TensorFlow pruning schedules: ConstantSparsity and PolynomialDecay
September 29, 2020 by Chris
Today's deep learning models can become very large. That is, the weights of some contemporary model architectures are already approaching 500 gigabytes if you're working with pretrained models. In those cases, it is very difficult to run the models on embedded hardware, requiring cloud technology to run them successfully for model inference.
This is problematic when you want to generate predictions in the field that are accurate. Fortunately, today's deep learning frameworks provide a variety of techniques to help make models smaller and faster. In other blog articles, we covered two of those techniques: quantization and magnitude-based pruning. Especially when combining the two, it is possible to significantly reduce the size of your deep learning models for inference, while making them faster and while keeping them as accurate as possible.
They are interesting paths to making it possible to run your models at the edge, so I'd recommend the linked articles if you wish to read more. In this blog post, however, we'll take a more in-depth look at pruning in TensorFlow. More specifically, we'll first take a look at pruning by providing a brief and high-level recap. This allows the reader who hasn't read the posts linked before to get an idea what we're talking about. Subsequently, we'll be looking at the TensorFlow Model Optimization API, and specifically the tfmot.sparsity.keras.PruningSchedule functionality, which allows us to use preconfigured or custom-designed pruning schedules.
Once we understand PruningSchedule, it's time to take a look at two methods for pruning that come with the TensorFlow Model Optimization toolkit: the ConstantSparsity method and the PolynomialDecay method for pruning. We then converge towards a practical example with Keras by using ConstantSparsity to make our model sparser. If you want to get an example for PolynomialDecay, click here instead.
Enough introduction for now! Let's start :)
A brief recap on Pruning
If we train a machine learning model by means of a training, validation and testing dataset, we're following a methodology that is called supervised learning. If you look at the name, it already tells you much about how it works: by supervising the learning process, you'll allow the model to learn generate successful predictions for new situations. Supervision, here, means to let the model learn and check its predictions with the true outcome later. It is a highly effective form of machine learning and is used very often in today's machine learning settings.
Training a machine learning model: the iterative learning process
If we look at supervised learning in more detail, we can characterize it as follows:
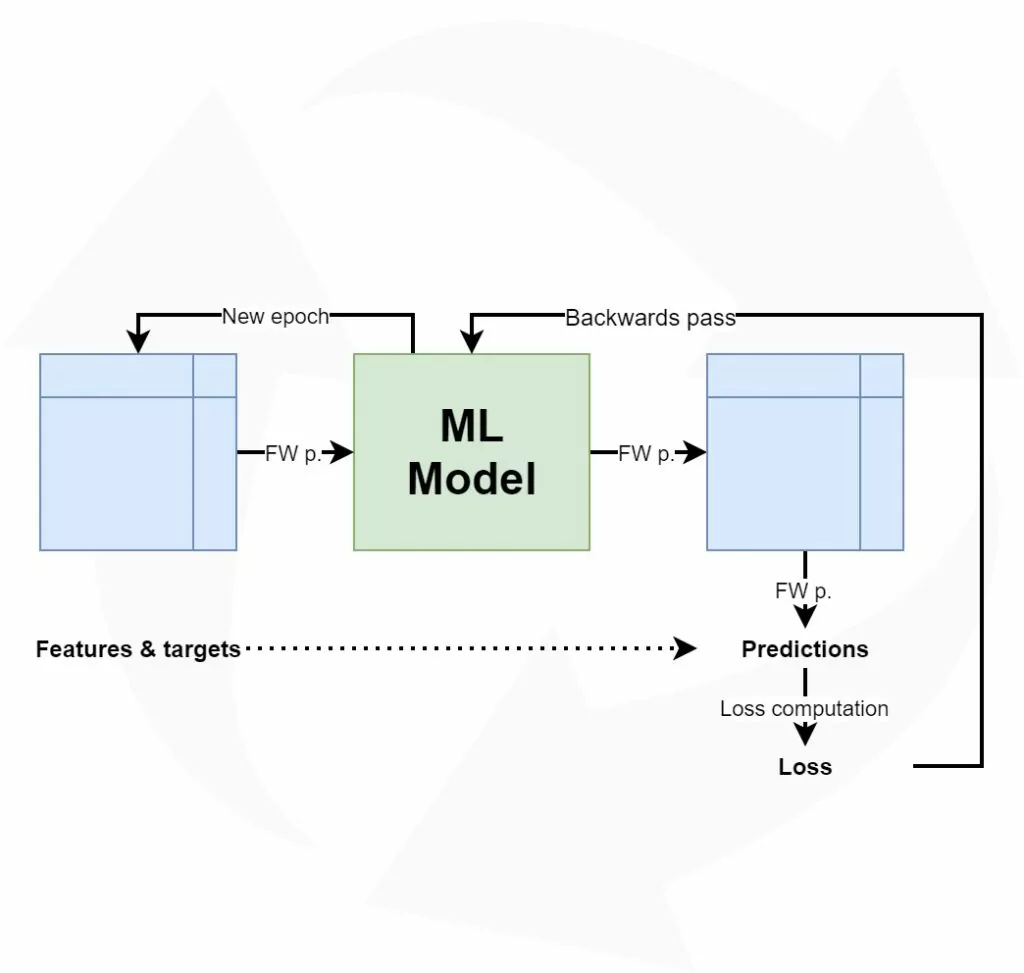
We start our training process with a model where the weights are initialized pseudorandomly, with a small alteration given vanishing and exploding gradients. A model "weight" is effectively a vector that contains (part of the) learnt ability, and stores it numerically. All model weights, which are stored in a hierarchical fashion through layers, together capture all the patterns that have been learnt during training. Generating a new prediction involves a vector multiplication between the first-layer weight vectors and the vector of your input sample, subsequently passing the output to the next layer, and repeating the process for all downstream layers. The end result is one prediction, which can be a predicted class or a regressed real-valued number.
