Linking maths and intuition: Rosenblatt's Perceptron in Python
July 23, 2019 by Chris
According to Wikipedia, Frank Rosenblatt is an "American psychologist notable in the field of artificial intelligence".
And notable, he is.
Rosenblatt is the inventor of the so-called Rosenblatt Perceptron, which is one of the first algorithms for supervised learning, invented in 1958 at the Cornell Aeronautical Laboratory.
The blogs I write on MachineCurve.com are educational in two ways. First, I use them to structure my thoughts on certain ML related topics. Second, if they help me, they could help others too. This blog is one of the best examples: it emerged from my struggle to identify why it is difficult to implement Rosenblatt's Perceptron with modern machine learning frameworks.
Turns out that has to do with the means of optimizing one's model - a.k.a. the Perceptron Learning Rule vs Stochastic Gradient Descent. I'm planning to dive into this question in detail in another blog. This article describes the work I preformed before being able to answer it - or, programming a Perceptron myself, understanding how it attempts to find the best decision boundary. It provides a tutorial for implementing the Rosenblatt Perceptron yourself.
I will first introduce the Perceptron in detail by discussing some of its history as well as its mathematical foundations. Subsequently, I will move on to the Perceptron Learning Rule, demonstrating how it improves over time. This is followed by a Python based Perceptron implementation that is finally demonstrated with a real dataset.
Of course, if you want to start working with the Perceptron right away, you can find example code for the Rosenblatt Perceptron in the first section.
If you run into questions during the read, or if you have any comments, please feel free to write a comment in the comment box near the bottom 👇 I'm happy to provide my thoughts and improve this post whenever I'm wrong. I hope to hear from you!
Update 13/Jan/2021: Made article up-to-date. Added quick example to answer question how to implement Rosenblatt Perceptron with Python? Performed changes to article structure. Added links to other articles. It's now ready for 2021!
Answer: implementing Rosenblatt Perceptron with Python
Some people just want to start with code before they read further. That's why in this section, you'll find a fully functional example of the Rosenblatt Perceptron, created with Python. It shows a class that is initialized, that has a training loop (train definition) and which can generate predictions once trained (through predict). If you want to understand the Perceptron in more detail, make sure to read the rest of this tutorial too!
import numpy as np
# Basic Rosenblatt Perceptron implementation
class RBPerceptron:
# Constructor
def __init__(self, number_of_epochs = 100, learning_rate = 0.1):
self.number_of_epochs = number_of_epochs
self.learning_rate = learning_rate
# Train perceptron
def train(self, X, D):
# Initialize weights vector with zeroes
num_features = X.shape[1]
self.w = np.zeros(num_features + 1)
# Perform the epochs
for i in range(self.number_of_epochs):
# For every combination of (X_i, D_i)
for sample, desired_outcome in zip(X, D):
# Generate prediction and compare with desired outcome
prediction = self.predict(sample)
difference = (desired_outcome - prediction)
# Compute weight update via Perceptron Learning Rule
weight_update = self.learning_rate * difference
self.w[1:] += weight_update * sample
self.w[0] += weight_update
return self
# Generate prediction
def predict(self, sample):
outcome = np.dot(sample, self.w[1:]) + self.w[0]
return np.where(outcome > 0, 1, 0)
A small introduction - what is a Perceptron?
A Perceptron is a binary classifier that was invented by Frank Rosenblatt in 1958, working on a research project for Cornell Aeronautical Laboratory that was US government funded. It was based on the recent advances with respect to mimicing the human brain, in particular the MCP architecture that was recently invented by McCulloch and Pitts.
This architecture attempted to mimic the way neurons operate in the brain: given certain inputs, they fire, and their firing behavior can change over time. By allowing the same to happen in an artificial neuron, researchers at the time argued, machines could become capable of approximating human intelligence.
...well, that was a slight overestimation, I'd say 😄 Nevertheless, the Perceptron lies at the basis of where we've come today. It's therefore a very interesting topic to study deeper. Next, I will therefore scrutinize its mathematical building blocks, before moving on to implementing one in Python.
Mathematical building blocks
When you train a supervised machine learning model, it must somehow capture the information that you're giving it. The Perceptron does this by means of a weights vector, or **w** that determines the exact position of the decision boundary and is learnt from the data.
If you input new data, say in an input vector **x**, you'll simply have to pinpoint this vector with respect to the learnt weights, to decide on the class.
