Suppose that you have an image of a man with a moustache and one of a man without one. You feed them to a segment of a neural network that returns an approximation of the most important features that determine the image, once per image. You then smartly combine the two approximations into one, which you feed to another part of the same neural network...
...what do you see?
If you've trained the neural network well, there's a chance that the output is the man without moustache, but then with the other person's moustache.
Sounds great, doesn't it?

Popularity of VAEs in Google Trends.
Like GANs, Variational Autoencoders (VAEs) can be used for this purpose. Being an adaptation of classic autoencoders, which are used for dimensionality reduction and input denoising, VAEs are generative. Unlike the classic ones, with VAEs you can use what they've learnt in order to generate new samples. Blends of images, predictions of the next video frame, synthetic music - the list goes on.
..and on! VAEs have been rising in popularity over the last few years. Let's investigate them in more detail 😁
In this blog post, we'll take a generative view towards VAEs. Although strictly speaking, VAEs are autoencoders and can also be used for e.g. denoising, we already have posts about such applications - specifically for image denoising and signal denoising. Here, we'll focus on how to use VAEs for generative purposes.
This means first covering traditional (or, vanilla) autoencoders. What types do exist? And what are they used for? We'll see that they have very interesting applications. But we'll also find out what their limitations are. When your goal is to generate new content, it's difficult if not impossible to use these classic autoencoders. We'll also cover why this is the case.
We then introduce Variational Autoencoders. We'll cover what they are, and how they are different from traditional autoencoders. The two primary differences - that samples are encoded as two vectors that represent a probability distribution over the latent space rather than a point in latent space and that Kullback-Leibler divergence is added to optimization - will be covered in more detail. Through these, we'll see why VAEs are suitable for generating content.
As an extra, this blog also includes some examples of data generated with VAEs.
Are you ready?
Let's go! 😎
Update 08/Dec/2020: added references to PCA article.
About normal autoencoders
Before we can introduce Variational Autoencoders, it's wise to cover the general concepts behind autoencoders first. Those are valid for VAEs as well, but also for the vanilla autoencoders we talked about in the introduction.
At a high level, this is the architecture of an autoencoder:

It takes some data as input, encodes this input into an encoded (or latent) state and subsequently recreates the input, sometimes with slight differences (Jordan, 2018A).
Autoencoders have an encoder segment, which is the mapping between the input data and the encoded or latent state, and a decoder segment, which maps between latent state and the reconstructed output value.
Reconstructions may be the original images:

But autoencoders may also be used for noise reduction:

The fun thing about autoencoders is that the encoder and decoder segments are learnt, because neural networks are used to implement them. They are trained together with the other parts of the network. Usually, the networks as a whole use loss functions such as Mean Squared Error or Crossentropy loss (Shafkat, 2018). This way, autoencoders will be very data-specific. This is good news when you wish to have e.g. a tailor-made denoiser, but becomes challenging when you want to use the learnt encoding across various projects. In those cases, e.g. generalized denoising functions such as mean/median sample removal may be more suitable to your problem.
Let's now take a look at classic autoencoders in more detail and how they are used, so that we can understand why they are problematic if we want to generate new content.
Types of vanilla / traditional autoencoders
Jordan (2018B) defines multiple types of traditional autoencoders: among them, undercomplete autoencoders, sparse autoencoders and denoising autoencoders. Myself, I'd like to add convolutional autoencoders to this list, as well as recurrent autoencoders. They effectively extend undercomplete and sparse autoencoders by using convolutional or recurrent layers instead of Dense ones.
Undercomplete autoencoders involve creating an information bottleneck, by having hidden layers with many fewer neurons than the input and output layers. This way, the neural network is forced to compress much information in fewer dimensions (Jordan, 2018B) - exactly the goal of an autoencoder when generating the encoding.

Sparse autoencoders, on the other hand, do have an equal number of neurons in their hidden layers compared to input and output neurons, only not all of them are used or do contribute to the training process (Jordan, 2018B). Regularization techniques like L1 regularization or Dropout can serve this purpose, effectively creating the information bottleneck once more.

