The neurons of neural networks perform operations that are linear: they multiple an input vector with a weights vector and add a bias - operations that are linear.
By consequence, they are not capable of learning patterns in nonlinear data, except for the fact that activation functions can be added. These functions, to which the output of a neuron is fed, map the linear data into a nonlinear range, and hence introduce the nonlinearity that the system as a whole needs for learning nonlinear data. Hence, it's not strange that activation functions are also called "nonlinearities", even though - strictly speaking - \(f(x) = x\) can also be an activation function.
In this blog post, we provide an overview of activation functions covered on MachineCurve. It allows you to quickly identify common activation functions and navigate to those which are interesting to you, in order to learn more about them in more detail. We cover traditional activation functions like Sigmoid, Tanh and ReLU, but also the newer ones like Swish (and related activation functions) as well as Leaky and Parametric ReLU (and related ones).
Are you ready? Let's go! 😎
Update June 2020: added possible instability and computational intensity of Swish to provide a better balance between advantages and disadvantages.
Sigmoid
One of the traditional activation functions is the Sigmoid activation function. I consider it one of the most widely known activation functions known and perhaps used today, except for ReLU. It converts a domain of \(x \in [ -\infty , \infty]\) into the range \(y \in [ 0, 1 ]\), with the greatest change present in the \(x \in [-4, +4]\) interval.
Using Sigmoid possibly introduces two large bottlenecks into your machine learning project. Firstly, the outputs are not symmetrical around the origin; that is, for \(x = 0\), \(y = 0.5\). This might slow down convergence to the optimum solution.
Secondly, the derivative of Sigmoid has a maximum output of \(\approx 0.25\) for \(x = 0\). This means that chaining gradients, as is done during neural network optimization, produces very small gradients for upstream layers. Very large neural networks experience this problem as the vanishing gradients problem, and it may slow down learning or even make it impossible.
Hence, for today's ML projects: it's perfectly fine to use Sigmoid, if you consider its limitations and know that possibly better activation functions are available.

Read more: ReLU, Sigmoid and Tanh: today’s most used activation functions
Tanh
Another commonly used activation function known and used since many years is the Tangens hyperbolicus, or Tanh activation function. It takes values from the entire domain and maps them onto the range \(y \in [-1, +1]\).
Even though it does provide symmetry around the origin, it's still sensitive to vanishing gradients. The next activation function was identified to counter this problem.

Read more: ReLU, Sigmoid and Tanh: today’s most used activation functions
Rectified Linear Unit (ReLU)
Perhaps the most widely known and used activation function today: the Rectified Linear Unit, or ReLU activation function. It activates as either \(x\) for all \(x > 0\), and as zero for all other values in the domain.
In terms of the derivative, this means that the gradient is either zero or one. This is both good and bad. It's good because models are sparse (all inputs \(x < 0\) are not taken into account) and because the vanishing gradients problem no longer occurs (for positive gradients, the gradient is always one).
It's bad because we're now opening ourselves to an entirely new problem: the dying ReLU problem. It may sometimes be the case that the sparsity-inducing effect of the zero activations for all negative inputs results in too many neurons that produce zeroes yet cannot recover. In other words, they "die off". This also produces models which can no longer successfully learn.
Nevertheless, ReLU is still the way to go in many cases these days.

Read more: ReLU, Sigmoid and Tanh: today’s most used activation functions
Leaky ReLU
Now onto some fixes for the dying ReLU problem. Leaky ReLU is the first: by means of a hyperparameter called \(\alpha\), the machine learning engineer can configure the outputs for the negative domain to be very small, but nonzero. This can be seen in the plot below.
As a result, the gradient for the negative domain is no longer zero, and the neurons no longer die off. This comes at the cost of non-sparse models, and does not always work (especially because you use simple models, it doesn't really work better than traditional ReLU in my experience), but empirical tests have shown quite some success in larger cases. Worth a try!

