures the model properly, and that the training process starts.
This is why we set the no_epochs to 1 in the configuration options above. It will train for just one iteration, and will show us whether it works.
Open up a terminal, cd to the folder where your model.py file is located, and run python model.py. If all is well, possibly including the download of the MNIST dataset, you should eventually see the following:
48000/48000 [==============================] - 6s 132us/sample - loss: 0.3527 - accuracy: 0.8942 - val_loss: 0.0995 - val_accuracy: 0.9712
Test loss: 0.08811050849966705 / Test accuracy: 0.9728000164031982
Step 3: invoking it with TensorFlow cloud
Time to add TensorFlow Cloud!
Create another file called cloud.py, and open it in your code editor.
First of all, make sure to add TensorFlow Cloud into your new file:
import tensorflow_cloud as tfc
Then add the run call for TensorFlow Cloud:
# Add TensorFlow cloud
tfc.run(
entry_point='model.py',
distribution_strategy='auto',
requirements_txt='requirements.txt',
chief_config=tfc.COMMON_MACHINE_CONFIGS['V100_4X'],
worker_count=0)
Here, we specify that the model we want to run resides in model.py (which it does), that we let TF Cloud determine the distribution strategy, that additional requirements are specified in requirements.txt (so make sure to create that file too, even though you can leave it empty), and that we will run our chief on a machine that has 4 Tesla V100 GPUs. We don't use any workers.
Step 4: Run it!
Time to run it! Open up your terminal, navigate to the folder where your cloud.py and model.py files are located, and run python cloud.py.
Error: Python version mismatch
The first time I ran my cloud.py, I got this error:
>>> from google.auth.transport import mtls
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
ImportError: cannot import name 'mtls' from 'google.auth.transport'
Strange! For some reason, it seemed that an old version of google-auth was installed or came installed with TensorFlow Cloud. I'm not sure, but if you're running into this issue, the fix is as follows: install version 1.17.2 or newer, like this.
pip install google-auth==1.17.2
Then, when you run again, it starts building the Docker container:
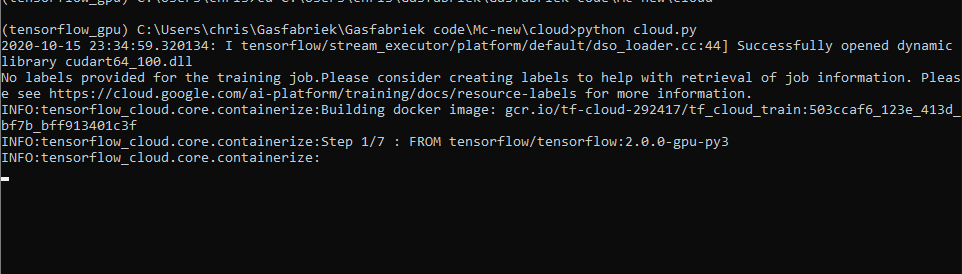
This takes quite some time, because downloading the TensorFlow base image is quite resource-intensive.
Error: GCP unauthorized
The next error you may face now is the following:
RuntimeError: Docker image publish failed: unauthorized: You don't have the needed permissions to perform this operation, and you may have invalid credentials. To authenticate your request, follow the steps in: https://cloud.google.com/container-registry/docs/advanced-authentication
Run gcloud auth configure-docker and confirm the settings:
{
"credHelpers": {
"gcr.io": "gcloud",
"marketplace.gcr.io": "gcloud",
"eu.gcr.io": "gcloud",
"us.gcr.io": "gcloud",
"staging-k8s.gcr.io": "gcloud",
"asia.gcr.io": "gcloud"
}
}
Do you want to continue (Y/n)? y
Publishing!
When you now run again, it should seem as if the process freezes at publishing:
INFO:tensorflow_cloud.core.containerize:Publishing docker image: gcr.io/tf-cloud-292417/tf_cloud_train:f852b25b_2b3c_4f92_a70a_d0544c99e02c
This is in fact good, because it is actually sending your built image into the Google Container Registry. Here, it will be available for the AI Platform to run.
TypeError: default() got an unexpected keyword argument 'quota_project_id'
If you're getting this error, you might wish to update google-auth with pip:
pip install --upgrade google-auth
It could be the case that your google-auth version was old, too old for the quota_project_id keyword argument. In my case, the upgrade fixed the issue, and as we can see I had an old version installed:
Installing collected packages: google-auth
Attempting uninstall: google-auth
Found existing installation: google-auth 1.17.2
Uninstalling google-auth-1.17.2:
Successfully uninstalled google-auth-1.17.2
Successfully installed google-auth-1.22.1
PermissionError: [WinError 32] The process cannot access the file because it is being used by another process
On Windows, you may now run into the error mentioned above. After building the Docker image and publishing it to the Google Cloud Registry, the Python script crashes. At least, that's what happens at the time of writing.
The reason is simple: TensorFlow Cloud creates temporary files for e.g. the Docker image, and attempts to remove those when the publish is completed. This is very neat, because that's what should be done - however, Python (at least on Windows) expects the files to be closed before they can be removed. Because TensorFlow Cloud doesn't close the files, the script crashes with the expected error mentioned above.
I've provided a fix which is hopefully merged with the main repository soon. For the time being, you can adapt your files manually. After that, jobs are submitted successfully:
Job submitted successfully.
Your job ID is: tf_cloud_train_eb615bf8_795a_4138_92dd_6f0a81abde40
Looking at the training process in Google Cloud Platform
You can now take a look at the Google Cloud Platform to see how your job performs:
Please access your training job information here:
https://console.cloud.google.com/mlengine/jobs/tf_cloud_train_eb615bf8_795a__SOME_OTHER
Please access your training job logs here: https://console.cloud.google.com/logs/viewer?resource=ml_job%2Fjob_id%2Ftf_cloud_train_eb615bf8_795a_4138_SOME_OTHER
Those URLs were made shorter on purpose.
When doing so, you'll first see that your job starts running. It can take a while for the job to prepare, but eventually it will start:

