Creating a simple binary SVM classifier with Python and Scikit-learn
May 3, 2020 by Chris
Suppose that you are cleaning your house - and especially the clothes you never wear anymore. For every item, you decide whether you keep it or whether you'll throw it away (or, more preferably, bring it to some kind of second-hand clothing initiative).
What you are effectively doing here is classifying each sample into one of two classes: "keep" and "throw away".
This is called binary classification and it is precisely what we will be looking at in today's blog post. In supervised machine learning, we can create models that do the same - assign one of two classes to a new sample, based on samples from the past that instruct it to do so.
Today, neural networks are very hot - and they can be used for binary classification as well. However, today, we will keep the neural networks out of this post - and we will focus on another Machine Learning technique called Support Vector Machine. It is one of the more traditional techniques, but it is still used today.
Let's take a look at what we will do today. Firstly, we'll dive into classification in more detail. What is it? What is a class? What is a binary classifier? How are classifiers trained? We will answer those questions, so that you can understand what is going on - but don't worry, we'll do so intuitively.
Subsequently, we will focus on the Support Vector Machine class of classifiers. How do they work? How are they trained? We'll cover those questions in today's blog.
Following the theoretical part is a practical one - namely, building a SVM classifier for binary classification This answers the question How to create a binary SVM classifier? We will be using Python for doing so - for many data scientists and machine learning engineers the lingua franca for creating machine learning models. More specifically, we will use Scikit-learn, a Python framework for machine learning, for creating our SVM classifier. It is one of the most widely used frameworks and therefore a perfect candidate for today's post.
Part of the theoretical part is a step-by-step example of how to generate a sample dataset, build the SVM classifier, train it, and visualize the decision boundary that has emerged after training. We'll explain every part, so that you understand with great detail how to build one yourself for a different dataset.
All right. Are you ready? Let's go :)
What is classification in Machine Learning?
Let's revisit that scenario that we discussed above.
You are in your bedroom, because you've decided that you need to clean up your closet. It's time to renew it, which includes getting rid of all the clothing that you no longer wear - or maybe, even have grown out of, in either of two directions :)

Photographer: Kai Pilger / Pexels License
You would follow this process:
- Pick an item from your closet.
- Take a look at it, and at your decision criteria, and make a decision:
- Keep it;
- Discard it;
- Put the item onto the pile of clothing that likely already exists, or at some assigned place for clothing assigned that particular choice if it's the first item you've assigned that decision to.

Translated into conceptual terms, this is what you have been doing:
- Pick a new sample.
- Check the characteristics of the sample against your decision criteria, and assign the class "keep" or the class "discard".
This means that you've been classifying new samples according to a preexisting set of decision criteria.
From the human world to the machine world
In fact, it is something we humans do every day: we make a choice to take ("yes") or don't take ("no") some fastfood out on our way home, to go for a run ("yes/no" again), whether a date is good or not ("friendzone/romance zone" ;-) ), and so on!
In supervised machine learning, scholars and engineers have attempted to mimic this decision-making ability by allowing us to create what is known as a classifier. Using data from the past, it attempts to learn a decision boundary between the samples from the different classes - i.e., the decision criteria we just mentioned for sorting the clothes.
The end result: a machine learning model which can be used to decide automatically what class should be assigned once it is fed a new sample. But, of course, only if it is trained well.
Binary and multiclass classification
In the scenario above, we had two classes: this is called a binary classification scenario.
However, sometimes, there are more classes - for example, in the dating scenario above, you might wish to add the class "never want to see / speak to again", which I'd consider a good recommendation for some people :)
This is called multiclass classification.
In any transition from binary into multiclass classification, you should take a close look at machine learning models and find out whether they support it out of the box.
Very often, they do, but they may not do so natively - requiring a set of tricks for multiclass classification to work.
For example, neural networks support multiclass classification out of the box. It's simply a matter of adding the Softmax activation function to generate a multiclass probability distribution that will give you the likelihood of your sample belonging to one class.