When using Denoising autoencoders, the goal is no longer to reconstruct the input data. Rather, your goal has become denoising the input data by learning the noise (Jordan, 2018B). This is achieved by adding noise to pure inputs, feeding them as samples, while having the original pure samples as targets. Minimizing reconstruction loss then involves learning noise. At MachineCurve, we have available examples for signal noise and image noise.

While traditionally densely-connected layers (or Dense layers) have been used for autoencoders, it's of course also possible to use convolutional or recurrent layers when creating them. The convolutional ones are useful when you're trying to work with image data or image-like data, while the recurrent ones can e.g. be used for discrete and sequential data such as text.
What are normal autoencoders used for?
There are two main applications for traditional autoencoders (Keras Blog, n.d.):
- Noise removal, as we've seen above.
- Dimensionality reduction. As the encoder segment learns representations of your input data with much lower dimensionality, the encoder segments of autoencoders are useful when you wish to perform dimensionality reduction. This can especially be handy when e.g. PCA doesn't work, but you suspect that nonlinear dimensionality reduction does (i.e. using neural networks with nonlinear activation functions).
You may now think: I have an idea! 💡 It goes as follows:
"Okay, my autoencoder learns to map inputs to an encoded representation (the latent state), which is subsequently re-converted into some output. Can't I generate new outputs, then, when I feeda randomly sampled encoded state to the decoder segment of my autoencoder?"
It's a good idea, because intuitively, the decoder must be capable of performing similar to the generator of a GAN when trained (Rocca, 2019).
But the answer is no 😥. Traditional autoencoders cannot be used for this. We'll now investigate why.
The Content Generation problem
Yes: generating new content with traditional autoencoders is quite challenging, if not impossible. This has to do with how classic autoencoders map their input to the latent space and how the encoded state is represented. If this seems like abracadabra to you - don't worry. I'll try to explain it in plainer English now 😀
How classic autoencoders map input to the latent space
To illustrate the point, I've trained a classic autoencoder where the encoded state has only 2 dimensions. This allows us to plot digits with Matplotlib. Do note that going from 784 to 2 dimensions is a substantial reduction and will likely lead to too much information loss than strictly necessary (indeed, the loss value stalled at around \(\approx 0.25\), while in a similar network a loss of \(\approx 0.09\) could be achieved).
The plot of our encoded space - or latent space - looks as follows. Each color represents a class:

