Recently, I've picked up deep learning both in my professional and spare-time activities. This means that I spent a lot of time learning the general concepts behind this very hot field. On this website, I'm documenting the process for others to repeat.
But in order to start, you'll have to start with the definition. What is deep learning, exactly? If you don't know what it is, you cannot deepen your understanding.
In this blog, I thus investigate the definition of deep learning in more detail. I'll take a look at the multi-layered information processing, the nonlinear activation functions, as well as the concept behind representation learning. It's slightly high-level to keep this blog at an adequate complexity, and I will cover the particular topics in more detail in other blogs.
So keep coming back every now and then to find new information available for you to read, free of charge! :-)
Hopefully, this blog will put you into the right direction in your quest for information. If you have any questions or remarks, tips and tricks; obviously, they are welcome. Please leave me a message below and I am more than happy to respond.
Okay, let's give it a start :-)
Update February 2020 - Extended certain areas of the text and added additional links to other MachineCurve articles.
What is deep learning, exactly?
There seems to be a bit of a definition clash, haha. In all these years, there has been no agreed upon definition about what the differences are between artificial intelligence, machine learning and deep learning. Especially for artificial intelligence things get vague with very fuzzy boundaries.
For deep learning, things tend to get a bit better.
If we quote Wikipedia's page about deep learning, it writes as follows: "Deep learning (also known as deep structured learning or hierarchical learning) is part of a broader family of machine learning methods based on learning data representations, as opposed to task-specific algorithms."
We now have a couple of new questions:
- What does learning data representations mean?
- How are they different than tasks-specific algorithms?
The book 'Deep Learning Methods and Applications' by Li Deng and Dong Yu provides a synthesis of various definitions based on previous academic research. They highlight that within all these definitions, overlap exists between two key concepts:
- Deep learning models are models consisting of multiple layers or stages of nonlinear information processing;
- Deep learning methods are methods for supervised or unsupervised learning of feature representation at successively higher, more abstract layers.
This somewhat deepens our understanding from the Wikipedia quote, but we still have some remaining questions.
- Once again, what does learning data representation or feature representation mean?
- How can we visualize the successively higher, more abstract layers?
- What is nonlinear information processing?
We now have a problem space which we can use to move forward :-)
Multiple layers of information processing
Classic methods of machine learning work with just one layer of information processing.
To make this principle clear, we take one of the simpler variants of these kind of models: a linear classifier.
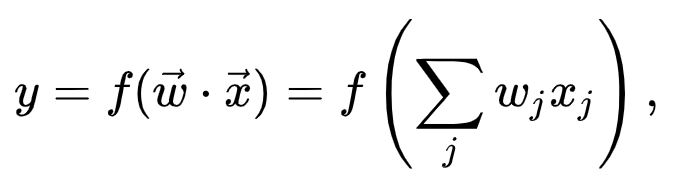
Above, we have the mathematical notation of a linear classifier. I'll now try to explain it more intuitively.
Input, output and weights
Suppose that we have a model. This means that you will have input which you feed to the model, and based on the model you get some output. In the notation above, vector (for programmers, this is like an array; for anyone else, it is like an ordered list) x is the new input you're feeding the model. y is the output, for example the class in a classification problem.
Vector w is called the weights vector. This is the "learnt" knowledge for the model. If you train the model, you feed it "input values" with the corresponding "output value". Based on the way the model is built up itself, it attempts to discover patterns in this data. For example, a medium-sized animal which makes a barking sound probably belongs to output... dog. This means that if trained well, when your input vector (x) consists of 'medium-sized' and 'barking', the model's output (y) will be 'dog'.
Converting input to output: linear classifier
In the case of a linear classifier, it works by converting the dot product of the weights and the input vector scalars into the desired output value. It's simply a summated multiplication of the two vector's scalars at the same levels in the vector. This is a situation in which a linear function is used to produce the output.
We can use this to demonstrate how a deep learning network is different than a classic machine learning method.
If you wish to use the classic method, like the linear classifier above, you feed it with input and you get some output. However, only one thing happens. This means that the information is processed just once. In the case of the linear classifier, a dot product between the model's weights and the input scalars is calculated... and that provides the output score.