Mathematically, this is represented as follows:
[mathjax]
\begin{equation} f(x) = \begin{cases} 1, & \text{if}\ \textbf{w}\cdot\textbf{x}+b > 0 \\ 0, & \text{otherwise} \\ \end{cases} \end{equation}
Here, you can see why it is a binary classifier: it simply determines the data to be part of class '0' or class '1'. This is done based on the output of the multiplication of the weights and input vectors, with a bias value added.
When you multiply two vectors, you're computing what is called a dot product. A dot product is the sum of the multiplications of the individual scalars in the vectors, pair-wise. This means that e.g. \(w_1x_1\) is computed and summated together with \(w_2x_2\), \(w_3x_3\) and so on ... until \(w_nx_n\). Mathematically:
\begin{equation} \begin{split} &z=\sum_{i=1}^{n} w_nx_n + b \\ &= w_1x_1 + ... + w_nx_n + b \\ \end{split} \end{equation}
When this output value is larger than 0, it's class 1, otherwise it's class 0. In other words: binary classification.
The Perceptron, visually
Visually, this looks as follows:
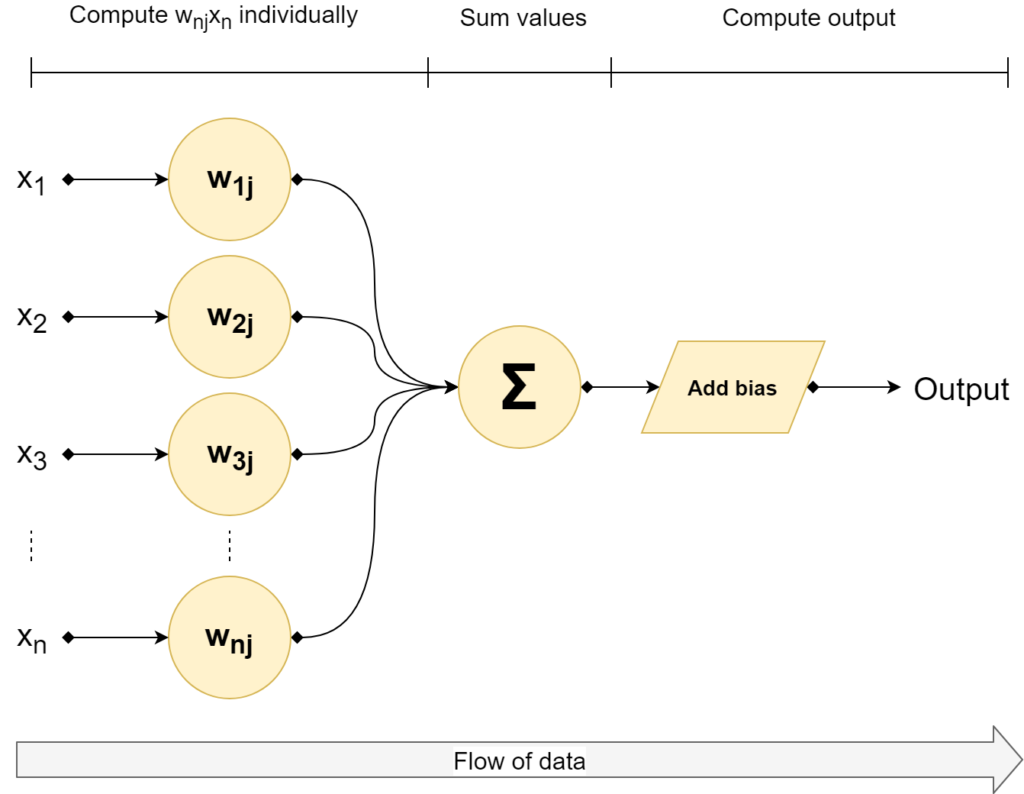
All right - we now have a mathematical structure for automatically deciding about the class. Weights vector **w** and bias value _b_ are used for setting the decision boundary. We did however not yet cover how the Perceptron is updated. Let's find out now!
Before optimizing: moving the bias into the weights vector
Rosenblatt did not only provide the model of the perceptron, but also the method for optimizing it.
This however requires that we first move the bias value into the weights vector.
This sounds strange, but it is actually a very elegant way of making the equation simpler.