Some classes (the zeroes and especially the ones) are discriminative enough in order to be mapped quite successfully. Others, such as nines, eights and sevens, are less discriminative. This explains the relatively high loss.
Continuity and completeness
However, let's go back to content generation. If we do wish to create new content, we really want our latent space to satisfy two criteria (Rocca, 2019):
- It must be continuous. This means that two close points in the latent space should give two similar outputs when decoded.
- It must be complete. This means that a point sampled from the distribution should produce an output that makes sense.
The thing with classic autoencoders is this: they're likely neither. Let's find out why.
Normal autoencoders don't work here
As an example: suppose that you train a classic autoencoder where your latent space has six dimensions. The encoder segment of the autoencoder will then output a vector with six values. In other words: it outputs a single value per dimension (Jordan, 2018A).
In the plot of our latent state space above - where we trained a classic autoencoder to encode a space of two dimensions - this would just be a dot somewhere on an (x, y) plane.
Does this plot, with all the dots, meet the criteria specified above?
No: it's neither continuous nor complete. Take a look at the plot and at what would happen if I would take a random position in my latent space, decode the output - generating a zero - and then start moving around.
If the space were continuous, it would mean that I'd find a value somewhere between a zero and a five (in terms of shape, not in terms of number!).
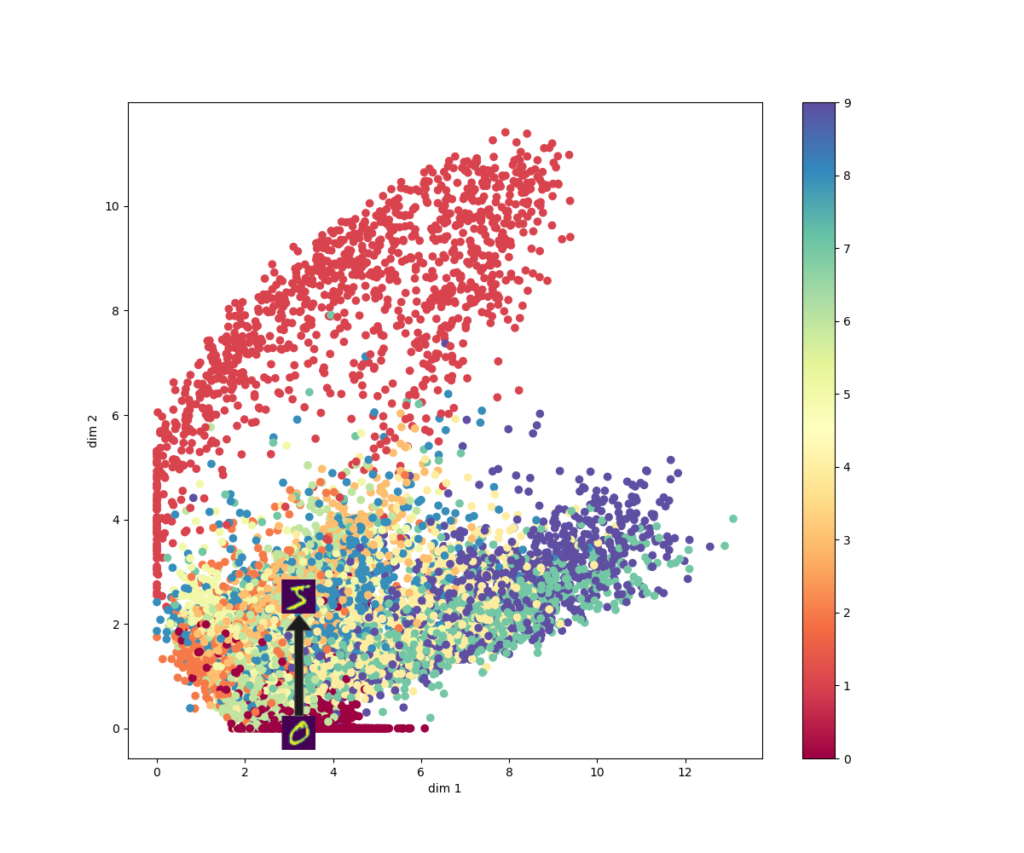
As you can see, however, I would find outputs like six, seven, one, two, ... anything but a five-ish output. The latent space of a classic autoencoder is hence not continuous.
But is it complete?

Nope, it's neither.
If I'd go back to my original sample, and moved around to a position that would decode as a one, I'd find a hole just beyond the halfway mark.
The decoder would likely produce utter nonsense here, since it simply hasn't seen anything similar to that particular encoding! (Rocca, 2019)
I hope it's clear now: the latent spaces of classic autoencoders are neither continuous nor complete. They don't produce similar outputs when changing the encoding over short distances in space, and the odds are there that they will produce nonsense when you'll feed encodings the model hasn't seen before. This is why traditional autoencoders cannot be used for content generation.
Why does this happen?
Funnily, the undesirable behavior of classic autoencoders with respect to content generation is perfectly explainable. It's because they were never trained to do so. They were trained to approximate the target output (i.e., the reconstructed input, or the denoised input, and so on) in the best way possible (Rocca, 2019).
In machine learning terms, this means that the only goal of the classic autoencoder is to minimize reconstruction loss. Minimizing reconstruction loss needs no continuity or completeness. Nope, it only needs learning a way of generating encodings for inputs that maximize reconstruction to the desired output. Whether this happens with or without a continuous and complete state, is of no concern to the autoencoder.
What's more, factors like the distribution of your training data, the dimension of the latent space configured by the machine learning engineer, and the architecture of your encoder - they all influence the regularity and hence continuity and completeness of your autoencoder's, and thus are factors in explaining why classic autoencoders cannot be used (Rocca, 2019).
To make a long story short: training an autoencoder that generates a latent space that is both continuous and complete locally (i.e., for some point in space and its direct vicinity) is difficult. Achieving the same but then globally (i.e., for the entire space) is close to impossible when using traditional autoencoders. Such a shame! 😑
Say hello to Variational Autoencoders (VAEs)!
Let's now take a look at a class of autoencoders that does work well with generative processes. It's the class of Variational Autoencoders, or VAEs. They are "powerful generative models" with "applications as diverse as generating fake human faces [or producing purely synthetic music]" (Shafkat, 2018). When comparing them with GANs, Variational Autoencoders are particularly useful when you wish to adapt your data rather than purely generating new data, due to their structure (Shafkat, 2018).
How are VAEs different from traditional autoencoders?