Read more: Using Leaky ReLU with Keras
Parametric ReLU (PReLU)
Leaky ReLU works with some \(\alpha\) that must be configured by the machine learning engineer. Generalizing from here, Parametric ReLU (or PReLU) takes this job from the engineer and puts it in the training process.
That is, it adds a few extra parameters to the neural network, which represent the alpha parameter (either one alpha per dimension of your data, or one alpha for all dimensions - this can be set by you). Optimization then determines the best alpha for your dataset and continuously adapts it based on training progress.
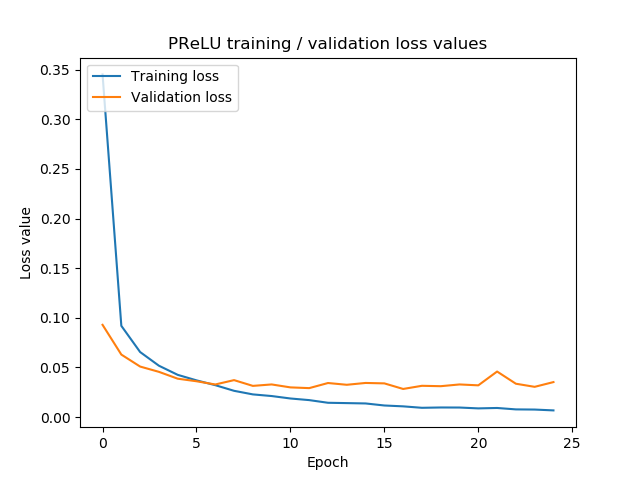
Read more: How to use PReLU with Keras?
ELU
The authors of the Exponential Linear Unit (ELU) activation function recognize that Leaky ReLU and PReLU contribute to resolving the issues with activation functions to quite a good extent. However, they argued, their fixes introduced a new issue: the fact that there is no "noise-deactivation state" and that by consequence, the models are not robust to noise.
What does this mean? Put very simply, the fact that the negative domain produces negative outputs means that for very large negative numbers, the outputs may still be considerable. This means that noise can still introduce disbalance into the model.
For this reason, the authors propose ELU: an activation function that looks like ReLU, has nonzero outputs for the negative domain, yet (together with its gradient) saturates to some value (which can be configured with an \(\alpha\) parameter), so that the model is protected from the impact of noise.

Read more: How to use ELU with Keras?
Softmax
Now something entirely different: from activation functions that are used on hidden layers, we'll move to an output activation function as a small intermezzo. Let's take a look at the Softmax activation function.
Softmax is quite widely used in classification, and especially when you're trying to solve a multiclass classification problem with categorical crossentropy loss. Softmax works very nicely and quite intuitively: by interrelating all the values in some vector, and converting them into numbers that adhere to the principles of probability theory, Softmax essentially computes a discrete probability distribution over the values in your vector. When these values represent the outputs of a neural network based classifier, you effectively compute a probability distribution over the target classes for each sample. This allows you to select a "most probable class" and has contributed to e.g. neural network based object detectors.
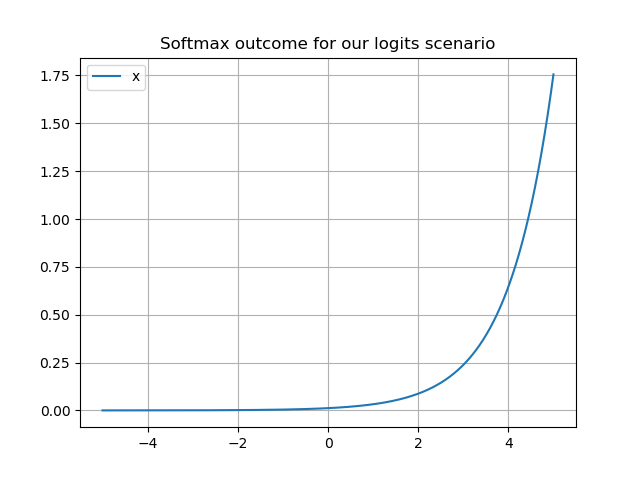
Read more: How does the Softmax activation function work?
Swish
Back to the ReLU-like activation functions. Another activation function which attempts to mimic ReLU is the Swish activation function, which was invented by a Google Brain team. It ensures both ReLU style activations for the positive domain, introduces smoothness around \(x \approx 0\), then also allows negative inputs close to the origin result in negative outputs, but saturates to \(y \approx 0\) for large negative inputs. Quite understandably, Swish has produced quite good results in the authors' empirical tests. However, it is more computationally intensive than say ReLU, which may impact the resources you need for training (Deep Learning University, 2020). It can also be unstable, impacting the training process. Therefore, proceed with caution.