For the deep learning methods, things are a bit different. If we wish to demonstrate this, we must take a generic neural network and show it first:
[caption id="attachment_172" align="aligncenter" width="296"]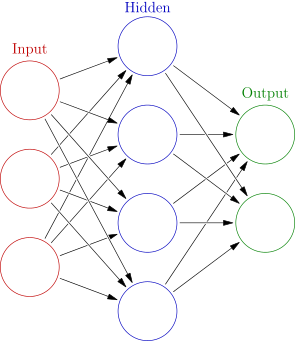 Source: Colored neural network at Wikipedia, author: Glosser.ca, license: CC BY-SA 3.0, no changes.[/caption]
Source: Colored neural network at Wikipedia, author: Glosser.ca, license: CC BY-SA 3.0, no changes.[/caption]
{kind=link}
I think you did immediately notice that an artificial neural network consists of multiple layers :-) There is one input layer, one output layer and some hidden layers in between.
These layers, and the nodes within these layers, they are all connected. In most cases, this happens in a feed-forward fashion, as you can notice in the image above, but some network architectures exist in which certain information from the past is used to make better predictions in future layers.
Converting input to output: neural network
In both cases, this means that multiple things happen when you feed a neural network new input data. This is very much contrary to the linear classifier and all the other classic machine learning methods, in which this is not the case.
Now you may ask: why is this better than classic machine learning methods?
The simple answer to this question is: it is not necessarily better. This totally depends on the task. But we have seen that these kind of network architectures do generally perform better when comparing them to the classic models.
And here's why.
Nonlinear activation functions
We'll have to first look into another aspect of these kind of models: the so-called nonlinear activation functions.
We will have to go back to the simple principle of calculating a dot product again. In a short recap, this means to calculate the dot product of both the weights vector and the input vector.
Quite frankly, the same thing happens in a neuron, which is the node illustrated in the neural network above.
Activation functions
But neural networks are slightly inspired on how the human brain works. Neurology research used in the development of artificial neural networks tells us that the brain is a collective cooperation between neurons, which process information and 'fire' a signal to other neurons if they wish to process information.
This means that the neurons can partially decide that certain signals do not need to be processed further down the chain, whereas for others this is actually important.
It can be achieved by using an activation function. One such function uses some kind of threshold value to decide whether activation should take place. For example, "fire if value > threshold, otherwise do not fire". In numbers: "1 if value > threshold, 0 otherwise". Many types of activation function exist.
Nonlinearity
This is really different from a regular model, which does not use any kind of activation function, as we saw with the linear classifier.
In neural networks, activation functions are nonlinear. We can show the difference by first explaining a linear function:
y: A(x) = c * x.
With a certain weight c (which does not matter for the example), function A produces output value y for the input value x. However, as we can see, this output value is proportional to the input value. If c = 1, we can see that A(1) = 1, A(2) = 2 et cetera.
Nonlinear functions do not work this way. Their input is not necessarily proportional to the input value (but may be for some ranges within the possible input values). For example, one of the most-used nonlinear activation functions is the so-called ReLu activation function. If the x values are < 0, the output is 0, else the output is x. This means that for x >= 0, the output is proportional to the input, but if an input scalar x is < 0, it is not proportional.
So, in nonlinear models, the weighted product calculated by the neuron is then put through an activation function that is nonlinear. Its output, if activated, is sent to the connected neurons in the subsequent layer.
Differences with classic models
The benefit of these kind of activation functions is that data can be handled in a better way. Data is inherently nonlinear, as the world is too. It is therefore very complex to fully grasp the world in linear models. Nonlinear activation functions can help identifying much more complex patterns in data than a linear model can handle. This partially explains the enormous rise in accuracy for machine learning models since the rise of deep learning.
Back to the multiple layers
Now that we know how nonlinear activation functions are an integral part of deep learning, we can go back to the multiple layers story with which we ended prior to reaching a conclusion.
Every layer adds a level of non-linearity that cannot be captured by another layer.