They achieve this through two main differences (Shafkat, 2018; Rocca, 2019; Jordan, 2018A):
- Firstly, recall that classic autoencoders output one value per dimension when mapping input data to latent state. VAEs don't do this: rather, they output a Gaussian probability distribution with some mean \(\mu\) and standard deviation \(\sigma\) for every dimension. For example, when the latent state space has seven dimensions, you'd thus get seven probability distributions that together represent state, as a probability distribution across space.
- Secondly, contrary to classic autoencoders - which minimize reconstruction loss only - VAEs minimize a combination of reconstruction loss and a probability comparison loss called Kullback-Leibler divergence. This enforces the regularization we so deeply need.
These two differences allow them to be both continuous and, quite often, complete, making VAEs candidates for generative processes.
Let's now take a look at these differences in more detail :)
First difference: encodings are probability distributions
Recall that classic autoencoders encode their inputs as a single point in some multidimensional space. Like this, for five-dimensional encoded space:

VAEs don't do this, and this is their first difference: yes, they still encode inputs to some multidimensional space, but they encode inputs as a distribution over the latent space (Rocca, 2019). As part of this, the encoder doesn't output one vector of size \(N\), but instead two vectors of size \(N\). The first is a vector of means, \(\mu\), and the second a vector of standard deviations, \(\sigma\).

The encoder segment of our VAE is what Kingma & Welling (2013) call the recognition model: it's a learnt approximation ("what must encoding \(z\) be given input \(x\)?") of the true posterior \(p(z | x)\). Since the approximation is learnt, we don't know its exact distribution, but we do know that the true posterior would be Gaussian, so that the \(z\) from our true posterior would be \(z \sim \mathcal{N}(\mu,\,\sigma^{2})\,\) ("z is part of a Gaussian a.k.a. normal distribution with mean \(\mu\) and standard deviation \(\sigma\)", Kingma & Welling 2013).
By consequence, we assume that the approximated posterior distribution (the distribution generated by the encoder) is also distributed \(\mathcal{N}(\mu,\,\sigma^{2})\,\). This, in return, means that we can effectively combine the two vectors into one, if we assume that each element in the new vector is a random variable \(X \sim \mathcal{N}(\mu,\,\sigma^{2})\,\) with the \(\mu\)s and \(\sigma\)s being the values from the vectors.
So:

When we know the encoding of our input, we can randomly sample from all the variables \(X\), selecting a number from the distribution with which the encoding was made. We then feed this number to the decoder, which decodes it into - hopefully 😀 - interpretable output (Shafkat, 2018).

The fact that we sample randomly means that what we feed to the decoder is different every time (i.e., at every epoch during training, and at every inference in production, Jordan 2018A). This means that the reconstructed output is slightly different every time (Shafkat, 2018).
It's important to understand this property, which is visualized below for a two-dimensional latent space with two Gaussian distributions (red and blue) generating a range of possible sampled \(X\)s (the area in green):