Support Vector Machines, which we are using in today's blog post, do not support multiclass classification natively, as we shall see next. However, they do support it with a few tricks, but those will be covered in another blog post. Should you wish to find out more, you could look here.
[affiliatebox]
What is a Support Vector Machine?
Let's now take a look at what a Support Vector Machine is. Here is a great visual explanation:
https://www.youtube.com/watch?v=N-sPSXDtcQw
Creating a binary SVM classifier, step-by-step
Now that we know what classification is and how SVMs can be used for classification, it's time to move to the more practical part of today's blog post.
We're going to build a SVM classifier step-by-step with Python and Scikit-learn. This part consists of a few steps:
- Generating a dataset: if we want to classify, we need something to classify. For this reason, we will generate a linearly separable dataset having 2 features with Scikit's
make_blobs. - Building the SVM classifier: we're going to explore the concept of a kernel, followed by constructing the SVM classifier with Scikit-learn.
- Using the SVM to predict new data samples: once the SVM is trained, it should be able to correctly predict new samples. We're going to demonstrate how you can evaluate your binary SVM classifier.
- Finding the support vectors of your trained SVM: as we know, support vectors determine the decision boundary. But given your training data, which vectors were used as a support vector? We can find out - and we will show you.
- Visualizing the decision boundary: by means of a cool extension called Mlxtend, we can visualize the decision boundary of our model. We're going to show you how to do this with your binary SVM classifier.
Make sure that you have installed all the Python dependencies before you start coding. These dependencies are Scikit-learn (or sklearn in PIP terms), Numpy, and Matplotlib.
Let's go and generate a dataset :) Open up a code editor, create a file (such as binary-svm.py), and code away 👩💻

A plot of today's dataset.
Generating a dataset
As with any Python script, we need to define our imports on top:
# Imports
from sklearn.datasets import make_blobs
from sklearn.model_selection import train_test_split
import numpy as np
import matplotlib.pyplot as plt
We're going to use four imports for generating our dataset:
- Scikit-learn's
make_blobsfunction, which allows us to generate the two clusters/blobs of data displayed above. - Scikit-learn's
train_test_splitfunction, which allows us to split the generated dataset into a part for training and a part for testing easily. - Numpy, for numbers processing.
- Matplotlib, for generating the plot from above.
Configuration
Once we set the imports, we're going to define a number of configuration options:
# Configuration options
blobs_random_seed = 42
centers = [(0,0), (5,5)]
cluster_std = 1
frac_test_split = 0.33
num_features_for_samples = 2
num_samples_total = 1000
- The random seed for our blobs ensures that we initialize the pseudorandom numbers generator with the same start initialization. We need to do this to ensure that varying initializations don't interfere with our random numbers generation. This can be any number, but the number 42 is cool for obvious reasons.
- The centers represent the (X, y) positions of the centers of the blobs we're generating.
- The cluster standard deviation tells us something about how scattered the centers are across the two-dimensional mathematical space. It can be set to any number, but the lower, the more condensed the clusters are.
- The fraction of the test split tells us what percentage of our data is used for testing purposes. In our case, that's 33%, or one third of our dataset.
- The number of features for samples tells us the number of classes we wish to generate data for. In our case, that's 2 classes - we're building a binary classifier.
- The number of samples in total tells us the number of samples that are generated in total. For educational purposes, we're keeping the number quite low today, but it can be set to larger numbers if you desire.
Generation
Now that we have the imports and the configuration, we can generate the data:
# Generate data
inputs, targets = make_blobs(n_samples = num_samples_total, centers = centers, n_features = num_features_for_samples, cluster_std = cluster_std)
X_train, X_test, y_train, y_test = train_test_split(inputs, targets, test_size=frac_test_split, random_state=blobs_random_seed)
For this, we're calling make_blobs with the configuration options from before. We store its output in the inputs and targets variables, which store the features (inputs) and targets (class outcomes), respectively.
Then, we split the inputs and targets into training and testing data.