As you recall, this is how the Perceptron can be defined mathematically:
\begin{equation} f(x) = \begin{cases} 1, & \text{if}\ \textbf{w}\cdot\textbf{x}+b > 0 \\ 0, & \text{otherwise} \\ \end{cases} \end{equation}
Of which \(\textbf{w}\cdot\textbf{x}+b\) could be written as:
\begin{equation} \begin{split} &z=\sum_{i=1}^{n} w_nx_n + b \\ &= w_1x_1 + ... + w_nx_n + b \\ \end{split} \end{equation}
We now add the bias to the weights vector as \(w_0\) and choose \(x_0 = 1\). This looks as follows:
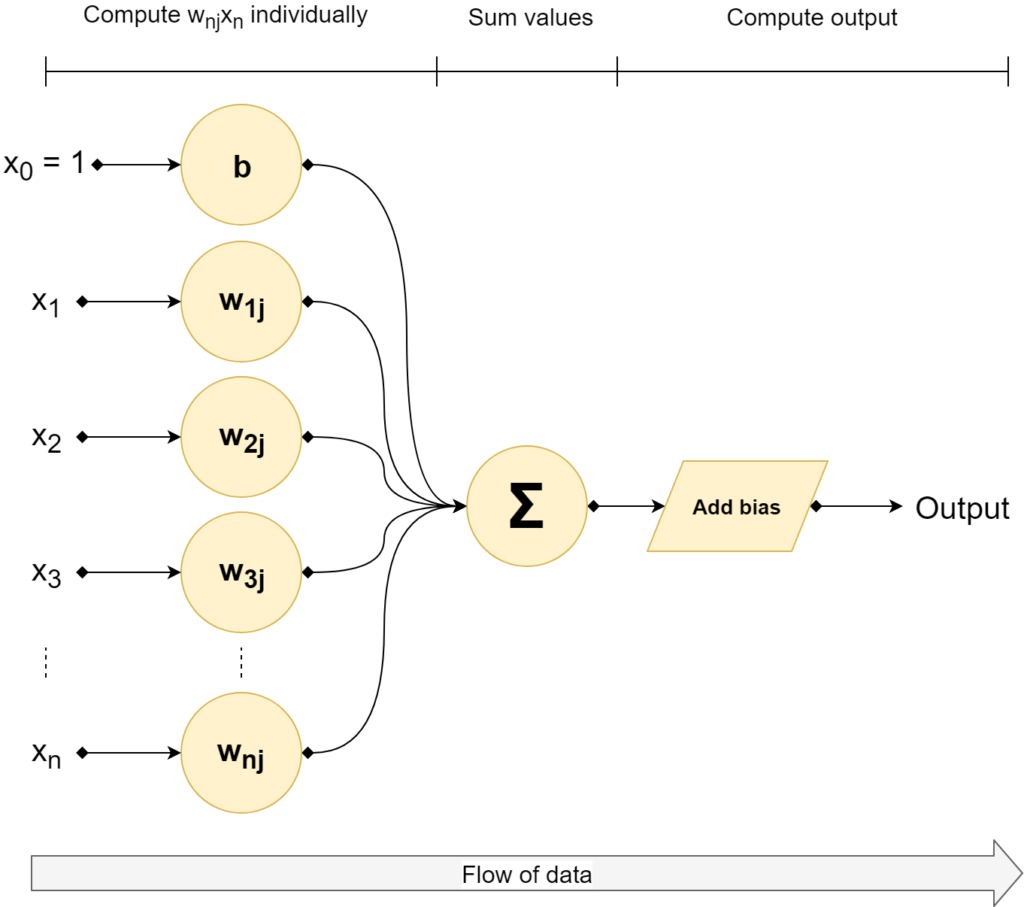
This allows us to rewrite \(z\) as follows - especially recall that \(w_0 = b\) and \(x_0 = 1\):
\begin{equation} \begin{split} & z = \sum_{i=0}^{n} w_nx_n \\ & = w_0x_0 + w_1x_1 + ... + w_nx_n \\ & = w_0x_0 + w_1x_1 + ... + w_nx_n \\ & = 1b + w_1x_1 + ... + w_nx_n \\ & = w_1x_1 + ... + w_nx_n + b \end{split} \end{equation}
As you can see, it is still equal to the original way of writing it:
\begin{equation} \begin{split} &z=\sum_{i=1}^{n} w_nx_n + b \\ &= w_1x_1 + ... + w_nx_n + b \\ \end{split} \end{equation}
This way, we got rid of the bias \(b\) in our main equation, which will greatly help us with what we'll do now: update the weights in order to optimize the model.