In terms of the machine learning process outlined above, we call feeding the training data to the model a forward pass. When data is passed forward, a prediction is computed for the input vector. In fact, this is done for all input vectors, generating as many predictions as there are training rows. Now that all the predictions are in, we can compare them with the ground truth - hence the supervision. In doing so, we can compute an average that represents the average error in the model, called a loss value. Using this loss value, we can subsequently compute the error contribution of individual neurons and subsequently perform optimization using gradient descent or modern optimizers.
Repeating this process allows us to continuously adapt our weights until the loss value is lower than a predefined threshold, after which we (perhaps automatically) stop the training process.
Model optimization: pruning and quantization
Many of today's state-of-the-art machine learning architectures are really big - 100 MB is no exception, and some architectures are 500 MB when they are trained. As we understand from the introduction and the linked article, it's highly impractical if not impossible to run those models adequately on embedded hardware, such as devices in the field.
They will then either be too slow or they cannot be loaded altogether.
Using pruning and quantization, we can attempt to reduce model size. We studied pruning in detail in a different blog article. Let's now briefly cover what it is before we continue by studying the different types of pruning available in TensorFlow.
Applying pruning to keep the important weights only
If we train a machine learning model, we can attempt to find out how much every model weight contributes to the final outcome. It should be clear that if a weight does not contribute significantly, it is not worth it to keep it in the model. In fact, there are many reasons why those weights should be thrown out - a.k.a., set to zero, making things sparse, as this is called:
- Compressing the model will be much more effective given the fact that sparse data can be compressed much better, decreasing the requirements for model storage.
- Running the model will be faster because sparse representations will always produce zero outputs (i.e., multiplying anything with 0 yields 0). Programmatically, this means that libraries don't have to perform vector multiplications when weights are sparse - making the prediction faster.
- Loading the model on embedded software will also be faster given the previous two reasons.
This is effectively what pruning does: it checks which weights contribute most, and throws out everything else that contributes less than a certain threshold. This is called magnitude-based pruning and is applied in TensorFlow. Since pruning happens during training, the weights that do contribute significantly enough can adapt to the impact of the weights-thrown-out, making the model as a whole robust against sparsity on the fly.
While one must be very cautious still, since pruning (and quantization) can significantly impact model performance, both pruning and quantization can be great methods for optimizing your machine learning models.
Pruning in TensorFlow
Now that we know how supervised machine learning models are trained and how pruning works conceptually, we can take a look at how TensorFlow provides methods for pruning. Specifically, this is provided through the TensorFlow Model Optimization toolkit, which must be installed separately (and is no core feature of TF itself, but integrates natively).
For pruning, it provides two methods:
ConstantSparsitybased pruning, which means that sparsity is kept constant during training.PolynomialDecaybased pruning, which means that the degree of sparsity is changed during training.
Generic terminology
Before we can look into ConstantSparsity and PolynomialDecay pruning schedules in more detail, we must take a look at some generic terminology first. More specifically, we'll discuss pruning schedules - implemented by means of a PruningSchedule - as well as pruning steps.
Pruning schedule
Applying pruning to a TensorFlow model must be done by means of a pruning schedule (PruningSchedule, n.d.). It "specifies when to prune layer and the sparsity(%) at each training step". More specifically:
PruningSchedule controls pruning during training by notifying at each step whether the layer's weights should be pruned or not, and the sparsity(%) at which they should be pruned.