[affiliatebox]
Saving and loading (optional)
Should you wish to re-use your generated data many times, you don't want the plot to change every time you run the script. In that case, you might use Numpy to save the data temporarily, and load it before continuing:
# Save and load temporarily
np.save('./data.npy', (X_train, X_test, y_train, y_test))
X_train, X_test, y_train, y_test = np.load('./data.npy', allow_pickle=True)
Now, if you run the code once, then uncomment np.save (and possibly the generation part of the code as well), you'll always have your code run with the same dataset. A simple trick.
Visualizing
Finally, we can generate that visualization from above:
# Generate scatter plot for training data
plt.scatter(X_train[:,0], X_train[:,1])
plt.title('Linearly separable data')
plt.xlabel('X1')
plt.ylabel('X2')
plt.show()
Et voila - if we run it, we get the plot (although in yours, the samples are at a different position, but relatively close to where mine are):
Full code so far
Should you wish to obtain the full code so far, you can copy from here:
# Imports
from sklearn.datasets import make_blobs
from sklearn.model_selection import train_test_split
import numpy as np
import matplotlib.pyplot as plt
# Configuration options
blobs_random_seed = 42
centers = [(0,0), (5,5)]
cluster_std = 1
frac_test_split = 0.33
num_features_for_samples = 2
num_samples_total = 1000
# Generate data
inputs, targets = make_blobs(n_samples = num_samples_total, centers = centers, n_features = num_features_for_samples, cluster_std = cluster_std)
X_train, X_test, y_train, y_test = train_test_split(inputs, targets, test_size=frac_test_split, random_state=blobs_random_seed)
# Save and load temporarily
np.save('./data.npy', (X_train, X_test, y_train, y_test))
X_train, X_test, y_train, y_test = np.load('./data.npy', allow_pickle=True)
# Generate scatter plot for training data
plt.scatter(X_train[:,0], X_train[:,1])
plt.title('Linearly separable data')
plt.xlabel('X1')
plt.ylabel('X2')
plt.show()
Building the SVM classifier
All right - now we have the data, we can build our SVM classifier :)
We will be doing so with SVC from Scikit-learn, which is their representation of a Support Vector Classifier - or SVC. This primarily involves two main steps:
- Choosing a kernel function - in order to make nonlinear data linearly separable, if necessary. Don't worry, we'll explain this next.
- Building our classifier - i.e., writing our code.
Let's take a look.
Choosing a kernel function
As we've seen above, SVMs will attempt to find a linear separation between the samples in your dataset.
In cases like this...
...this won't be too problematic :)
But if your data looks differently...
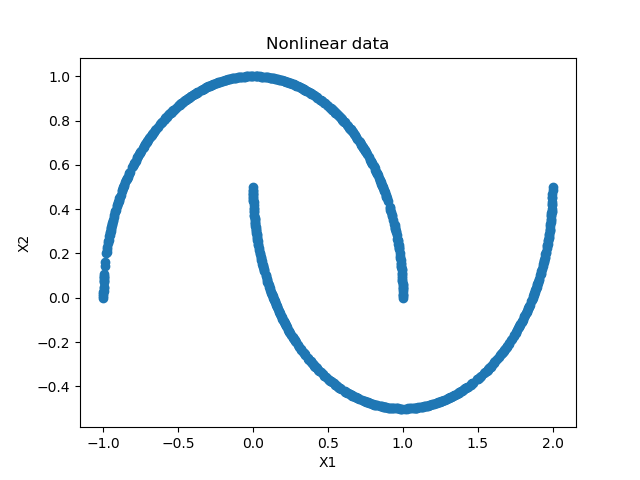
Whoops 👀
We could use a kernel for this. Let's take a look - if we plot our 'moons' (the data looks similar to 2 moons) in 3D, we would get this:


Indeed, we still cannot separate them linearly - but the extra dimension shows you why a kernel is useful. In SVMs, kernel functions map the function into another space, where the data becomes linearly separable.
