Say you've got a dataset where there exist relationships between individual samples, and your goal is to identify groups of related samples within the dataset. Clustering, which is part of the class of unsupervised machine learning algorithms, is then the way to go. But what clustering algorithm to apply when you do not really know the number of clusters?
Enter Affinity Propagation, a gossip-style algorithm which derives the number of clusters by mimicing social group formation by passing messages about the popularity of individual samples as to whether they're part of a certain group, or even if they are the leader of one. This algorithm, which can estimate the number of clusters/groups in your dataset itself, is the topic of today's blog post.
Firstly, we'll take a theoretical look at Affinity Propagation. What is it - and how does the group formation analogy work? How does it work in more detail, i.e. mathematically? And what kind of messages are sent, and how are those popularity metrics determined? How does the algorithm converge? We'll look at them first.
Next, we provide an example implementation of Affinity Propagation using Scikit-learn and Python. We explain our model code step by step, so that you can understand what is happening piece by piece. For those who already have some experience and wish to play right away, the full model code is also available. Hence, today's blog post is both theoretical and practical - my favorite type of blog!
In this tutorial, you will learn...
- How to perform Affinity Propagation clustering with Scikit-learn.
- What Affinity Propagation is.
- How Affinity propagation works.
Example code: How to perform Affinity Propagation with Scikit-learn?
With this quick example you will be able to start using Affinity Propagation with Scikit-learn immediately. Copy and paste the code into your project and you are ready to go. If you want to understand how Affinity Propagation works in more detail, or learn how to write the code step-by-step, make sure to read the rest of this tutorial.
from sklearn.datasets import make_blobs
from sklearn.cluster import AffinityPropagation
# Generate data
X, targets = make_blobs(n_samples = 50, centers = [(20,20), (4,4)], n_features = 2, center_box=(0, 1), cluster_std = 1)
# Fit Affinity Propagation with Scikit
afprop = AffinityPropagation(max_iter=250)
afprop.fit(X)
cluster_centers_indices = afprop.cluster_centers_indices_
n_clusters_ = len(cluster_centers_indices)
# Predict the cluster for all the samples
P = afprop.predict(X)
What is Affinity Propagation?
Do you remember high school, where groups of people formed - and you could only become a member of a particular group if the group's leaders thought you were cool?
Although the analogy might be a bit far-fetched, I think this is how Affinity Propagation for clustering can be explained in plain English. For a set of data points, a "group formation" process begins, where each sample competes with other ones in order to gain group membership. The ones with most group capital, the group leaders are called exemplars (Scikit-learn, n.d.).
The interesting thing about this machine learning techniques is that you don't have to configure the number of clusters in advance, unlike K-means clustering (Scikit-learn, n.d.). The main drawback is the complexity: it's not one of the cheapest machine learning algorithms in terms of the computational resources that are required (Scikit-learn, n.d.). Hence, it's a suitable technique for "small to medium sized datasets" only (Scikit-learn, n.d.).
A little bit more detail
Now that we understand Affinity Propagation at a high level, it's time to take a more detailed look. We'll look at a couple of things:
- How the algorithm works, at a high level;
- What kind of messages are propagated;
- How the scores in those messages are computed.
- How the message scores are updated after each iteration, and thus how the true clusters are formed.
First of all, as with any clustering algorithm, Affinity Propagation is iterative. This means that it will complete a number of iterations until completion. Contrary to K-means clustering, where convergence is determined with some threshold value, with Affinity Propagation you configure a number of iterations to complete. After then, the algorithm assumes convergence and will return the resulting clusters (Scikit-learn, n.d.).
Two types of messages are propagated
During each iteration, each sample broadcasts two types of messages to the other samples (Scikit-learn, n.d.). The first is called the responsibility \(r(i,k)\) - which is the "evidence that sample \(k\) should be the exemplar for sample \(i\)" (Scikit-learn, n.d.). I always remember it as follows: the greater the expected group leadership of \(k\), the greater the responsibility for the group. That's how you know that the responsibility from the point of \(i\) always tells you something about the importance of \(k\) for the group.
The other type of message that is sent is the availability. This is the opposite of the responsibility: how certain \(i\) is that it should choose \(k\) as the exemplar, i.e. how available it is to join a particular group (Scikit-learn, n.d.). In the high school case, say that you want to join a semi-cool group (some availability), while you're more willing to join the really cool group, your availability is much higher for the really cool one. The responsibility tells you something about whose acceptance you need to join the group, i.e. the most likely group leader i.e. exemplar.
Computing the scores for responsibility and availability
Let's now take an even closer look at the concepts of responsibility and availability. Now that we know what they represent at a high level, it's time that we look at them in detail - which means mathematically.
Responsibility
Here's the formula for responsibility (Scikit-learn, n.d.):
\(r(i, k) \leftarrow s(i, k) - max [ a(i, k') + s(i, k') \forall k' \neq k ]\)
Let's now decompose this formula into plain English. We start at the left. Here, \(r(i,k)\) is once again the responsibility that sample \(k\) is the exemplar for sample \(i\). But what determines it? Two components: \(s(i, k)\) and \(max [ a(i, k') + s(i, k') \forall k' \neq k ]\).