Training the model
We'll use what is called the Perceptron Learning Rule for that purpose. But first, we need to show you how the model is actually trained - by showing the pseudocode for the entire training process.
We'll have to make a couple assumptions at first:
- There is the weights vector
wwhich, at the beginning, is uninitialized. - You have a set of training values, such as \(T = \{ (x_1, d_1), (x_2, d_2), ..., (x_n, d_n) \}\). Here, \(x_n\) is a specific feature vector, while \(d_n\) is the corresponding target value.
- We ensure that \(w_0 = b\) and \(x_0 = 1\).
- We will have to configure a learning rate or \(r\), or by how much the model weights improve. This is a number between 0 and 1. We use \(r = 0.1\) in the Python code that follows next.
This is the pseudocode:
- Initialize the weights vector
**w**to zeroes or random numbers. - For every \((x_n, d_n)\) in \(D\):
- Compute the output value for the input vector \(x_n\). Mathematically, that's \(d'_n: f(x_n) = w_nx_n\).
- Compare the output value \(d'_n\) with target value \(d_n\).
- Update the weights according to the Perceptron Learning Rule: \(w_\text{n,i}(t+1) = w_\text{n,i}(t) + r \cdot (d_n - d'_n) \cdot x_\text{n,i}\) for all features (scalars) \(0 \leq i \leq|w_n|\).
Or, in plain English:
- First initialize the weights randomly or to zeroes.
- Iterate over every feature in the data set.
- Compute the output value.
- Compare if it matches, and 'push' the weights into the right direction (i.e. the \(d_n - d'_n\) part) slightly with respect to \(x_\text{n,i}\), as much as the learning rate \(r\) allows.
This means that the weights are updated for every sample from the dataset.
This process may be repeated until some criterion is reached, such as a specific number of errors, or - if you are adventurous - full convergence (i.e., the number of errors is 0).
Perceptron in Python
Now let's see if we can code a Perceptron in Python. Create a new folder and add a file named p.py. In it, let's first import numpy, which we'll need for some number crunching:
import numpy as np
We'll create a class that is named RBPerceptron, or Rosenblatt's Perceptron. Classes in Python have a specific structure: they must be defined as such (by using class) and can contain Python definitions which must be coupled to the class through self. Additionally, it may have a constructor definition, which in Python is called __init__.
Class definition and constructor
So let's code the class:
# Basic Rosenblatt Perceptron implementation
class RBPerceptron:
Next, we want to allow the engineer using our Perceptron to configure it before he or she starts the training process. We would like them to be able to configure two variables:
- The number of epochs, or rounds, before the model stops the training process.
- The learning rate \(r\), i.e. the determinant for the size of the weight updates.
We'll do that as follows:
# Constructor
def __init__(self, number_of_epochs = 100, learning_rate = 0.1):
self.number_of_epochs = number_of_epochs
self.learning_rate = learning_rate
The __init__ definition nicely has a self reference, but also two attributes: number_of_epochs and learning_rate. These are preconfigured, which means that if those values are not supplied, those values serve as default ones. By default, the model therefore trains for 100 epochs and has a default learning rate of 0.1
However, since the user can manually provide those, they must also be set. We need to use them globally: the number of epochs and the learning rate are important for the training process. By consequence, we cannot simply keep them in the context of our Python definition. Rather, we must add them to the instance variables of the class. This can be done by assigning them to the class through self.
The training definition
All right, the next part - the training definition:
# Train perceptron
def train(self, X, D):
# Initialize weights vector with zeroes
num_features = X.shape[1]
self.w = np.zeros(num_features + 1)
# Perform the epochs
for i in range(self.number_of_epochs):
# For every combination of (X_i, D_i)
for sample, desired_outcome in zip(X, D):
# Generate prediction and compare with desired outcome
prediction = self.predict(sample)
difference = (desired_outcome - prediction)
# Compute weight update via Perceptron Learning Rule
weight_update = self.learning_rate * difference
self.w[1:] += weight_update * sample
self.w[0] += weight_update
return self
The definition it self must once again have a self reference, which is provided. However, it also requires the engineer to pass two attributes: X, or the set of input samples \(x_1 ... x_n\), as well as D, which are their corresponding targets.
Within the definition, we first initialize the weights vector as discussed above. That is, we assign it with zeroes, and it is num_features + 1 long. This way, it can both capture the features \(x_1 ... x_n\) as well as the bias \(b\) which was assigned to \(x_0\).