With the second URL, you can follow the logs in real-time:

Clearly, the MNIST-based model rushed through the 100 epochs, as expected. It was able to perform epochs of 40k samples with < 1 second per epoch. That's truly impressive!
Don't forget to remove your files!
When ready, it's important to don't forget removing your files, because otherwise you might end up paying for Storage:
- From the Container Registry: https://console.cloud.google.com/gcr
- From the Cloud Storage bucket: https://console.cloud.google.com/storage
- The reference to the Job in AI Platform doesn't have to be removed, because you're only paying for the Compute time it cost.
Summary
In this article, we focused on training a Keras deep learning model in the cloud. Doing so is becoming increasingly important these days, as models become deeper, data sets become larger, and the trade-off between purchasing on-premise GPUs versus cloud-based GPUs is increasingly being won by the cloud. This makes the need for training your machine learning models in the cloud significant.
Unfortunately, training a TensorFlow/Keras model in the cloud was relatively difficult up to now. Not too difficult, but it cost some time to set up a specific machine learning instance such as in Amazon AMI, copy the model there, and then train it. Fortunately, for TensorFlow and Keras models, today there is TensorFlow Cloud: an extension of TensorFlow that packages your model into a Docker container, and then stores it in the Google Cloud Container Registry for training in the Google Cloud AI Platform.
In the article, we introduced the AI Platform, but then also focused on the characteristics of TensorFlow cloud. TensorFlow Cloud allows you to train your models by means of a variety of distribution strategies, letting you determine what kind of machine you need and what hardware it should contain, or whether you need a multi-machine-multi-GPU setup. It then builds your Docker container and starts the training process.
I hope that you've learnt a lot from this article. Although I read quite a bit about training deep learning models in the cloud, until now, I never actually sent one there for training. It's really great to see the progress made in this regard. Please feel free to leave a comment if you have any questions, remarks or other comments. I'll happily answer them and improve my article to make it better. Thank you for reading MachineCurve today and happy engineering! 😎
References
TensorFlow/cloud. (n.d.). GitHub. https://github.com/tensorflow/cloud
Chollet, F. (2020). Franćois Chollet - Keras: The Next Five Years. YouTube. https://www.youtube.com/watch?v=HBqCpWldPII
Tf.distribute.experimental.MultiWorkerMirroredStrategy. (n.d.). TensorFlow. https://www.tensorflow.org/api_docs/python/tf/distribute/experimental/MultiWorkerMirroredStrategy
Tf.distribute.MirroredStrategy. (n.d.). TensorFlow. https://www.tensorflow.org/api_docs/python/tf/distribute/MirroredStrategy
Tf.distribute.OneDeviceStrategy. (n.d.). TensorFlow. https://www.tensorflow.org/api_docs/python/tf/distribute/OneDeviceStrategy
Tf.distribute.TPUStrategy. (n.d.). TensorFlow. https://www.tensorflow.org/api_docs/python/tf/distribute/TPUStrategy
NVIDIA Tesla V100 price analysis. (2018, August 17). Microway. https://www.microway.com/hpc-tech-tips/nvidia-tesla-v100-price-analysis/
Amazon EC2 P3 – Ideal for machine learning and HPC - AWS. (n.d.). Amazon Web Services, Inc. https://aws.amazon.com/ec2/instance-types/p3/

Hi, I'm Chris!
I know a thing or two about AI and machine learning. Welcome to MachineCurve.com, where machine learning is explained in gentle terms.
Getting started
Foundation models
Learn how large language models and other foundation models are working and how you can train open source ones yourself.
Keras
Keras is a high-level API for TensorFlow. It is one of the most popular deep learning frameworks.
Machine learning theory
Read about the fundamentals of machine learning, deep learning and artificial intelligence.
Most recent articles
January 2, 2024
What is Retrieval-Augmented Generation?
December 27, 2023
In-Context Learning: what it is and how it works
December 22, 2023
CLIP: how it works, how it's trained and how to use it
Article tags
Most popular articles
February 18, 2020
How to use K-fold Cross Validation with TensorFlow 2 and Keras?
December 28, 2020
Introduction to Transformers in Machine Learning
December 27, 2021
StyleGAN, a step-by-step introduction
July 17, 2019
This Person Does Not Exist - how does it work?
October 26, 2020
Your First Machine Learning Project with TensorFlow 2.0 and Keras
Connect on social media
Connect with me on LinkedIn
To get in touch with me, please connect with me on LinkedIn. Make sure to write me a message saying hi!
Side info
The content on this website is written for educational purposes. In writing the articles, I have attempted to be as correct and precise as possible. Should you find any errors, please let me know by creating an issue or pull request in this GitHub repository.
All text on this website written by me is copyrighted and may not be used without prior permission. Creating citations using content from this website is allowed if a reference is added, including an URL reference to the referenced article.
If you have any questions or remarks, feel free to get in touch.
TensorFlow, the TensorFlow logo and any related marks are trademarks of Google Inc.
PyTorch, the PyTorch logo and any related marks are trademarks of The Linux Foundation.
Montserrat and Source Sans are fonts licensed under the SIL Open Font License version 1.1.
Mathjax is licensed under the Apache License, Version 2.0.