The first is the similarity between samples \(i\) and \(k\). If they are highly similar, the odds are very big that \(k\) should be \(i\)'s exemplar. However, this is not the full story, as we cannot look at similarity only - as the other samples will also try to convince that they are the more suitable exemplars for \(i\). Hence, the similarity is relative, and that's why we need to subtract that big \(max\) value. It looks complex, but it simply boils down to "the maximum availability and similarity of all the other samples \(k'\), where \(k'\) is never \(k\)". We simply subtract the similarity and the willingness of \(k\)'s "biggest competitor" in order to show its relative strength as an exemplar.
Availability
Looks complex, but is actually relatively easy. And so is the formula for the availability (Scikit-learn, n.d.):
\(a(i, k) \leftarrow min [0, r(k, k) + \sum_{i'~s.t.~i' \notin {i, k}}{r(i', k)}]\)
As we can see, the availability is determined as the minimum value between 0 and the responsibility of \(k\) to \(k\) (i.e. how important it considers itself to be an exemplar or a group leader) and the sum of the responsibilities for all other samples \(i'\) to \(k\), where \(i'\) is neither \(i\) or \(k\). Thus, in terms of group formation, a sample will become more available to a potential exemplar if itself thinks it's highly important and so do the other samples around.
Updating the scores: how clusters are formed
Now that we know about the formulae for responsibility and availability, let's take a look at how scores are updated after every iteration (Scikit-learn, n.d.):
\(r_{t+1}(i, k) = \lambda\cdot r_{t}(i, k) + (1-\lambda)\cdot r_{t+1}(i, k)\)
\(a_{t+1}(i, k) = \lambda\cdot a_{t}(i, k) + (1-\lambda)\cdot a_{t+1}(i, k)\)
Very simple: every update, we take \(\lambda\) of the old value and merge it with \((1-\lambda)\) of the new value. This lambda, which is also called "damping value", is a smoothing factor to ensure a smooth transition; it avoids large oscillations during the optimization process.
Altogether, Affinity Propagation is therefore an algorithm which:
- Estimates the number of clusters itself.
- Is useful for small to medium sized datasets given the computational expensiveness.
- Works by "gossiping" around as if it is attempting to form high school groups of students.
- Updates itself through small and smooth updates to the "attractiveness" of individual samples across time, i.e. after every iteration.
- Where the attractiveness is determined for a sample, answering the question "can this be the leader of the group I want to belong to?" and for the sample itself ("what's the evidence that I'm a group leader?").
Let's now take a look how to implement it with Python and Scikit-learn! :)
Implementing Affinity Propagation with Python and Scikit-learn
Here they are again, the clusters that we also saw in our blog about K-means clustering, although we have fewer samples today:
Remember how we generated them? Open up a Python file and name it `affinity.py`, add the imports (which are Scikit-learn, Numpy and Matplotlib)...
import matplotlib.pyplot as plt
import numpy as np
from sklearn.datasets import make_blobs
from sklearn.cluster import AffinityPropagation
We then add a few configuration options: the number of samples in total we generate, the centers of the clusters, as well as the number of classes that we will generate samples for. Those are all to be used in make_blobs, which generates the clusters and assigns them to \(X\) and \(targets\), respectively.
We save them with Numpy and subsequently load them and assign them to \(X\) again. Those two lines of code aren't necessary for your model to run, but if you want to compare across settings, you likely don't want to generate samples at random every time. By saving them once, and subsequently commenting out save and make_blobs, you'll load them from file again and again :)
# Configuration options
num_samples_total = 50
cluster_centers = [(20,20), (4,4)]
num_classes = len(cluster_centers)
# Generate data
X, targets = make_blobs(n_samples = num_samples_total, centers = cluster_centers, n_features = num_classes, center_box=(0, 1), cluster_std = 1)
np.save('./clusters.npy', X)
X = np.load('./clusters.npy')
We then fit the data to the Affinity Propagation algorithm, after we loaded it, which just takes two lines of code. In another two lines, we derive characteristics such as the exemplars and by consequence the number of clusters:
# Fit AFfinity Propagation with Scikit
afprop = AffinityPropagation(max_iter=250)
afprop.fit(X)
cluster_centers_indices = afprop.cluster_centers_indices_
n_clusters_ = len(cluster_centers_indices)
Finally, by using the algorithm we fit, we predict for all our samples to which cluster they belong:
# Predict the cluster for all the samples
P = afprop.predict(X)
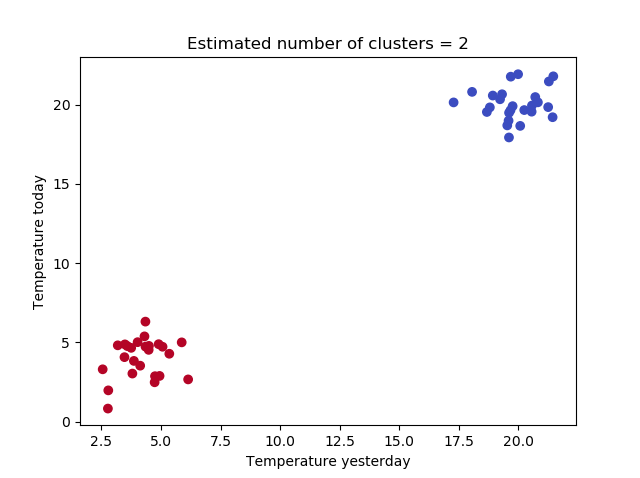
And finally visualize the outcome:
# Generate scatter plot for training data
colors = list(map(lambda x: '#3b4cc0' if x == 1 else '#b40426', P))