Next, the training process. This starts by creating a for statement that simply ensures that the program iterates over the number_of_epochs that were configured by the user.
During one iteration, or epoch, every combination of \((x_i, d_i)\) is iterated over. In line with the pseudocode algorithm, a prediction is generated, the difference is computed, and the weights are updated accordingly.
After the training process has finished, the model itself is returned. This is not necessary, but is relatively convenient for later use by the ML engineer.
Generating predictions
Finally, the model must also be capable of generating predictions, i.e. computing the dot product \(\textbf{w}\cdot\textbf{x}\) (where \(b\) is included as \(w_0\)).
We do this relatively elegantly, thanks to another example of the Perceptron algorithm provided by Sebastian Raschka: we first compute the dot product for all weights except \(w_0\) and subsequently add this one as the bias weight. Most elegantly, however, is how the prediction is generated: with np.where. This allows an engineer to generate predictions for a batch of samples \(x_i\) at once. It looks as follows:
# Generate prediction
def predict(self, sample):
outcome = np.dot(sample, self.w[1:]) + self.w[0]
return np.where(outcome > 0, 1, 0)
Final code
All right - when integrated, this is our final code.
You can also check it out on GitHub.
import numpy as np
# Basic Rosenblatt Perceptron implementation
class RBPerceptron:
# Constructor
def __init__(self, number_of_epochs = 100, learning_rate = 0.1):
self.number_of_epochs = number_of_epochs
self.learning_rate = learning_rate
# Train perceptron
def train(self, X, D):
# Initialize weights vector with zeroes
num_features = X.shape[1]
self.w = np.zeros(num_features + 1)
# Perform the epochs
for i in range(self.number_of_epochs):
# For every combination of (X_i, D_i)
for sample, desired_outcome in zip(X, D):
# Generate prediction and compare with desired outcome
prediction = self.predict(sample)
difference = (desired_outcome - prediction)
# Compute weight update via Perceptron Learning Rule
weight_update = self.learning_rate * difference
self.w[1:] += weight_update * sample
self.w[0] += weight_update
return self
# Generate prediction
def predict(self, sample):
outcome = np.dot(sample, self.w[1:]) + self.w[0]
return np.where(outcome > 0, 1, 0)
Testing with a dataset
All right, let's now test our implementation of the Perceptron. For that, we'll need a dataset first. Let's generate one with Python. Go to the same folder as p.py and create a new one, e.g. dataset.py. Use this file for the next steps.
Generating the dataset
We'll first import numpy and generate 50 zeros and 50 ones.
We then combine them into the targets list, which is now 100 long.
We'll then use the normal distribution to generate two samples that do not overlap of both 50 samples.
Finally, we concatenate the samples into the list of input vectors X and set the desired targets D to the targets generated before.
# Import libraries
import numpy as np
# Generate target classes {0, 1}
zeros = np.zeros(50)
ones = zeros + 1
targets = np.concatenate((zeros, ones))
# Generate data
small = np.random.normal(5, 0.25, (50,2))
large = np.random.normal(6.5, 0.25, (50,2))
# Prepare input data
X = np.concatenate((small,large))
D = targets
Visualizing the dataset
It's always nice to get a feeling for the data you're working with, so let's first visualize the dataset:
import matplotlib.pyplot as plt
plt.scatter(small[:,0], small[:,1], color='blue')
plt.scatter(large[:,0], large[:,1], color='red')
plt.show()
It should look like this:
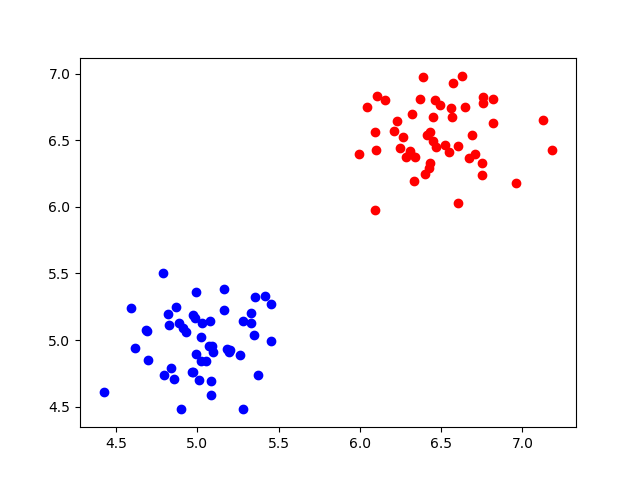
Let's next train our Perceptron with the entire training set X and the corresponding desired targets D.