And through a smart mathematical formulation, this will be possible at no substantial increase in computational cost. It's truly one of the most beautiful things of SVMs, if you ask me :)
Any mathematical function can be used as a kernel function. Scikit-learn also supports this by means of a 'callable', which means that you can provide a kernel function if you see fit. However, out of the box, Scikit-learn supports these:
- Linear: which simply maps the same onto a different space.
- Polynomial kernel: it "represents vector similarity over polynomials of the original variables".
- RBF, or Radial Basis Function: value depends on the distance from some point.
- The Sigmoid function.
- A precomputed function.
Here's an example of what would happen if we apply some customkernel to our moons:


As you can see, they are mapped onto the 3rd dimension differently than in our original setting. Still, they are not linearly separable - but you get the point.
Fortunately, in our case, we have linearly separable data - check the plot again - so we choose linear as our kernel:
Building the classifier
We can now extend our code - by adding this to our imports first:
from sklearn import svm
Subsequently, we can initialize our SVM classifier:
# Initialize SVM classifier
clf = svm.SVC(kernel='linear')
After which we can fit our training data to our classifier, which means that the training process starts:
clf = clf.fit(X_train, y_train)
Full model code so far
All right, so far, we have generated our dataset and initialized our SVM classifier, with which we are also fitting data already. Should you wish to obtain what we have so far in full, here you go:
# Imports
from sklearn.datasets import make_blobs
from sklearn.model_selection import train_test_split
import numpy as np
import matplotlib.pyplot as plt
from sklearn import svm
# Configuration options
blobs_random_seed = 42
centers = [(0,0), (5,5)]
cluster_std = 1
frac_test_split = 0.33
num_features_for_samples = 2
num_samples_total = 1000
# Generate data
inputs, targets = make_blobs(n_samples = num_samples_total, centers = centers, n_features = num_features_for_samples, cluster_std = cluster_std)
X_train, X_test, y_train, y_test = train_test_split(inputs, targets, test_size=frac_test_split, random_state=blobs_random_seed)
# Save and load temporarily
np.save('./data.npy', (X_train, X_test, y_train, y_test))
X_train, X_test, y_train, y_test = np.load('./data.npy', allow_pickle=True)
# Generate scatter plot for training data
plt.scatter(X_train[:,0], X_train[:,1])
plt.title('Linearly separable data')
plt.xlabel('X1')
plt.ylabel('X2')
plt.show()
# Initialize SVM classifier
clf = svm.SVC(kernel='linear')
# Fit data
clf = clf.fit(X_train, y_train)
Using the SVM to predict new data samples
Generating new predictions is simple. For example, for generating predictions of our test set, we simply add:
predictions = clf.predict(X_test)
After training, it's wise to evaluate a model with the test set to see how well it performs. Today, we'll do so by means of a confusion matrix, which shows you the correct and wrong predictions in terms of true positives, true negatives, false positives and false negatives
Let's show the confusion matrix.
[affiliatebox]
Confusion matrix
If we add to our imports...
from sklearn.metrics import plot_confusion_matrix
...and subsequently after our fit call:
# Predict the test set
predictions = clf.predict(X_test)
# Generate confusion matrix
matrix = plot_confusion_matrix(clf, X_test, y_test,
cmap=plt.cm.Blues,
normalize='true')
plt.title('Confusion matrix for our classifier')
plt.show(matrix)
plt.show()
We can generate what is known as a confusion matrix:
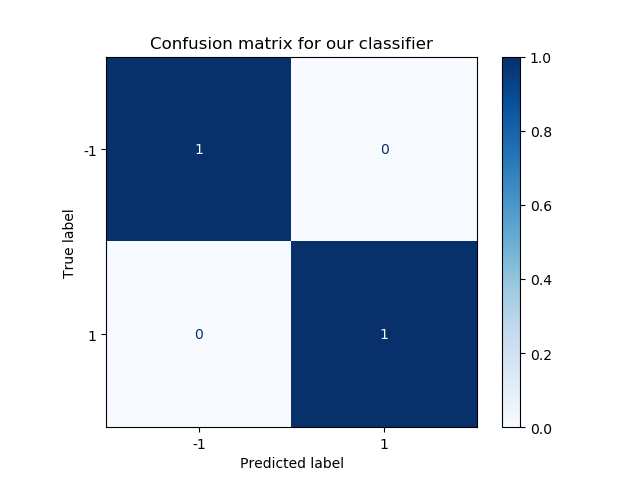
It shows the true positives, true negatives, false positives and false negatives for our model given the evaluation dataset. In our case, we have 100% true positives and 100% true negatives, and no wrong predictions.