Read more: Why Swish could perform better than ReLu
FTSwish
Another Swish style activation function is called Flatten-T Swish. Effectively combining the ReLU and Sigmoid activation functions into one, it attempts to resolve much of the issues related to traditional activation functions:

Read more:
LiSHT
Another activation function is LiSHT. It works in a different way when comparing it to more traditional activation functions: negative inputs are converted into positive outputs. However, in terms of the derivative, this produces negative gradients for negative inputs, which eventually saturate to zero. This may also be good for both model sparsity and training power. It might thus be worth a try!
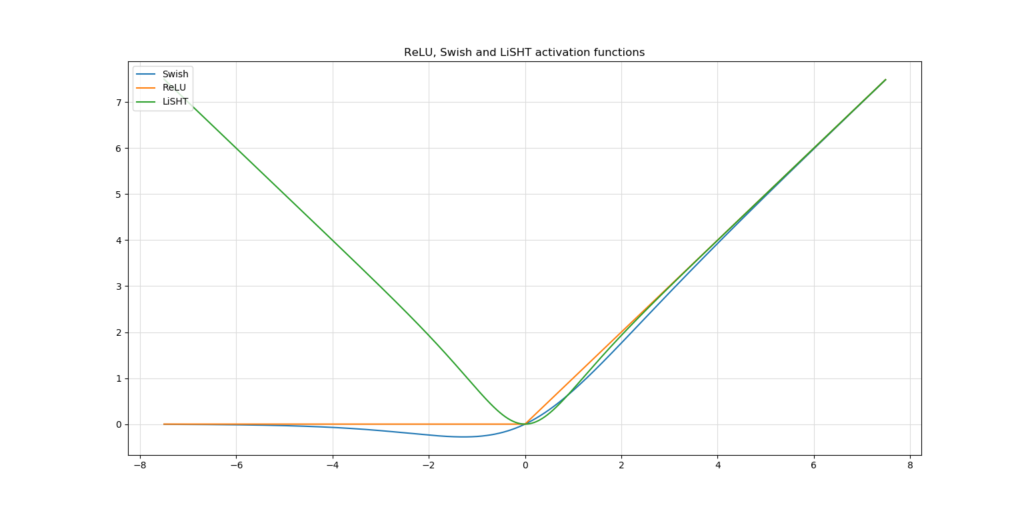
Read more:
Summary
In this blog post, you found an overview of commonly used activation functions and newer ones, which attempt to solve the problems related to these activation functions. Most notably, such problems are the vanishing gradients problem and the dying ReLU problem. For each activation function, we provided references to additional blog articles which study the activation function in more detail.
Please do note that in a fast-changing landscape like the ML one, this overview can never be complete. Therefore, if you know about a new activation function which must really be covered, please feel free to leave a comment in the comments section. I'll then try to add it as soon as possible. Please leave a comment too if you have any questions, or when you spot issues in this blog.
Thanks for reading MachineCurve today and happy engineering! 😎
References
Deep Learning University. (2020, June 8). Swish as an activation function in neural network. https://deeplearninguniversity.com/swish-as-an-activation-function-in-neural-network/

Hi, I'm Chris!
I know a thing or two about AI and machine learning. Welcome to MachineCurve.com, where machine learning is explained in gentle terms.
Getting started
Foundation models
Learn how large language models and other foundation models are working and how you can train open source ones yourself.
Keras
Keras is a high-level API for TensorFlow. It is one of the most popular deep learning frameworks.
Machine learning theory
Read about the fundamentals of machine learning, deep learning and artificial intelligence.
Most recent articles
January 2, 2024
What is Retrieval-Augmented Generation?
December 27, 2023
In-Context Learning: what it is and how it works
December 22, 2023
CLIP: how it works, how it's trained and how to use it
Article tags
Most popular articles
February 18, 2020
How to use K-fold Cross Validation with TensorFlow 2 and Keras?
December 28, 2020
Introduction to Transformers in Machine Learning
December 27, 2021
StyleGAN, a step-by-step introduction
July 17, 2019
This Person Does Not Exist - how does it work?
October 26, 2020
Your First Machine Learning Project with TensorFlow 2.0 and Keras
Connect on social media
Connect with me on LinkedIn
To get in touch with me, please connect with me on LinkedIn. Make sure to write me a message saying hi!
Side info
The content on this website is written for educational purposes. In writing the articles, I have attempted to be as correct and precise as possible. Should you find any errors, please let me know by creating an issue or pull request in this GitHub repository.
All text on this website written by me is copyrighted and may not be used without prior permission. Creating citations using content from this website is allowed if a reference is added, including an URL reference to the referenced article.
If you have any questions or remarks, feel free to get in touch.
TensorFlow, the TensorFlow logo and any related marks are trademarks of Google Inc.
PyTorch, the PyTorch logo and any related marks are trademarks of The Linux Foundation.
Montserrat and Source Sans are fonts licensed under the SIL Open Font License version 1.1.
Mathjax is licensed under the Apache License, Version 2.0.