For example, suppose that we wish to identify all the data points that lie within the red circle and the orange circle in the diagram below:
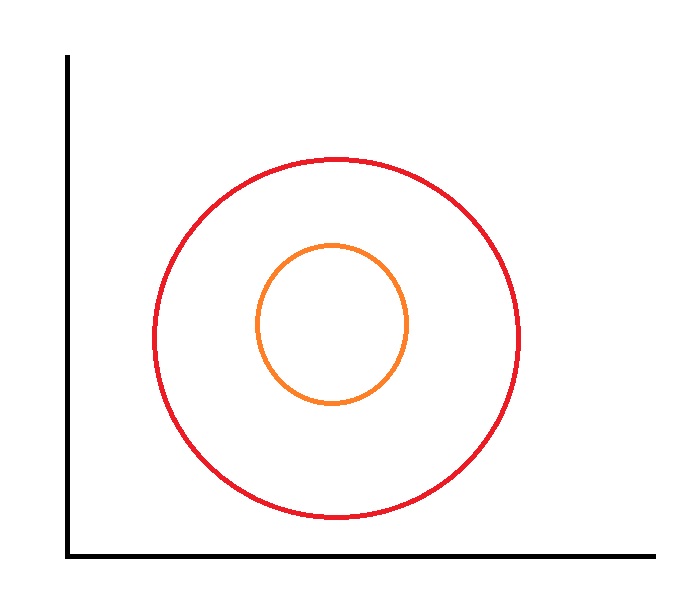
We first greatly benefit from the nonlinearity of the neural networks, because these circles are not linear (have you seen a circular line before?).
With traditional models, it would have been impossible to achieve great accuracy on this kind of problem.
Partially because the linearity of these models, but also because it cannot separate the two problems presented hidden in the problem described above:
- First, identify everything that lies within the red circle;
- Second, identify everything that lies outside the orange circle.
Combined, these provide the answer to our problem.
Using a multi-layered neural network, we can train the model to make this separation. One layer will take the first problem; the second layer will take onto itself the second problem. Probably, a few additional layers are necessary to "polish" the result, but it illustrates why multiple layers of information processing distinguish deep learning methods from classic machine learning methods, as well as the nonlinearity.
Learning data / feature representation
Another important aspect of these deep learning networks is that they perform learning data representation. It is also one of the answers to the sketch drawn above, in which the data is not linearly separable.
Internally, every layer will learn its own representation of the data. This means that it will structure the data in a better way so the task at hand, for example classification, becomes simpler.
This also means that the data will be more abstract and more high-level for every subsequent layer. It is an essential stap in transforming the very dynamic, often heterogenous data into something for which a computer can distinguish that - for example - it's either A or B.
In a concrete example for image recognition in humans, this means that every input image is converted into higher-level concepts. For example, the noses of the various humans involved in the pictures are transformed into a generic nose, and subsequently decomposed in many other simpler, generic concepts.
This way, once the model sees a new nose, it can attempt to do the same thing - to know that it's a nose, and therefore possibly a human being :-)
Conclusion
In this blog I investigated the definition for deep learning in more detail. I hope it helped you in some way towards becoming better in machine learning and deep learning. I would appreciate your comment and your feedback, especially if you think I made a mistake. This way, we can cooperatively make this blog better, which I would appreciate very much :-)
Sources

Hi, I'm Chris!
I know a thing or two about AI and machine learning. Welcome to MachineCurve.com, where machine learning is explained in gentle terms.
Getting started
Foundation models
Learn how large language models and other foundation models are working and how you can train open source ones yourself.
Keras
Keras is a high-level API for TensorFlow. It is one of the most popular deep learning frameworks.
Machine learning theory
Read about the fundamentals of machine learning, deep learning and artificial intelligence.
Most recent articles
January 2, 2024
What is Retrieval-Augmented Generation?
December 27, 2023
In-Context Learning: what it is and how it works
December 22, 2023
CLIP: how it works, how it's trained and how to use it
Article tags
Most popular articles
February 18, 2020
How to use K-fold Cross Validation with TensorFlow 2 and Keras?
December 28, 2020
Introduction to Transformers in Machine Learning
December 27, 2021
StyleGAN, a step-by-step introduction
July 17, 2019
This Person Does Not Exist - how does it work?
October 26, 2020
Your First Machine Learning Project with TensorFlow 2.0 and Keras
Connect on social media
Connect with me on LinkedIn
To get in touch with me, please connect with me on LinkedIn. Make sure to write me a message saying hi!
Side info
The content on this website is written for educational purposes. In writing the articles, I have attempted to be as correct and precise as possible. Should you find any errors, please let me know by creating an issue or pull request in this GitHub repository.
All text on this website written by me is copyrighted and may not be used without prior permission. Creating citations using content from this website is allowed if a reference is added, including an URL reference to the referenced article.
If you have any questions or remarks, feel free to get in touch.
TensorFlow, the TensorFlow logo and any related marks are trademarks of Google Inc.
PyTorch, the PyTorch logo and any related marks are trademarks of The Linux Foundation.
Montserrat and Source Sans are fonts licensed under the SIL Open Font License version 1.1.
Mathjax is licensed under the Apache License, Version 2.0.