That's not strange given the linear separability of our dataset - and very unlikely to happen in practice - but the confusion matrix is then still a very useful tool :)
Model code so far
Should you wish to obtain what we have so far - here you go:
# Imports
from sklearn.datasets import make_blobs
from sklearn.model_selection import train_test_split
import numpy as np
import matplotlib.pyplot as plt
from sklearn import svm
from sklearn.metrics import plot_confusion_matrix
# Configuration options
blobs_random_seed = 42
centers = [(0,0), (5,5)]
cluster_std = 1
frac_test_split = 0.33
num_features_for_samples = 2
num_samples_total = 1000
# Generate data
inputs, targets = make_blobs(n_samples = num_samples_total, centers = centers, n_features = num_features_for_samples, cluster_std = cluster_std)
X_train, X_test, y_train, y_test = train_test_split(inputs, targets, test_size=frac_test_split, random_state=blobs_random_seed)
# Save and load temporarily
# np.save('./data.npy', (X_train, X_test, y_train, y_test))
X_train, X_test, y_train, y_test = np.load('./data.npy', allow_pickle=True)
# Generate scatter plot for training data
plt.scatter(X_train[:,0], X_train[:,1])
plt.title('Linearly separable data')
plt.xlabel('X1')
plt.ylabel('X2')
plt.show()
# Initialize SVM classifier
clf = svm.SVC(kernel='linear')
# Fit data
clf = clf.fit(X_train, y_train)
# Predict the test set
predictions = clf.predict(X_test)
# Generate confusion matrix
matrix = plot_confusion_matrix(clf, X_test, y_test,
cmap=plt.cm.Blues,
normalize='true')
plt.title('Confusion matrix for our classifier')
plt.show(matrix)
plt.show()
Finding the support vectors of your trained SVM
Now, on to the next topic: finding the support vectors of your trained model.
As we recalled before, the decision boundary is determined by so-called "support vectors" - vectors from each class that are the figurative last man standing between "their own" and "the others", i.e. the other cluster of data.
We can visualize those support vectors with Scikit-learn and Matplotlib:
# Get support vectors
support_vectors = clf.support_vectors_
# Visualize support vectors
plt.scatter(X_train[:,0], X_train[:,1])
plt.scatter(support_vectors[:,0], support_vectors[:,1], color='red')
plt.title('Linearly separable data with support vectors')
plt.xlabel('X1')
plt.ylabel('X2')
plt.show()
This produces the following plot:

Indeed, as we intuitively grasped, the linear separability of our dataset ensures that only limited support vectors are necessary to make the separation with highest margin - two, in our case.