We must first initialize our Perceptron for this purpose:
from p import RBPerceptron
rbp = RBPerceptron(600, 0.1)
Note that we use 600 epochs and set a learning rate of 0.1. Let's now train our model:
trained_model = rbp.train(X, D)
The training process should be completed relatively quickly. We can now visualize the Perceptron and its decision boundary with a library called mlxtend - once again the credits for using this library go out to Sebastian Raschka.
If you don't have it already, install it first by means of pip install mlxtend.
Subsequently, add this code:
from mlxtend.plotting import plot_decision_regions
plot_decision_regions(X, D.astype(np.integer), clf=trained_model)
plt.title('Perceptron')
plt.xlabel('X1')
plt.ylabel('X2')
plt.show()
You should now see the same data with the Perceptron decision boundary successfully separating the two classes:
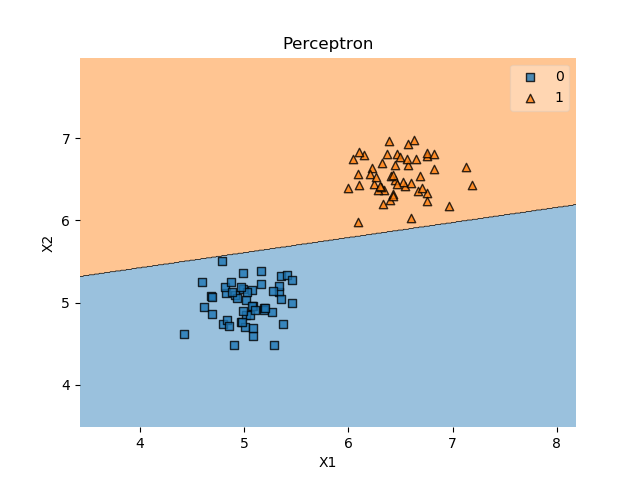
There you go, Rosenblatt's Perceptron in Python!
References
Bernard (2018, December). Align equation left. Retrieved from https://tex.stackexchange.com/questions/145657/align-equation-left
Raschka, S. (2015, March 24). Single-Layer Neural Networks and Gradient Descent. Retrieved from https://sebastianraschka.com/Articles/2015_singlelayer_neurons.html#artificial-neurons-and-the-mcculloch-pitts-model
Perceptron. (2003, January 22). Retrieved from https://en.wikipedia.org/wiki/Perceptron#Learning_algorithm

Hi, I'm Chris!
I know a thing or two about AI and machine learning. Welcome to MachineCurve.com, where machine learning is explained in gentle terms.
Getting started
Foundation models
Learn how large language models and other foundation models are working and how you can train open source ones yourself.
Keras
Keras is a high-level API for TensorFlow. It is one of the most popular deep learning frameworks.
Machine learning theory
Read about the fundamentals of machine learning, deep learning and artificial intelligence.
Most recent articles
January 2, 2024
What is Retrieval-Augmented Generation?
December 27, 2023
In-Context Learning: what it is and how it works
December 22, 2023
CLIP: how it works, how it's trained and how to use it
Article tags
Most popular articles
February 18, 2020
How to use K-fold Cross Validation with TensorFlow 2 and Keras?
December 28, 2020
Introduction to Transformers in Machine Learning
December 27, 2021
StyleGAN, a step-by-step introduction
July 17, 2019
This Person Does Not Exist - how does it work?
October 26, 2020
Your First Machine Learning Project with TensorFlow 2.0 and Keras
Connect on social media
Connect with me on LinkedIn
To get in touch with me, please connect with me on LinkedIn. Make sure to write me a message saying hi!
Side info
The content on this website is written for educational purposes. In writing the articles, I have attempted to be as correct and precise as possible. Should you find any errors, please let me know by creating an issue or pull request in this GitHub repository.
All text on this website written by me is copyrighted and may not be used without prior permission. Creating citations using content from this website is allowed if a reference is added, including an URL reference to the referenced article.
If you have any questions or remarks, feel free to get in touch.
TensorFlow, the TensorFlow logo and any related marks are trademarks of Google Inc.
PyTorch, the PyTorch logo and any related marks are trademarks of The Linux Foundation.
Montserrat and Source Sans are fonts licensed under the SIL Open Font License version 1.1.
Mathjax is licensed under the Apache License, Version 2.0.