plt.scatter(X[:,0], X[:,1], c=colors, marker="o", picker=True)
plt.title(f'Estimated number of clusters = {n_clusters_}')
plt.xlabel('Temperature yesterday')
plt.ylabel('Temperature today')
plt.show()
Here it is! 😊👇
Full model code
Should you wish to obtain the full model code at once, so that you can start working with it straight away - here you go! 😎
import matplotlib.pyplot as plt
import numpy as np
from sklearn.datasets import make_blobs
from sklearn.cluster import AffinityPropagation
# Configuration options
num_samples_total = 50
cluster_centers = [(20,20), (4,4)]
num_classes = len(cluster_centers)
# Generate data
X, targets = make_blobs(n_samples = num_samples_total, centers = cluster_centers, n_features = num_classes, center_box=(0, 1), cluster_std = 1)
np.save('./clusters.npy', X)
X = np.load('./clusters.npy')
# Fit AFfinity Propagation with Scikit
afprop = AffinityPropagation(max_iter=250)
afprop.fit(X)
cluster_centers_indices = afprop.cluster_centers_indices_
n_clusters_ = len(cluster_centers_indices)
# Predict the cluster for all the samples
P = afprop.predict(X)
# Generate scatter plot for training data
colors = list(map(lambda x: '#3b4cc0' if x == 1 else '#b40426', P))
plt.scatter(X[:,0], X[:,1], c=colors, marker="o", picker=True)
plt.title(f'Estimated number of clusters = {n_clusters_}')
plt.xlabel('Temperature yesterday')
plt.ylabel('Temperature today')
plt.show()
Summary
In today's blog post, we looked at the Affinity Propagation algorithm. This clustering algorithm allows machine learning engineers to cluster their datasets by means of "messaging". Resembling how groups are formed at high school, where the group leaders decide who gets in and who has to choose another, the pull game is played by the algorithm as well.
By looking at the messages that are propagated, the responsibility and availability metrics that are sent with these messages, and how it converges iteratively, we first understood the theoretical part of the Affinity Propagation algorithm. This was followed by a practical example using Python and Scikit-learn, where we explained implementing Affinity Propagation step by step. For those interested, the model as a whole is also available above.
I hope you've learnt something today! I certainly did - I never worked with this algorithm before. If you have any questions, please feel free to leave a message in the comments section below - I'd appreciate it 💬👇. Thank you for reading MachineCurve today and happy engineering! 😎
References
Scikit-learn. (n.d.). 2.3. Clustering — scikit-learn 0.22.2 documentation. scikit-learn: machine learning in Python — scikit-learn 0.16.1 documentation. Retrieved April 18, 2020, from https://scikit-learn.org/stable/modules/clustering.html#affinity-propagation

Hi, I'm Chris!
I know a thing or two about AI and machine learning. Welcome to MachineCurve.com, where machine learning is explained in gentle terms.
Getting started
Foundation models
Learn how large language models and other foundation models are working and how you can train open source ones yourself.
Keras
Keras is a high-level API for TensorFlow. It is one of the most popular deep learning frameworks.
Machine learning theory
Read about the fundamentals of machine learning, deep learning and artificial intelligence.
Most recent articles
January 2, 2024
What is Retrieval-Augmented Generation?
December 27, 2023
In-Context Learning: what it is and how it works
December 22, 2023
CLIP: how it works, how it's trained and how to use it
Article tags
Most popular articles
February 18, 2020
How to use K-fold Cross Validation with TensorFlow 2 and Keras?
December 28, 2020
Introduction to Transformers in Machine Learning
December 27, 2021
StyleGAN, a step-by-step introduction
July 17, 2019
This Person Does Not Exist - how does it work?
October 26, 2020
Your First Machine Learning Project with TensorFlow 2.0 and Keras
Connect on social media
Connect with me on LinkedIn
To get in touch with me, please connect with me on LinkedIn. Make sure to write me a message saying hi!
Side info
The content on this website is written for educational purposes. In writing the articles, I have attempted to be as correct and precise as possible. Should you find any errors, please let me know by creating an issue or pull request in this GitHub repository.
All text on this website written by me is copyrighted and may not be used without prior permission. Creating citations using content from this website is allowed if a reference is added, including an URL reference to the referenced article.
If you have any questions or remarks, feel free to get in touch.
TensorFlow, the TensorFlow logo and any related marks are trademarks of Google Inc.
PyTorch, the PyTorch logo and any related marks are trademarks of The Linux Foundation.
Montserrat and Source Sans are fonts licensed under the SIL Open Font License version 1.1.
Mathjax is licensed under the Apache License, Version 2.0.