Full code so far
Here's our code so far:
# Imports
from sklearn.datasets import make_blobs
from sklearn.model_selection import train_test_split
import numpy as np
import matplotlib.pyplot as plt
from sklearn import svm
from sklearn.metrics import plot_confusion_matrix
# Configuration options
blobs_random_seed = 42
centers = [(0,0), (5,5)]
cluster_std = 1
frac_test_split = 0.33
num_features_for_samples = 2
num_samples_total = 1000
# Generate data
inputs, targets = make_blobs(n_samples = num_samples_total, centers = centers, n_features = num_features_for_samples, cluster_std = cluster_std)
X_train, X_test, y_train, y_test = train_test_split(inputs, targets, test_size=frac_test_split, random_state=blobs_random_seed)
# Save and load temporarily
# np.save('./data.npy', (X_train, X_test, y_train, y_test))
X_train, X_test, y_train, y_test = np.load('./data.npy', allow_pickle=True)
# Generate scatter plot for training data
plt.scatter(X_train[:,0], X_train[:,1])
plt.title('Linearly separable data')
plt.xlabel('X1')
plt.ylabel('X2')
plt.show()
# Initialize SVM classifier
clf = svm.SVC(kernel='linear')
# Fit data
clf = clf.fit(X_train, y_train)
# Predict the test set
predictions = clf.predict(X_test)
# Generate confusion matrix
matrix = plot_confusion_matrix(clf, X_test, y_test,
cmap=plt.cm.Blues,
normalize='true')
plt.title('Confusion matrix for our classifier')
plt.show(matrix)
plt.show()
# Get support vectors
support_vectors = clf.support_vectors_
# Visualize support vectors
plt.scatter(X_train[:,0], X_train[:,1])
plt.scatter(support_vectors[:,0], support_vectors[:,1], color='red')
plt.title('Linearly separable data with support vectors')
plt.xlabel('X1')
plt.ylabel('X2')
plt.show()
Visualizing the decision boundary
Sometimes, we don't want to visualize the support vectors, but the exact decision boundary for our SVM classifier.
We can do so with a fantastic package called Mlxtend, created by dr. Sebastian Raschka, who faced this problem for his classifiers.
It can be installed in a very simple way: pip install mlxtend. Then, if we add it to the imports:
from mlxtend.plotting import plot_decision_regions
...and subsequently add two lines of code only:
# Plot decision boundary
plot_decision_regions(X_test, y_test, clf=clf, legend=2)
plt.show()
We get a very nice plot :)

Nice :D
Full and final model code
Now, if you should wish to obtain everything at once - here you go :D
# Imports
from sklearn.datasets import make_blobs
from sklearn.model_selection import train_test_split
import numpy as np
import matplotlib.pyplot as plt
from sklearn import svm
from sklearn.metrics import plot_confusion_matrix
from mlxtend.plotting import plot_decision_regions
# Configuration options
blobs_random_seed = 42
centers = [(0,0), (5,5)]
cluster_std = 1
frac_test_split = 0.33
num_features_for_samples = 2
num_samples_total = 1000
# Generate data
inputs, targets = make_blobs(n_samples = num_samples_total, centers = centers, n_features = num_features_for_samples, cluster_std = cluster_std)
X_train, X_test, y_train, y_test = train_test_split(inputs, targets, test_size=frac_test_split, random_state=blobs_random_seed)
# Save and load temporarily
# np.save('./data.npy', (X_train, X_test, y_train, y_test))
X_train, X_test, y_train, y_test = np.load('./data.npy', allow_pickle=True)
# Generate scatter plot for training data
plt.scatter(X_train[:,0], X_train[:,1])
plt.title('Linearly separable data')
plt.xlabel('X1')
plt.ylabel('X2')
plt.show()
# Initialize SVM classifier
clf = svm.SVC(kernel='linear')
# Fit data
clf = clf.fit(X_train, y_train)
# Predict the test set
predictions = clf.predict(X_test)
# Generate confusion matrix
matrix = plot_confusion_matrix(clf, X_test, y_test,
cmap=plt.cm.Blues,
normalize='true')
plt.title('Confusion matrix for our classifier')
plt.show(matrix)
plt.show()
# Get support vectors
support_vectors = clf.support_vectors_
# Visualize support vectors
plt.scatter(X_train[:,0], X_train[:,1])
plt.scatter(support_vectors[:,0], support_vectors[:,1], color='red')
plt.title('Linearly separable data with support vectors')
plt.xlabel('X1')
plt.ylabel('X2')
plt.show()
# Plot decision boundary
plot_decision_regions(X_test, y_test, clf=clf, legend=2)
plt.show()
[affiliatebox]
Summary
In today's blog post, we created a binary Support Vector Machine classifier with Python and Scikit-learn. We first looked at classification in general - what is it? How does it work? This was followed by a discussion on Support Vector Machines, and how they construct a decision boundary when training a classifier.