Even though this work is licensed under CC0, I'd wish to pay thanks to Wikipedia user 'BScan' for creating it: "Illustration of a multivariate gaussian distribution and its marginals."
As we can see, the mean values \(\mu\) for our distributions determine the average center of the range of values, while the \(\sigma\)s determine the area in green (Shafkat, 2018).
Now why is this difference - probability distributions instead of points - important? Let's explore.
Do you remember the two criteria that latent spaces must preferably satisfy if you wish to use autoencoders for generative processes? Indeed, they must be continuous and, preferably, complete.
If the space is continuous, two inputs to the decoder should produce similar results. If it's complete, all inputs in some area should produce results that make sense.
Having the VAE encoder output a probability distribution over the latent space ensures that it's continuous and (theoretically, with infinite iterations) complete over a local segment in the space. That is, for the samples in one class, or for only a few samples together. The illustration above clearly demonstrates this: within the green area, there's only a limited amount of space that is white. What's more, the results are similar: all the samples are drawn from the same probability distribution, which was generated as the encoding for just one sample.
Second difference: KL divergence + reconstruction error for optimization
Now imagine what happens when you feed dozens of samples (or, with the size of today's datasets, likely thousands or tens of thousands of samples) to the encoder. Given its learnt internals, it will produce a vector of means and standard deviations for each of them.
Now imagine that for each vector, we draw the variables \(X\) once, generating various points in the latent space. But now imagine that we do so an infinite amount of times, but without removing the earlier points. What you'll get is an area in space that becomes entirely filled, with only the bounds unfilled.
Why this happens is simple: the probability distributions that were encoded by the encoder overlap, and so do the points - especially when you don't stop sampling :-)
This is the benefit of the first difference, covered previously. But we're not there yet. Let's take a look at a visualization of a 2D latent space generated by a VAE that is trained to minimize reconstruction loss:
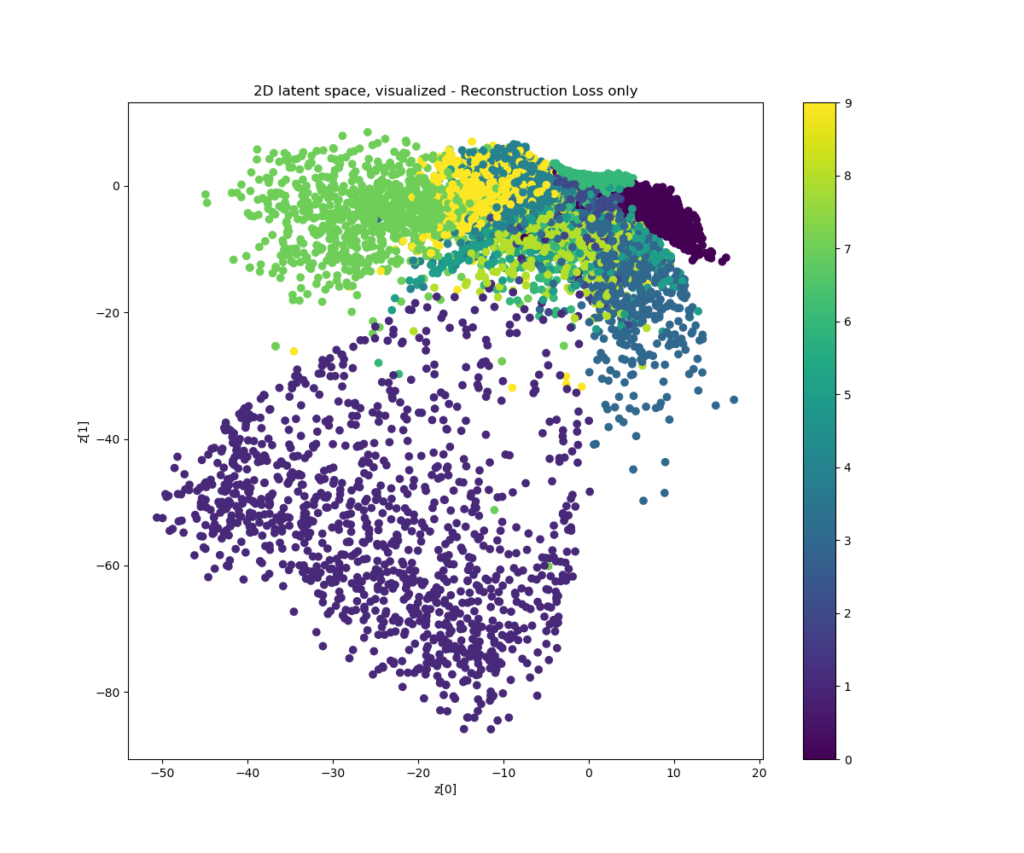
What I see is a distribution that is not centered, leaving many holes in between samples, where the decoder will not know how to decode the sampled point, producing nonsensical outputs.
What I see as well is that when moving across space (ignoring the nonsense data generated in the holes), the results produced are quite similar to each other. Take for example the zeroes generated at the top right of the diagram. Moving a bit to the left and to the top leaves us in the cluster with sixes, and yep: a 0 looks quite like a 6, in terms of shape. Zeroes and ones do not look like each other at all, and hey, they are located really far from each other! That's great 🎉
In terms of the principles: the latent spaces generated by VAEs trained to minimize reconstruction loss are continuous, but not complete.
This happens because the neural network has only been trained to minimize reconstruction loss so far.
Minimizing reconstruction loss in plain English goes like this: "make the output look like the input as much as possible - and take any chance you'll get". This ensures that the model will encode the latent space in a way that discriminates between classes, as much as possible (i.e., if it's not certain whether an input is a zero or a six, it will encode it to be somewhere in between. It will also move samples about which it is very certain as far away as possible, especially when encoding samples at the edges of input space).
Thus:
- Training with reconstruction loss clusters samples that look like each other together. This means that each class is clustered together and samples from different classes that look alike are encoded close to each other. Hence, the continuity principle is satisfied.
- However, there is no such thing that ensures that the clusters do overlap to some extent, having attachment to each other. In fact, it may be the case that in order to minimize reconstruction loss, the encoder will encode samples into disjoint clusters, i.e. clusters that have no overlap! By consequence, we must say that the completeness principle is still not satisfied.
Fortunately, there is a workaround: adding the Kullback-Leibler divergence to the loss function. This divergence, which is also called KL divergence, essentially computes the "divergence" between two probability distributions (i.e., how much they look not like each other).
If we add it to the loss function (currently with reconstruction loss only) to be minimized by the neural network, and configure it to compare the probability distribution generated by the encoder with the standard Gaussian \(\mathcal{N}(0, 1^{2})\,\), we get the following plot when retraining the model:

It's clear that continuity is still enforced: zeroes and ones are still on opposite sides of the latent space, while for example the values 6 and 8 are close together.
However, what also becomes visible is that the completeness principle is now also met to a great extent!
This happens because the KL divergence loss term increases when the probability distribution generated by the encoder diverges from the \(\mathcal{N}(0, 1^{2})\,\) standard normal distribution. Effectively, this means that the neural network is regularized to learn an encoder that produces a probability distribution with \(\mu \approx 0\) and \(\sigma \approx 1\), "pushing" the probability distributions and hence the sampled \(X\)s close together.
And this is visible in the illustration above: the entire latent space is built around the point \((0, 0)\) with the majority of samples being within the \([-1, +1]\) domain and range. There are much fewer holes now, making the global space much more complete.
Recap: why does this help content generation?
So, in short:
- VAEs learn encoders that produce probability distributions over the latent space instead of points in the latent space.
- As we sample from these probability distributions during many training iterations, we effectively show the decoder that the entire area around the distribution's mean produces outputs that are similar to the input value. In short, we create a continuous and complete latent space locally.
- By minimizing a loss function that is composed of both reconstruction loss and KL divergence loss, we ensure that the same principles also hold globally - at least to a maximum extent.
- This way, we have a continuous and complete latent space globally - i.e., for all our input samples, and by consequence also similar ones.
- This, in return, allows us to "walk" across the latent space, and generate input that both makes sense (thanks to completeness) and is similar to what we've seen already on our journey (thanks to the continuity).
Let's now take a walk 😂
Examples of VAE generated content
MNIST dataset
When training a VAE with the MNIST dataset, this is the latent space (on the left) and the result of selecting points in this space randomly on the right (Keras Blog, n.d.). Clearly, the latent space is continuous and complete, as the generated content shows.