Essentially, it provides the necessary wrapper for pruning to take place in a scalable way. That is, while the pruning schedule instance (such as ConstantSparsity) determines how pruning must be done, the PruningSchedule class provides the skeleton for communicating the schedule. That is, it produces information about whether a layer should be pruned at a particular pruning step (by means of should_prune) and if so, what sparsity it must be pruned for.
Pruning steps
Now that we know about a PruningSchedule, we understand that it provides the skeleton for a pruning schedule to work. Any pruning schedule instance will thus tell you about whether pruning should be applied and what sparsity should be generated, but it will do so for a particular step. This terminology - pruning steps -confused me, because well, what is a step? Is it equal to an epoch? If it is, why isn't it called epoch? If it's not, what is it?
In order to answer this question, I first looked at the source code for PruningSchedule on GitHub. As we know, TensorFlow is open source, and hence its code is available for everyone to see (TensorFlow/model-optimization, 2020). While it provides code that outputs whether to prune (_should_prune_in_step), it does not provide any explanation for the concept of a step.
However, in the article about pruning, we saw that we must add the UpdatePruningStep callback to the part where pruning is applied. That is, after an epoch or a batch, it is applied to the model in question (Keras Team, n.d.). For this reason, it would be worthwhile to continue the search in the source code for the UpdatePruningStep callback.
Here, we see the following:
def on_train_batch_begin(self, batch, logs=None):
tuples = []
for layer in self.prunable_layers:
tuples.append((layer.pruning_step, self.step))
K.batch_set_value(tuples)
self.step = self.step + 1
This code is executed upon the start of every batch. To illustrate, if your training set has 1000 samples and you have a batch size of 250, every epoch will consist of 4 batches. Per epoch, the code above will be called 4 times.
In it, the pruning step is increased by one: self.step = self.step + 1.
This means that every batch during your training process represents a pruning step. This is also why in the pruning article, we configured the end_step as follows:
end_step = np.ceil(num_images / batch_size).astype(np.int32) * pruning_epochs
That's the number of images divided by the batch size (i.e., the number of steps per epoch) times the number of epochs; this produces the total number of steps performed during pruning.
ConstantSparsity based pruning
TensorFlow's constant sparsity during pruning can be characterized as follows (ConstantSparsity, n.d.):
Pruning schedule with constant sparsity(%) throughout training.
As it inherits from the PruningSchedule defined above, it must implement all the Python definitions and can hence be used directly in pruning.
It accepts the following arguments (source: TensorFlow - Creative Commons Attribution 4.0 License, no edits):
| Args |
|---|

Hi, I'm Chris!
I know a thing or two about AI and machine learning. Welcome to MachineCurve.com, where machine learning is explained in gentle terms.
Getting started
Foundation models
Learn how large language models and other foundation models are working and how you can train open source ones yourself.
Keras
Keras is a high-level API for TensorFlow. It is one of the most popular deep learning frameworks.
Machine learning theory
Read about the fundamentals of machine learning, deep learning and artificial intelligence.
Most recent articles
January 2, 2024
What is Retrieval-Augmented Generation?
December 27, 2023
In-Context Learning: what it is and how it works
December 22, 2023
CLIP: how it works, how it's trained and how to use it
Article tags
Most popular articles
February 18, 2020
How to use K-fold Cross Validation with TensorFlow 2 and Keras?
December 28, 2020
Introduction to Transformers in Machine Learning
December 27, 2021
StyleGAN, a step-by-step introduction
July 17, 2019
This Person Does Not Exist - how does it work?
October 26, 2020
Your First Machine Learning Project with TensorFlow 2.0 and Keras
Connect on social media
Connect with me on LinkedIn
To get in touch with me, please connect with me on LinkedIn. Make sure to write me a message saying hi!
Side info
The content on this website is written for educational purposes. In writing the articles, I have attempted to be as correct and precise as possible. Should you find any errors, please let me know by creating an issue or pull request in this GitHub repository.
All text on this website written by me is copyrighted and may not be used without prior permission. Creating citations using content from this website is allowed if a reference is added, including an URL reference to the referenced article.
If you have any questions or remarks, feel free to get in touch.
TensorFlow, the TensorFlow logo and any related marks are trademarks of Google Inc.
PyTorch, the PyTorch logo and any related marks are trademarks of The Linux Foundation.
Montserrat and Source Sans are fonts licensed under the SIL Open Font License version 1.1.
Mathjax is licensed under the Apache License, Version 2.0.