All the theory was followed by a practical example that was explained step-by-step. Using Python and Scikit-learn, we generated a dataset that is linearly separable and consists of two classes - so, in short, a simple and binary dataset. We then created a SVM with a linear kernel for training a classifier, but not before explaining the function of kernel functions, as to not to skip an important part of SVMs. This was followed by explaining some post-processing as well: generating a confusion matrix, visualizing the support vectors and visualizing the decision boundary of the model.
I hope you've learnt something from today's blog post! :) If you did, I'd really appreciate your comment in the comments section below 💬 Please leave a comment as well if you have any questions, remarks or other comments. Thank you for reading MachineCurve today and happy engineering! 😎
[scikitbox]
References
Scikit-learn. (n.d.). scikit-learn: machine learning in Python — scikit-learn 0.16.1 documentation. Retrieved May 3, 2020, from https://scikit-learn.org/stable/index.html
Scikit-learn. (n.d.). 1.4. Support vector machines — scikit-learn 0.22.2 documentation. scikit-learn: machine learning in Python — scikit-learn 0.16.1 documentation. Retrieved May 3, 2020, from https://scikit-learn.org/stable/modules/svm.html#classification
Scikit-learn. (n.d.). Sklearn.svm.SVC — scikit-learn 0.22.2 documentation. scikit-learn: machine learning in Python — scikit-learn 0.16.1 documentation. Retrieved May 3, 2020, from https://scikit-learn.org/stable/modules/generated/sklearn.svm.SVC.html#sklearn.svm.SVC
Wikipedia. (2005, July 26). Radial basis function. Wikipedia, the free encyclopedia. Retrieved May 3, 2020, from https://en.wikipedia.org/wiki/Radial_basis_function
Wikipedia. (2012, November 12). Polynomial kernel. Wikipedia, the free encyclopedia. Retrieved May 3, 2020, from https://en.wikipedia.org/wiki/Polynomial_kernel
Raschka, S. (n.d.). Home - mlxtend. Site not found · GitHub Pages. https://rasbt.github.io/mlxtend/

Hi, I'm Chris!
I know a thing or two about AI and machine learning. Welcome to MachineCurve.com, where machine learning is explained in gentle terms.
Getting started
Foundation models
Learn how large language models and other foundation models are working and how you can train open source ones yourself.
Keras
Keras is a high-level API for TensorFlow. It is one of the most popular deep learning frameworks.
Machine learning theory
Read about the fundamentals of machine learning, deep learning and artificial intelligence.
Most recent articles
January 2, 2024
What is Retrieval-Augmented Generation?
December 27, 2023
In-Context Learning: what it is and how it works
December 22, 2023
CLIP: how it works, how it's trained and how to use it
Article tags
Most popular articles
February 18, 2020
How to use K-fold Cross Validation with TensorFlow 2 and Keras?
December 28, 2020
Introduction to Transformers in Machine Learning
December 27, 2021
StyleGAN, a step-by-step introduction
July 17, 2019
This Person Does Not Exist - how does it work?
October 26, 2020
Your First Machine Learning Project with TensorFlow 2.0 and Keras
Connect on social media
Connect with me on LinkedIn
To get in touch with me, please connect with me on LinkedIn. Make sure to write me a message saying hi!
Side info
The content on this website is written for educational purposes. In writing the articles, I have attempted to be as correct and precise as possible. Should you find any errors, please let me know by creating an issue or pull request in this GitHub repository.
All text on this website written by me is copyrighted and may not be used without prior permission. Creating citations using content from this website is allowed if a reference is added, including an URL reference to the referenced article.
If you have any questions or remarks, feel free to get in touch.
TensorFlow, the TensorFlow logo and any related marks are trademarks of Google Inc.
PyTorch, the PyTorch logo and any related marks are trademarks of The Linux Foundation.
Montserrat and Source Sans are fonts licensed under the SIL Open Font License version 1.1.
Mathjax is licensed under the Apache License, Version 2.0.