The script to generate these plots was created by François Chollet and can be retrieved here.
Great! 😎
Fashion MNIST
With quite some easy changes (effectively replacing all references to mnist with fashion_mnist in the script mentioned above), one can replace the MNIST dataset with the Fashion MNIST dataset. This should be harder for the model, because the fashion items are less discriminative than the original MNIST samples. I feel that indeed, the plot of the latent space is a bit flurrier than the plot of the original MNIST dataset - but still, random decodings of points in the latent space show that it works! 🎉


The script to generate these plots was created by François Chollet and can be retrieved here.
Now, let's see if we can improve when we regularize even further.
As with the Dropout best practices, we applied Dropout with \(p = 0.5\) in the hidden layers and max-norm regularization with \(maxnormvalue = 2.0\). It seems to improve the model's ability to discriminate between classes, which also becomes clear from the samples across latent space:


{kind=link}
The script to generate these plots was created by François Chollet and can be retrieved here.
Summary
In this blog post, we've looked at the concept of a Variational Autoencoder, or VAE. We did so by looking at classic or 'normal' autoencoders first, as well as their difficulties when it comes to content generation.
Doing so, we have seen how VAEs may overcome these issues by encoding samples as a probability distribution over the latent space, making it continuous and complete - which allows generative processes to take place. We illustrated this with two examples, a visualization of the MNIST dataset and its latent space as well as the Fashion MNIST dataset. Clearly, the more discriminative - the MNIST - produced a better plot.
I hope you've learnt something today. If you like my blog, please leave a comment in the comments box below 👇 - I'd really appreciate it! Please do the same if you find mistakes or when you think things could be better. Based on your feedback, I'll try to improve my post where possible.
Thank you for reading MachineCurve today and happy engineering! 😎
References
Autoencoder. (2006, September 4). Retrieved from https://en.wikipedia.org/wiki/Autoencoder
Shafkat, I. (2018, April 5). Intuitively Understanding Variational Autoencoders. Retrieved from https://towardsdatascience.com/intuitively-understanding-variational-autoencoders-1bfe67eb5daf
Rocca, J. (2019, December 8). Understanding Variational Autoencoders (VAEs). Retrieved from https://towardsdatascience.com/understanding-variational-autoencoders-vaes-f70510919f73
Jordan, J. (2018A, July 16). Variational autoencoders. Retrieved from https://www.jeremyjordan.me/variational-autoencoders/
Jordan, J. (2018B, March 19). Introduction to autoencoders. Retrieved from https://www.jeremyjordan.me/autoencoders/
Keras Blog. (n.d.). Building Autoencoders in Keras. Retrieved from https://blog.keras.io/building-autoencoders-in-keras.html
Kingma, D. P., & Welling, M. (2013). Auto-encoding variational bayes. arXiv preprint arXiv:1312.6114.

Hi, I'm Chris!
I know a thing or two about AI and machine learning. Welcome to MachineCurve.com, where machine learning is explained in gentle terms.
Getting started
Foundation models
Learn how large language models and other foundation models are working and how you can train open source ones yourself.
Keras
Keras is a high-level API for TensorFlow. It is one of the most popular deep learning frameworks.
Machine learning theory
Read about the fundamentals of machine learning, deep learning and artificial intelligence.
Most recent articles
January 2, 2024
What is Retrieval-Augmented Generation?
December 27, 2023
In-Context Learning: what it is and how it works
December 22, 2023
CLIP: how it works, how it's trained and how to use it
Article tags
Most popular articles
February 18, 2020
How to use K-fold Cross Validation with TensorFlow 2 and Keras?
December 28, 2020
Introduction to Transformers in Machine Learning
December 27, 2021
StyleGAN, a step-by-step introduction
July 17, 2019
This Person Does Not Exist - how does it work?
October 26, 2020
Your First Machine Learning Project with TensorFlow 2.0 and Keras
Connect on social media
Connect with me on LinkedIn
To get in touch with me, please connect with me on LinkedIn. Make sure to write me a message saying hi!
Side info
The content on this website is written for educational purposes. In writing the articles, I have attempted to be as correct and precise as possible. Should you find any errors, please let me know by creating an issue or pull request in this GitHub repository.
All text on this website written by me is copyrighted and may not be used without prior permission. Creating citations using content from this website is allowed if a reference is added, including an URL reference to the referenced article.
If you have any questions or remarks, feel free to get in touch.
TensorFlow, the TensorFlow logo and any related marks are trademarks of Google Inc.
PyTorch, the PyTorch logo and any related marks are trademarks of The Linux Foundation.
Montserrat and Source Sans are fonts licensed under the SIL Open Font License version 1.1.
Mathjax is licensed under the Apache License, Version 2.0.